Official statement
Other statements from this video 14 ▾
- □ Google choisit-il vraiment les titres de page indépendamment de la requête de l'utilisateur ?
- □ Changer un nom de ville suffit-il à créer des doorway pages condamnables par Google ?
- □ Faut-il vraiment centraliser son contenu compétitif plutôt que le dupliquer ?
- □ Pourquoi Google refuse-t-il d'indexer un site techniquement parfait ?
- □ Faut-il vraiment faire confiance aux recommandations de vos outils SEO ?
- □ Faut-il encore corriger les redirections cassées longtemps après une migration ?
- □ Passer d'un ccTLD à un gTLD suffit-il pour conquérir de nouveaux marchés internationaux ?
- □ Sous-domaine ou sous-répertoire : Google a-t-il vraiment une préférence ?
- □ Pourquoi les clics par page et par requête diffèrent-ils dans Search Console ?
- □ Les erreurs de données structurées bloquent-elles vraiment l'indexation de vos pages ?
- □ Le maillage interne révèle-t-il vraiment l'importance de vos pages à Google ?
- □ L'attribut target des liens a-t-il un impact sur le référencement Google ?
- □ Faut-il vraiment supprimer tous les breadcrumbs schema sauf un pour éviter la confusion ?
- □ Pourquoi vos images CSS background-image sont-elles invisibles pour Google Images ?
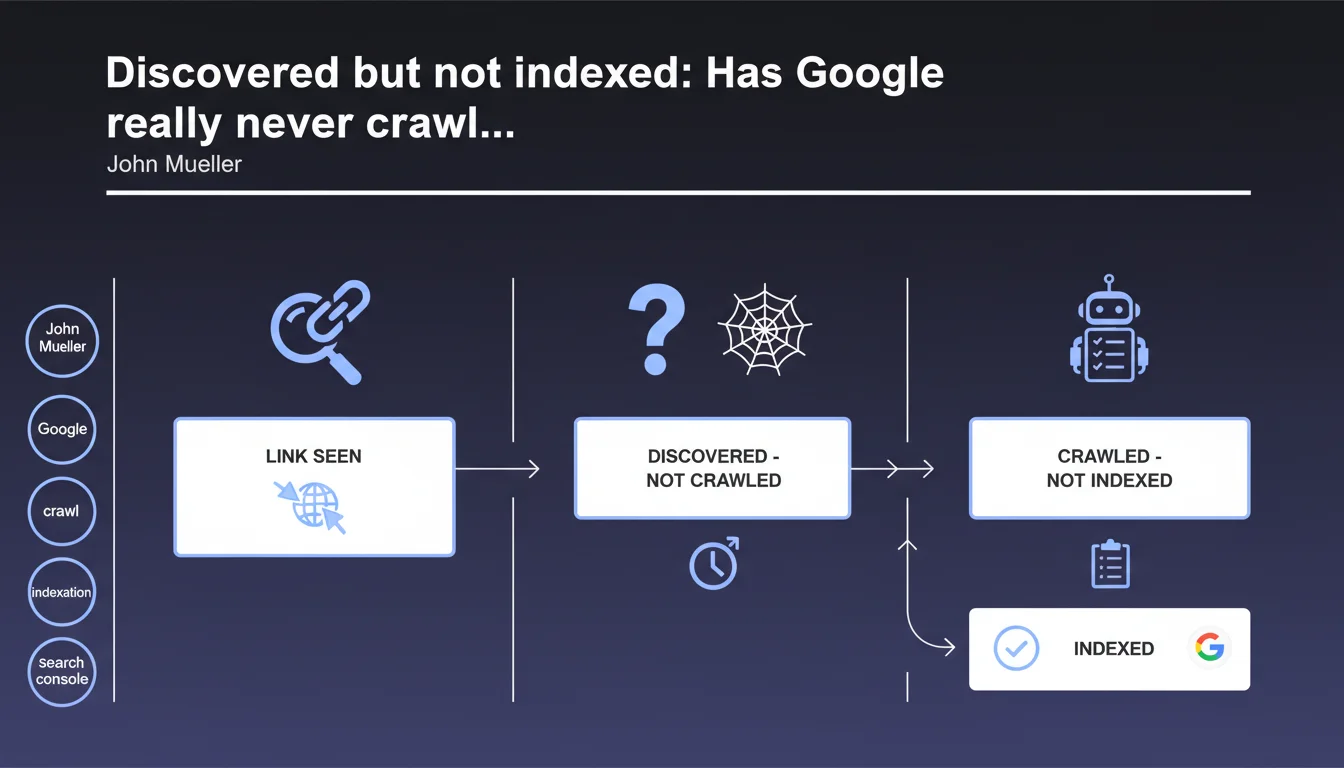
According to John Mueller, the 'discovered - currently not indexed' status means that Google has only seen a link to the page but has never actually crawled it. The normal progression would then be to 'crawled - not indexed' before potential indexation. This clarification challenges the common understanding of crawl budget and the indexation cycle.
What you need to understand
The 'discovered - currently not indexed' status appears frequently in Search Console and often generates confusion and concern among SEO practitioners. Mueller's statement brings important technical clarification about what this status really means in Google's indexation pipeline.
Contrary to what many assume, this status does not signal an indexation refusal but simply a discovery without exploration. The page exists in Google's queue, nothing more.
