Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Google choisit-il vraiment les titres de page indépendamment de la requête de l'utilisateur ?
- □ Changer un nom de ville suffit-il à créer des doorway pages condamnables par Google ?
- □ Faut-il vraiment centraliser son contenu compétitif plutôt que le dupliquer ?
- □ Découvert mais non indexé : Google n'a-t-il vraiment jamais crawlé ces pages ?
- □ Pourquoi Google refuse-t-il d'indexer un site techniquement parfait ?
- □ Faut-il vraiment faire confiance aux recommandations de vos outils SEO ?
- □ Faut-il encore corriger les redirections cassées longtemps après une migration ?
- □ Passer d'un ccTLD à un gTLD suffit-il pour conquérir de nouveaux marchés internationaux ?
- □ Sous-domaine ou sous-répertoire : Google a-t-il vraiment une préférence ?
- □ Pourquoi les clics par page et par requête diffèrent-ils dans Search Console ?
- □ Les erreurs de données structurées bloquent-elles vraiment l'indexation de vos pages ?
- □ Le maillage interne révèle-t-il vraiment l'importance de vos pages à Google ?
- □ Faut-il vraiment supprimer tous les breadcrumbs schema sauf un pour éviter la confusion ?
- □ Pourquoi vos images CSS background-image sont-elles invisibles pour Google Images ?
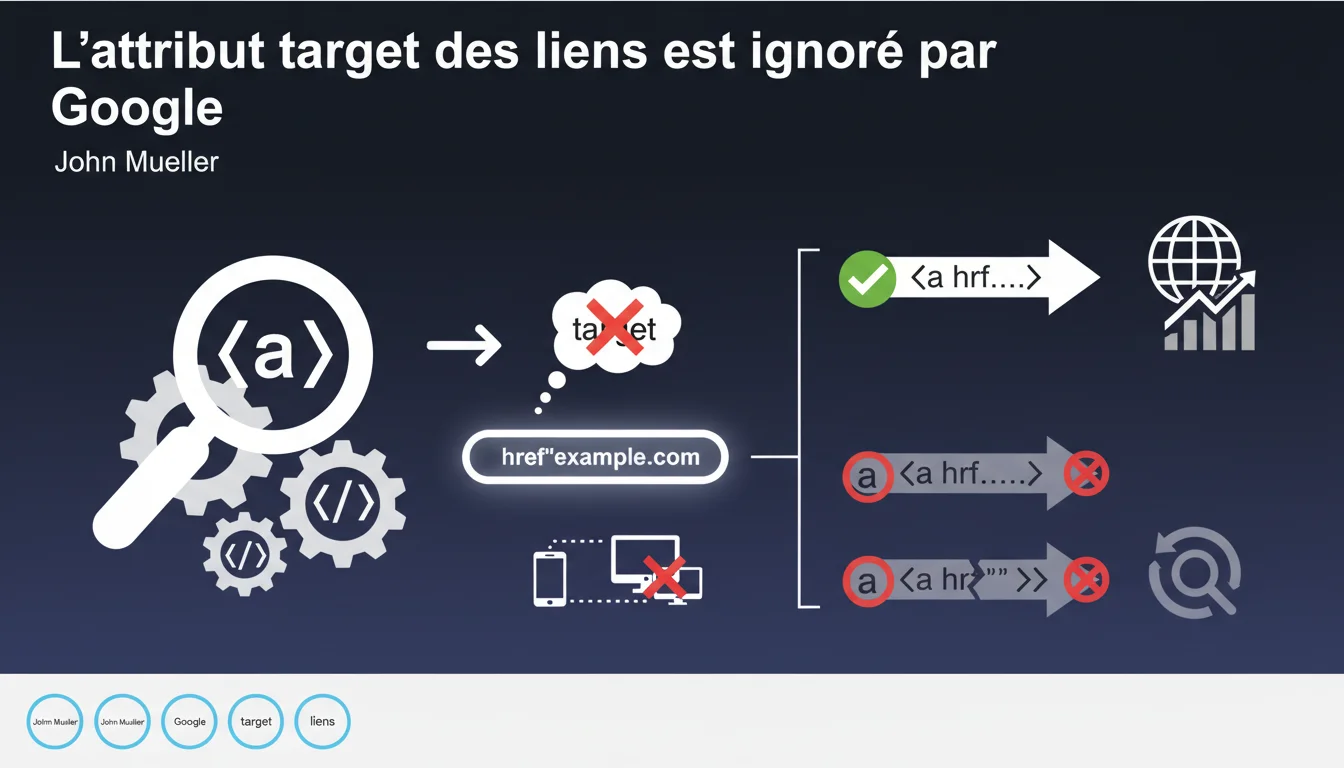
Google ignore totalement l'attribut 'target' dans les liens HTML — seul le 'href' compte pour l'exploration et le SEO. Un lien sans href ou avec href vide est traité comme un auto-lien et ne transmet aucun signal. Le comportement d'ouverture (nouvel onglet, frame) reste purement côté navigateur.
Ce qu'il faut comprendre
Pourquoi Google ignore-t-il l'attribut target ?
L'attribut target dans un lien HTML (target="_blank", target="_parent", etc.) définit uniquement le comportement d'affichage dans le navigateur de l'utilisateur. Il indique si la page doit s'ouvrir dans un nouvel onglet, une frame, ou remplacer la page actuelle.
Pour Googlebot, ces instructions sont sans objet. Le crawler ne "navigue" pas comme un humain — il extrait les URLs et les ajoute à sa file d'exploration. Peu importe que le lien s'ouvre dans un nouvel onglet ou non : seul le href détermine la destination et le transfert de PageRank.
