Official statement
Other statements from this video 20 ▾
- □ Why can't Google ever guarantee that your users will land on the right language version of your site?
- □ Are automatic redirects really killing your international SEO rankings?
- □ Should you really block JavaScript execution for SPAs with server-side rendering?
- □ Should you really tag foreign words with the lang attribute for SEO purposes?
- □ Does duplicate content really trigger a Google penalty?
- □ Does Google really respect rel=canonical or is it just a suggestion that gets ignored?
- □ Are FAQs in blog articles really worth it for SEO rankings?
- □ Is hreflang really essential for managing a successful international website?
- □ Does Google's web cache actually affect your search rankings?
- □ How does Google really customize search results based on location and language? Here's what actually happens behind the scenes
- □ Do you really need to stick to just one topic on your site to rank well?
- □ How many links can you really put on a page without triggering a Google penalty?
- □ Does the referrer URL in Search Console really affect your search rankings?
- □ Does word count really matter for SEO ranking?
- □ Should you worry about reusing the same text blocks across multiple pages?
- □ Does Google really accept machine-translated content on multilingual websites?
- □ Does blocking URLs with robots.txt but leaving them indexed really hurt your SEO?
- □ Do you really need to duplicate the Organization schema on every page of your website?
- □ Can self-hosted reviews display star ratings in Google search results for local businesses?
- □ Why do website mergers produce unpredictable results in Google's eyes?
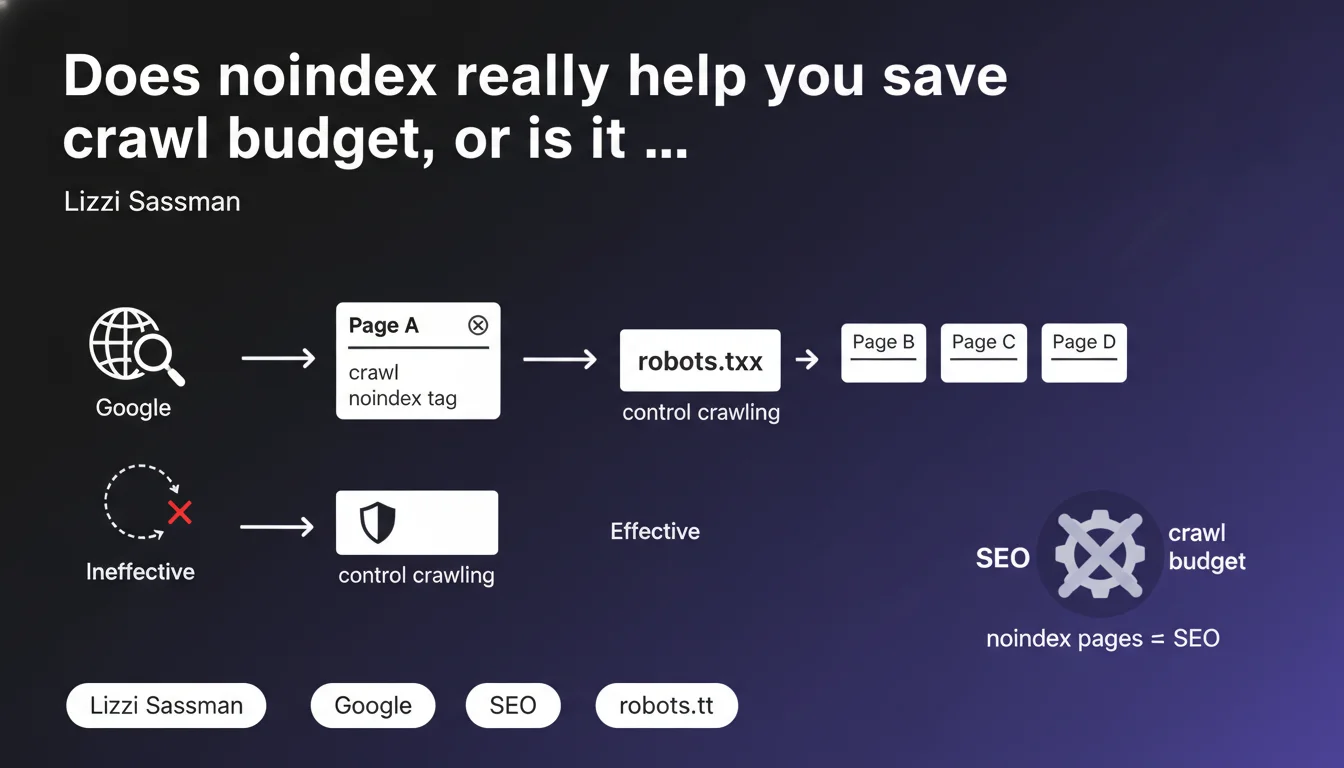
Google crawls pages to detect the noindex directive — using it to save crawl budget is therefore counterproductive. Only robots.txt truly blocks crawling. The number of noindex pages does not impact your site's overall SEO quality.
