Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi Google n'indexe-t-il jamais l'intégralité d'un site web ?
- □ Faut-il vraiment attendre que Google indexe vos pages ?
- □ Comment Googlebot ajuste-t-il sa vitesse de crawl en fonction des performances de votre serveur ?
- □ Comment diagnostiquer les problèmes serveur qui freinent le crawl de Google ?
- □ Les problèmes de serveur ne touchent-ils vraiment que les très gros sites ?
- □ Pourquoi Google refuse-t-il d'indexer vos pages en statut 'Découvert' ?
- □ Google peut-il vraiment ignorer des pans entiers de votre site à cause d'un pattern de faible qualité ?
- □ Le maillage interne suffit-il vraiment à faire indexer vos pages découvertes ?
- □ Faut-il vraiment se préoccuper des pages non indexées par Google ?
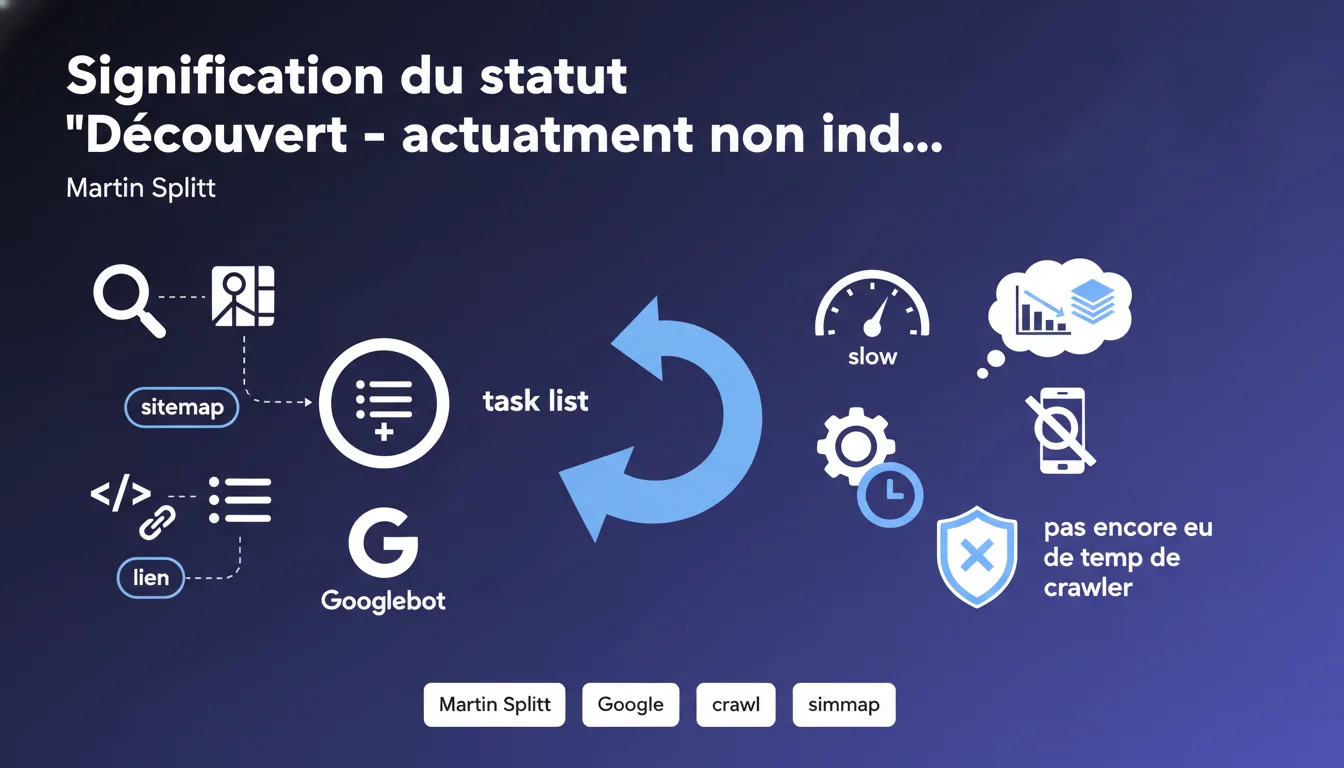
Quand Google affiche 'Découvert - actuellement non indexé', cela signifie simplement que Googlebot a repéré l'URL mais n'a pas encore eu le temps de la crawler — il était occupé ailleurs. Ce n'est pas un signal de pénalité, juste une question de priorisation dans la file d'attente de crawl.
Ce qu'il faut comprendre
Qu'est-ce que ce statut signifie concrètement ?
Le statut 'Découvert - actuellement non indexé' apparaît dans la Search Console quand Googlebot a identifié une URL — via un sitemap, un lien interne ou externe — mais ne l'a pas encore visitée.
Cette URL entre dans une file d'attente de crawl. Google n'a rien contre elle, il n'a simplement pas encore alloué de ressources pour la traiter. Martin Splitt précise que c'est une question de priorité : d'autres URLs ont capté l'attention du bot avant la vôtre.
Est-ce que cela signifie un problème technique ?
Non. Ce statut n'est pas une pénalité, ni un indicateur de contenu de mauvaise qualité. Il ne dit rien sur la valeur intrinsèque de votre page.
