Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Google choisit-il vraiment les titres de page indépendamment de la requête de l'utilisateur ?
- □ Changer un nom de ville suffit-il à créer des doorway pages condamnables par Google ?
- □ Faut-il vraiment centraliser son contenu compétitif plutôt que le dupliquer ?
- □ Pourquoi Google refuse-t-il d'indexer un site techniquement parfait ?
- □ Faut-il vraiment faire confiance aux recommandations de vos outils SEO ?
- □ Faut-il encore corriger les redirections cassées longtemps après une migration ?
- □ Passer d'un ccTLD à un gTLD suffit-il pour conquérir de nouveaux marchés internationaux ?
- □ Sous-domaine ou sous-répertoire : Google a-t-il vraiment une préférence ?
- □ Pourquoi les clics par page et par requête diffèrent-ils dans Search Console ?
- □ Les erreurs de données structurées bloquent-elles vraiment l'indexation de vos pages ?
- □ Le maillage interne révèle-t-il vraiment l'importance de vos pages à Google ?
- □ L'attribut target des liens a-t-il un impact sur le référencement Google ?
- □ Faut-il vraiment supprimer tous les breadcrumbs schema sauf un pour éviter la confusion ?
- □ Pourquoi vos images CSS background-image sont-elles invisibles pour Google Images ?
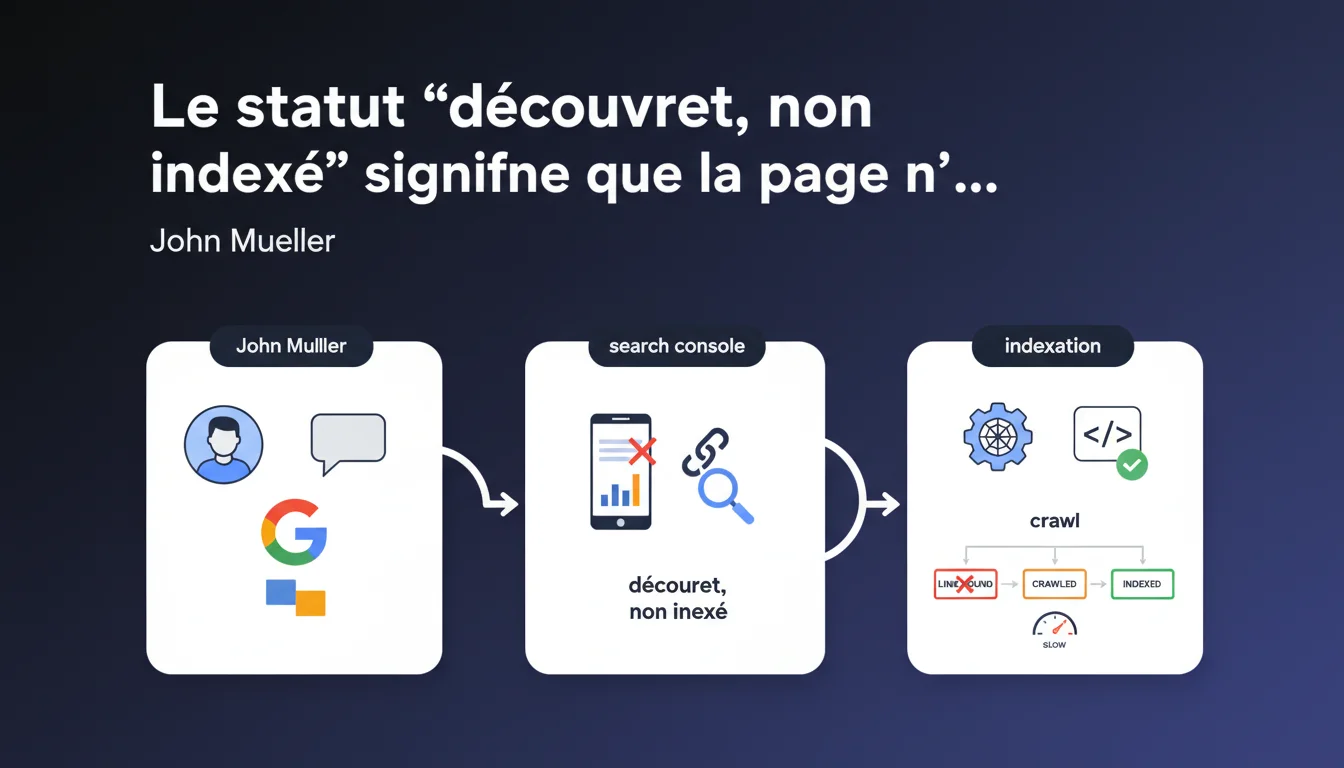
Selon John Mueller, le statut 'discovered - currently not indexed' signifie que Google a uniquement vu un lien vers la page mais ne l'a jamais réellement crawlée. La progression normale serait ensuite vers 'crawled - not indexed' avant une éventuelle indexation. Cette précision remet en question la compréhension commune du crawl budget et du cycle d'indexation.