What you need to understand
Why can't noindex save you crawl budget?
The mechanism is straightforward: for a search engine to discover the noindex directive, it must first crawl the page, load the HTML (or check HTTP headers if it's an X-Robots-Tag), then identify the instruction. The crawl has already happened.
If the goal is to preserve crawl resources — for example on a site with millions of pages or dynamically generated sections — adding noindex only increases processing overhead: Googlebot visits, reads, temporarily indexes, then removes the page from the index. In short, it's inefficient.
What's the difference between noindex and robots.txt for crawling?
robots.txt blocks crawling upstream. Googlebot checks this file before visiting a URL and, if it's forbidden, it doesn't crawl it at all. No HTTP request, no budget consumption.
Noindex, on the other hand, acts after crawling, at the indexation level. The page is visited, analyzed, but won't appear in search results. Two different logics, two different stages of the pipeline.
Does the number of noindex pages penalize your site's overall SEO?
According to this statement, no. Google affirms that the volume of pages marked noindex does not affect the perceived quality of the site as a whole. What matters is the relevance and quality of indexable pages, not the number of excluded pages.
This contradicts a persistent belief: that too many noindex pages would send a negative signal ("this site is hiding quality issues"). [To verify] on very large-scale sites — but the official position is clear.
- Noindex does not block crawling, it blocks indexation after crawling
- robots.txt is the only lever to control crawl budget upstream
- The number of noindex pages is not a penalty factor according to Google
- Using noindex to save crawl budget is a technical contradiction
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, broadly speaking. On sites with constrained crawl budget (multi-SKU e-commerce, marketplaces, massive editorial media), blocking via robots.txt is much more effective than hoping noindex will lighten the load.
That said, the notion of "crawl budget" itself is often overstated. Google has repeated it: for most sites, it's not a bottleneck. The real issue is the quality of crawled pages, not their absolute quantity.
In what cases does noindex remain relevant?
Noindex retains its full value for managing indexation, not crawling. Internal search results pages, product sheets in permanent stockout, obsolete content worth keeping for user history — these are all cases where you want Google to crawl (to follow links, detect updates), but without indexing.
The trap is conflating the two objectives. If you want Googlebot to never touch a section (admin files, technical appendices, sensitive PDFs), robots.txt is the right approach. If you want it to explore but not display in the SERP, noindex does the job.
What nuance should be added about the volume of noindex pages?
Google says it doesn't affect overall SEO. Technically accurate — but watch out for indirect effects. If the majority of your site is noindex, it raises a real strategic question: why create so much non-indexable content?
An overly high ratio of noindex pages can reveal structural problems: uncontrolled duplication, automatic generation of low-value pages, poor architecture. It's not the volume of noindex that penalizes you, it's what it signals. [To verify] on extreme cases (90% noindex pages), but the logic holds.
Practical impact and recommendations
What should you do concretely to optimize crawl budget?
If you really want to control what Googlebot crawls, use robots.txt strategically. Identify sections that consume resources without delivering SEO value: infinite facets, combinatorial filters, archives of obsolete pages.
Then monitor via Search Console the crawl volume by page type. Google reports the number of requests per day, average response time, server errors. If these metrics are healthy, you probably don't have a crawl budget problem.
What errors should you avoid with noindex and robots.txt?
Classic mistake: blocking a URL in robots.txt AND adding noindex. Google can't crawl, so it never sees the noindex directive — result, the page can remain in the index with a truncated snippet ("No information available"). You must choose: either block crawling, or block indexation, rarely both.
Another trap: using noindex on strategic pages out of fear of duplication. If the content is legitimate and useful, use canonical instead of noindex. Noindex removes all ranking chances, canonical concentrates signals.
How do you verify that your site is configured correctly?
Start with a crawl audit (Screaming Frog, OnCrawl, Botify) to identify noindex pages and their volume. Cross-reference with server logs to see if Googlebot visits them frequently despite the noindex.
Next, compare with robots.txt: are there blocked sections that should be crawled to transmit PageRank? Are there noindex pages that could be blocked upstream via robots.txt to lighten the load?
- Use robots.txt to block crawling of non-strategic sections (facets, filters, archives)
- Reserve noindex for pages you want crawled but not indexed (internal search, temporary content)
- Never combine robots.txt and noindex on the same URL
- Regularly audit the ratio of indexable pages to total pages to detect inconsistencies
- Monitor crawl metrics in Search Console (requests per day, errors, response time)
- Prefer canonical to noindex for managing legitimate duplication
❓ Frequently Asked Questions
Peut-on combiner robots.txt et noindex sur la même page ?
Le noindex transmet-il du PageRank via les liens internes ?
Un trop grand nombre de pages noindex peut-il pénaliser un site ?
Quand utiliser robots.txt plutôt que noindex ?
Comment savoir si mon site souffre d'un problème de budget de crawl ?
🎥 From the same video 20
Other SEO insights extracted from this same Google Search Central video · published on 21/10/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.