C'est un état transitoire. Une URL peut rester ainsi quelques jours, quelques semaines — voire plus longtemps si votre site n'a pas un crawl budget généreux ou si la page est jugée peu prioritaire par l'algorithme de Googlebot.
Quels sont les facteurs qui influencent ce délai ?
Google ne détaille pas publiquement ses critères de priorisation, mais on sait que plusieurs éléments entrent en jeu : la popularité du site, la fréquence de mise à jour, la qualité perçue des contenus déjà indexés, la profondeur de la page dans l'arborescence.
Un site à faible PageRank interne, peu de backlinks et des contenus peu crawlés verra ce statut persister plus longtemps qu'un site à forte autorité avec un rythme de publication soutenu.
- Ce statut n'est pas une sanction — c'est un indicateur de file d'attente.
- Googlebot découvre l'URL mais ne l'a pas encore visitée par manque de temps ou de priorité.
- Le délai dépend du crawl budget et de la hiérarchisation interne des URLs par Google.
- Aucun signal de qualité n'est directement associé à ce statut — pour l'instant.
Avis d'un expert SEO
Cette explication de Google est-elle complète ?
Soyons honnêtes : elle est techniquement correcte, mais incomplète. Dire que Googlebot était "occupé avec d'autres URLs" revient à admettre qu'il y a une hiérarchie de priorités — mais Google ne détaille jamais quels critères pèsent dans cette priorisation.
Sur le terrain, on observe que certaines URLs en 'Découvert' restent bloquées pendant des mois, même sur des sites à crawl budget théoriquement confortable. Si c'était vraiment une simple question de "pas encore eu le temps", pourquoi ce délai parfois si long ? [A vérifier] avec des données de crawl détaillées, mais l'hypothèse d'un filtre implicite de qualité ou de pertinence n'est pas à exclure.
Dans quels cas ce statut devient-il problématique ?
Si une poignée de pages secondaires restent en 'Découvert', ce n'est pas dramatique. En revanche, si vous constatez que des pages stratégiques — nouvelles fiches produits, articles de blog importants — stagnent dans cet état pendant plusieurs semaines, il y a un souci de crawl budget ou de priorisation interne.
Concrètement ? Cela peut signaler un maillage interne défaillant, un manque de signaux de fraîcheur, ou simplement un site trop vaste pour le budget de crawl alloué. Google ne le dira pas explicitement, mais c'est à vous de diagnostiquer.
Faut-il forcer le crawl de ces URLs ?
Demander une indexation via la Search Console peut accélérer le processus pour quelques URLs critiques, mais ce n'est pas une solution scalable. Si vous avez des centaines de pages en 'Découvert', forcer l'indexation manuellement est irréaliste.
Mieux vaut travailler sur les signaux structurels : améliorer le maillage interne, booster la popularité des pages orphelines, optimiser la fréquence de crawl via le fichier robots.txt et les sitemaps stratégiques. Si Google priorise mal vos contenus, c'est souvent que votre architecture ne lui donne pas les bons indices.
Impact pratique et recommandations
Que faire si trop de pages restent en 'Découvert' ?
Première étape : audit de votre crawl budget. Consultez les rapports de crawl dans la Search Console et identifiez les URLs qui monopolisent inutilement des ressources — pages dupliquées, URLs paramétriques, contenus obsolètes.
Ensuite, renforcez le maillage interne vers les pages stratégiques. Si une page importante est à 4-5 clics de la homepage, Googlebot la verra comme secondaire. Remontez-la dans l'arborescence, ajoutez des liens contextuels depuis des pages à fort PageRank interne.
Quelles erreurs éviter absolument ?
Ne bombardez pas Google de demandes d'indexation manuelle pour des centaines d'URLs. Cela ne résout rien structurellement et risque de diluer l'efficacité de vos demandes légitimes.
Évitez aussi de soumettre des sitemaps XML massifs contenant des milliers d'URLs peu importantes. Google va les découvrir, mais ne les crawlera pas — vous saturez inutilement la file d'attente. Mieux vaut un sitemap ciblé sur vos contenus prioritaires.
Comment vérifier que votre optimisation fonctionne ?
Suivez l'évolution du statut 'Découvert' dans la Search Console sur 4 à 6 semaines. Si le nombre d'URLs en attente diminue progressivement, c'est que votre optimisation de crawl budget porte ses fruits.
Utilisez aussi des outils de log analysis (Oncrawl, Botify, Screaming Frog Log Analyzer) pour observer la fréquence réelle de passage de Googlebot et ajuster vos priorités en conséquence.
- Identifier les URLs stratégiques bloquées en 'Découvert' depuis plus de 2 semaines
- Auditer le crawl budget et désindexer les contenus inutiles (balise noindex, robots.txt)
- Renforcer le maillage interne vers les pages prioritaires
- Soumettre un sitemap XML ciblé, pas exhaustif
- Surveiller les logs serveur pour confirmer l'augmentation du crawl Googlebot
- Éviter les demandes d'indexation manuelle en masse
❓ Questions frequentes
Combien de temps une URL peut-elle rester en 'Découvert - actuellement non indexé' ?
Faut-il supprimer les URLs en 'Découvert' du sitemap ?
Demander une indexation manuelle accélère-t-il le processus ?
Ce statut signifie-t-il que ma page est de mauvaise qualité ?
Peut-on forcer Google à crawler plus rapidement un site ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 20/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.