Ce qu'il faut comprendre
Le statut 'discovered - currently not indexed' apparaît fréquemment dans Search Console et génère souvent confusion et inquiétude chez les praticiens SEO. La déclaration de Mueller apporte une clarification technique importante sur ce que ce statut signifie réellement dans le pipeline d'indexation de Google.
Contrairement à ce que beaucoup supposent, ce statut ne signale pas un refus d'indexation mais une simple découverte sans exploration. La page existe dans la file d'attente de Google, rien de plus.
Quelle est la différence réelle entre 'discovered' et 'crawled' ?
Google distingue clairement deux étapes : la découverte via un lien (internal ou externe) et le crawl effectif de la page. Une URL peut rester en statut 'discovered' pendant des jours, semaines voire mois sans jamais être visitée par Googlebot.
Le passage à 'crawled - not indexed' indique que le robot a effectivement visité la page, téléchargé son contenu, mais décidé de ne pas l'indexer pour diverses raisons (qualité, duplication, ressources limitées). C'est une étape distincte et importante du processus.
Pourquoi certaines pages restent-elles bloquées en 'discovered' ?
Le crawl budget est la raison principale. Google alloue un quota de ressources limité à chaque site, et certaines URLs jugées moins prioritaires peuvent stagner indéfiniment dans la file d'attente.
D'autres facteurs entrent en jeu : la profondeur de la page dans l'arborescence, la fréquence de mise à jour du site, la qualité globale du domaine, et les signaux de popularité. Une page orpheline ou quasi-orpheline a peu de chances d'être crawlée rapidement.
- Le statut 'discovered' = lien détecté, page non visitée
- Le statut 'crawled - not indexed' = page visitée mais rejetée
- Le passage de l'un à l'autre n'est ni automatique ni garanti
- Des milliers de pages peuvent rester en 'discovered' sur des sites volumineux
- Ce statut révèle souvent des problèmes de crawl budget ou d'architecture
Cette clarification change-t-elle notre compréhension du pipeline d'indexation ?
Absolument. Beaucoup de SEO considéraient 'discovered' comme un premier niveau d'analyse par Google, supposant que le robot avait au minimum parcouru superficiellement la page. Mueller confirme que non — aucun crawl n'a eu lieu.
Cette distinction a des implications directes sur le diagnostic : si vos pages stratégiques restent en 'discovered', le problème n'est pas leur qualité ou leur contenu (Google ne les connaît pas), mais leur accessibilité et priorité dans votre architecture. Il faut revoir le maillage interne et l'allocation du crawl budget.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et elle explique enfin certaines anomalies constatées. De nombreux sites avec des milliers de pages en 'discovered' constatent que ces URLs ne génèrent aucune trace dans les logs serveur — Googlebot ne les a jamais visitées.
La progression 'discovered' → 'crawled - not indexed' → 'indexed' correspond effectivement à ce qu'on observe sur des sites bien monitorés. Le problème, c'est le temps : certaines pages peuvent rester des mois au premier stade.
Quelles nuances faut-il apporter à cette affirmation ?
Mueller simplifie un processus qui peut être plus complexe. [A vérifier] : est-ce que Google ne fait vraiment aucune évaluation préliminaire avant le crawl complet ? Certains indices suggèrent qu'un pré-crawl léger pourrait exister pour prioriser la file d'attente.