What is the real difference between 'discovered' and 'crawled'?
Google clearly distinguishes two stages: discovery via a link (internal or external) and the actual crawling of the page. A URL can remain in 'discovered' status for days, weeks or even months without ever being visited by Googlebot.
The transition to 'crawled - not indexed' indicates that the robot has actually visited the page, downloaded its content, but decided not to index it for various reasons (quality, duplication, limited resources). This is a distinct and important step in the process.
Why do some pages stay stuck in 'discovered' status?
The crawl budget is the main reason. Google allocates a limited quota of resources to each site, and certain URLs deemed less of a priority can stagnate indefinitely in the queue.
Other factors come into play: page depth in the site structure, site update frequency, overall domain quality, and popularity signals. An orphaned or semi-orphaned page has little chance of being crawled quickly.
- The 'discovered' status = link detected, page not visited
- The 'crawled - not indexed' status = page visited but rejected
- The transition from one to the other is neither automatic nor guaranteed
- Thousands of pages can remain in 'discovered' status on large sites
- This status often reveals crawl budget or architecture issues
Does this clarification change our understanding of the indexation pipeline?
Absolutely. Many SEO professionals considered 'discovered' as a first level of analysis by Google, assuming the robot had at least superficially scanned the page. Mueller confirms that is not the case — no crawling has occurred.
This distinction has direct implications for diagnosis: if your strategic pages remain in 'discovered' status, the problem is not their quality or content (Google doesn't know them), but their accessibility and priority in your architecture. You need to review your internal linking and crawl budget allocation.
SEO Expert opinion
Is this statement consistent with field observations?
Yes, and it finally explains certain anomalies observed. Many sites with thousands of pages in 'discovered' status notice that these URLs generate no trace in server logs — Googlebot has never visited them.
The progression 'discovered' → 'crawled - not indexed' → 'indexed' does indeed correspond to what we observe on well-monitored sites. The problem is timing: some pages can remain in the first stage for months.
What nuances should be added to this statement?
Mueller simplifies a process that may be more complex. [To verify]: does Google really perform no preliminary evaluation before complete crawling? Some evidence suggests that light pre-crawling might exist to prioritize the queue.
Another unclear point: the 'normal' duration between discovery and crawl. Mueller provides no time indicator. On a high-performing site with good crawl budget, it can take a few hours. On an average site, several weeks are not unusual. But when does it become problematic? No official data.
In what cases does this progression not apply?
Pages submitted via XML sitemap can sometimes skip the 'discovered' status or stay there very briefly. Google generally gives them higher priority, especially if the site has a good track record.
Pages with strong signals (quality backlinks, external mentions) can also be crawled very quickly after discovery. The pipeline is not strictly linear for all URLs — prioritization occurs at each stage.
Practical impact and recommendations
What should you do concretely if strategic pages remain in 'discovered' status?
First action: verify your internal linking. If an important page is only accessible after 5-6 clicks from the homepage, or via hidden footer links, it will probably remain in limbo. Bring it closer to the surface of your site.
Second lever: the XML sitemap. Explicitly submit these URLs via Search Console. It doesn't guarantee anything, but it significantly increases their chances of being crawled quickly.
Third option: generate freshness signals. Update the content, add new internal links pointing to these pages, get some external mentions. Google regularly reassesses its crawl priorities.
What mistakes should you avoid when facing this status?
Don't panic immediately. Hundreds or thousands of pages in 'discovered' status are not necessarily a problem if they are low-priority URLs (old archives, rarely-used tags, deep pagination pages).
Avoid over-optimizing crawl budget at the expense of user navigation. Massively blocking sections via robots.txt might seem like a solution, but it often complicates content discovery for users and can create other problems.
Don't systematically request manual indexation via Search Console for each page in 'discovered' status. It doesn't work at scale and Google may interpret it as spam if you abuse it.
- Identify strategic pages stuck in 'discovered' status for more than a month
- Check their accessibility: number of clicks from homepage, presence in sitemap
- Strengthen internal linking to these pages from already well-crawled areas
- Monitor server logs to confirm the complete absence of Googlebot visits
- Use the URL inspection tool to force a one-time crawl attempt
- Evaluate if your overall crawl budget is poorly allocated (too many unnecessary pages crawled)
- Consider an architecture overhaul if the problem is massive and structural
The 'discovered - currently not indexed' status is not a condemnation but simply a prioritization issue. Google sees the link, but hasn't deemed it worthwhile to visit the page. The solution lies in optimizing your internal architecture and improving relevance signals.
If you notice that hundreds of strategic pages remain blocked despite your efforts, or if optimizing crawl budget seems complex to manage alone, engaging an SEO-specialized agency may prove worthwhile. An in-depth technical audit and personalized architecture strategy often help quickly unblock these situations.
❓ Frequently Asked Questions
Combien de temps une page peut-elle rester en 'discovered' avant d'être crawlée ?
Est-ce grave si des milliers de pages sont en 'discovered - currently not indexed' ?
Soumettre une URL via Search Console force-t-il Google à la crawler ?
Une page en 'discovered' peut-elle passer directement en 'indexed' sans être 'crawled - not indexed' ?
Le robots.txt peut-il empêcher une page de passer de 'discovered' à 'crawled' ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 22/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.