Qu'en est-il des liens sans href ou avec href vide ?
Un lien dépourvu d'attribut href, ou avec href="" ou href="#", est considéré par Google comme pointant vers la page elle-même. Concrètement, Googlebot l'ignore totalement : aucun signal n'est transmis, aucune exploration déclenchée.
C'est particulièrement courant dans les menus déroulants ou boutons JavaScript où le <a> sert uniquement de hook événementiel. Ces pseudo-liens ne contribuent en rien au maillage interne ni au crawl budget.
Quelles sont les implications pour le maillage interne ?
Cette clarification confirme que seul le href structure votre architecture SEO. Tous les attributs annexes — target, rel (hors nofollow/sponsored/ugc), title, class — sont invisibles pour l'exploration et le calcul de popularité.
Si vous souhaitez qu'un lien transmette du jus SEO, il doit impérativement contenir un href valide pointant vers une URL explorable. Les menus en JavaScript pur, les boutons sans href, ou les ancres vides (#) sont des impasses pour Googlebot.
- L'attribut target ne joue aucun rôle dans le crawl ou le classement
- Un lien sans href ou avec href vide est ignoré par Google
- Seul le href détermine la destination et le transfert de PageRank
- Les attributs visuels ou comportementaux (class, onclick, title) n'impactent pas le SEO
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Totalement. Aucun test documenté n'a jamais montré d'influence de l'attribut target sur le crawl ou le ranking. Les discussions récurrentes sur "faut-il ouvrir les liens externes en _blank pour garder l'utilisateur" relèvent de l'UX, pas du SEO.
Ce qui mérite attention, c'est la confusion persistante entre attributs sémantiques (href, rel, hreflang) et attributs comportementaux (target, onclick, data-*). Seuls les premiers intéressent Googlebot. Les seconds sont exécutés côté client et restent invisibles au crawler.
Quelles nuances faut-il apporter à cette règle ?
La précision sur les liens sans href mérite qu'on s'y attarde. Beaucoup de frameworks JavaScript (React, Vue, Angular) génèrent des composants <a> sans href, déléguant la navigation à un routeur côté client.
Pour Google, ces liens n'existent pas. Si votre maillage interne repose sur du JavaScript non-SSR ou sans prérendu, vous fragmentez votre architecture aux yeux de Googlebot. [A vérifier] : Google affirme crawler et indexer le JavaScript moderne, mais les délais et la fiabilité restent inférieurs à un href classique.
Dans quels cas cette règle peut-elle poser problème ?
Les sites e-commerce ou SaaS utilisant des overlays, modals ou menus déroulants sans href réel cassent leur maillage interne sans s'en rendre compte. Exemple typique : un mega-menu où les catégories principales sont des <a href="#"> déclenchant une animation, et seuls les sous-liens ont un href valide.
Résultat : les pages de niveau 2-3 sont accessibles, mais la structure hiérarchique n'est pas transmise à Google. Le crawler voit un graphe plat au lieu d'une arborescence — impact direct sur la distribution du PageRank interne.
Impact pratique et recommandations
Que faut-il vérifier en priorité sur votre site ?
Lancez un crawl complet avec Screaming Frog ou Sitebulb en mode "suivre les liens internes". Filtrez les <a> sans href ou avec href="#" — ces éléments sont invisibles pour Google et cassent votre maillage.
Vérifiez également les menus générés en JavaScript pur. Si votre framework ne précharge pas les hrefs côté serveur (SSR, prérendu statique), Googlebot ne découvrira pas toutes vos pages via la navigation principale.
Quelles erreurs éviter lors de la refonte ou du développement ?
Ne confondez pas UX et SEO. Ouvrir un lien externe en target="_blank" améliore l'expérience utilisateur (il garde votre onglet ouvert), mais n'influence en rien le crawl. C'est un choix éditorial, pas une optimisation SEO.
Évitez de déléguer la navigation critique (catégories, rubriques, fiches produits) à des événements JavaScript sans fallback href. Un lien SEO-friendly doit fonctionner même si JS est désactivé — c'est la règle de base du progressive enhancement.
Comment auditer et corriger les liens cassés pour Google ?
Utilisez la Search Console pour identifier les pages orphelines (indexées mais non découvertes par crawl interne). Croisez avec votre sitemap : si des URLs apparaissent uniquement dans le XML et jamais dans les rapports de liens internes, c'est un signal d'alerte.
Corrigez en ajoutant des hrefs valides dans votre navigation, fil d'Ariane, ou maillage contextuel. Supprimez les <a href="#"> purement décoratifs ou remplacez-les par des <button> si aucune navigation n'est attendue.
- Crawler le site et lister tous les
<a>sans href ou avec href vide - Vérifier que la navigation principale (menu, footer) contient des hrefs exploitables
- Contrôler le rendu JavaScript via Search Console (test d'URL en direct)
- Auditer les pages orphelines et rétablir le maillage manquant
- Privilégier le progressive enhancement : href d'abord, JavaScript ensuite
- Documenter les règles de développement pour éviter les régressions futures
❓ Questions frequentes
L'attribut target="_blank" améliore-t-il le SEO de mes liens externes ?
Un lien avec href="#" transmet-il du PageRank interne ?
Les menus JavaScript sans href cassent-ils mon maillage interne ?
Dois-je supprimer tous mes target="_blank" pour améliorer mon SEO ?
Comment vérifier que mes liens sont bien crawlables par Google ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 22/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.