Autre point flou : la durée « normale » entre découverte et crawl. Mueller ne donne aucun indicateur temporel. Sur un site performant avec un bon crawl budget, ça peut prendre quelques heures. Sur un site moyen, plusieurs semaines ne sont pas anormales. Mais quand devient-ce problématique ? Aucune donnée officielle.
Dans quels cas cette progression ne s'applique-t-elle pas ?
Les pages soumises via sitemap XML peuvent parfois sauter le statut 'discovered' ou y rester très peu de temps. Google leur accorde généralement une priorité supérieure, surtout si le site a un bon historique.
Les pages avec des signaux forts (backlinks de qualité, mentions externes) peuvent également être crawlées très rapidement après découverte. Le pipeline n'est pas strictement linéaire pour toutes les URLs — la priorisation joue à chaque étape.
Impact pratique et recommandations
Que faire concrètement si des pages stratégiques restent en 'discovered' ?
Première action : vérifier le maillage interne. Si une page importante n'est accessible qu'après 5-6 clics depuis la home, ou via des liens en footer cachés, elle restera probablement dans les limbes. Rapprochez-la de la surface du site.
Deuxième levier : le sitemap XML. Soumettez explicitement ces URLs via Search Console. Ça ne garantit rien, mais ça augmente significativement leurs chances d'être crawlées rapidement.
Troisième option : générer des signaux de fraîcheur. Mettez à jour le contenu, ajoutez de nouveaux liens internes pointant vers ces pages, obtenez quelques mentions externes. Google réévalue régulièrement ses priorités de crawl.
Quelles erreurs éviter face à ce statut ?
Ne paniquez pas immédiatement. Des centaines ou milliers de pages en 'discovered' ne sont pas forcément un problème si ce sont des URLs de faible priorité (archives anciennes, tags peu utilisés, pages de pagination profonde).
Évitez de sur-optimiser le crawl budget au détriment de la navigation utilisateur. Bloquer massivement des sections via robots.txt peut sembler une solution, mais ça complique souvent la découverte de contenu par les utilisateurs et peut générer d'autres problèmes.
Ne demandez pas systématiquement l'indexation manuelle via Search Console pour chaque page en 'discovered'. Ça ne fonctionne pas à grande échelle et Google peut interpréter ça comme du spam si vous en abusez.
- Identifiez les pages stratégiques bloquées en 'discovered' depuis plus d'un mois
- Vérifiez leur accessibilité : nombre de clics depuis la home, présence dans le sitemap
- Renforcez le maillage interne vers ces pages depuis des zones déjà bien crawlées
- Surveillez les logs serveur pour confirmer l'absence totale de passage de Googlebot
- Utilisez l'outil d'inspection d'URL pour forcer une tentative de crawl ponctuelle
- Évaluez si votre crawl budget global est mal alloué (trop de pages inutiles crawlées)
- Considérez une refonte d'architecture si le problème est massif et structurel
Le statut 'discovered - currently not indexed' n'est pas une condamnation mais un simple problème de priorisation. Google voit le lien, mais n'a pas jugé utile de visiter la page. La solution passe par l'optimisation de l'architecture interne et l'amélioration des signaux de pertinence.
Si vous constatez que des centaines de pages stratégiques restent bloquées malgré vos efforts, ou si l'optimisation du crawl budget vous semble complexe à orchestrer seul, l'accompagnement d'une agence SEO spécialisée peut s'avérer judicieux. Un audit technique approfondi et une stratégie d'architecture personnalisée permettent souvent de débloquer rapidement ces situations.
❓ Questions frequentes
Combien de temps une page peut-elle rester en 'discovered' avant d'être crawlée ?
Est-ce grave si des milliers de pages sont en 'discovered - currently not indexed' ?
Soumettre une URL via Search Console force-t-il Google à la crawler ?
Une page en 'discovered' peut-elle passer directement en 'indexed' sans être 'crawled - not indexed' ?
Le robots.txt peut-il empêcher une page de passer de 'discovered' à 'crawled' ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.