Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi Google n'indexe-t-il jamais l'intégralité d'un site web ?
- □ Pourquoi vos pages restent-elles en 'Découvert - actuellement non indexé' ?
- □ Faut-il vraiment attendre que Google indexe vos pages ?
- □ Comment Googlebot ajuste-t-il sa vitesse de crawl en fonction des performances de votre serveur ?
- □ Comment diagnostiquer les problèmes serveur qui freinent le crawl de Google ?
- □ Les problèmes de serveur ne touchent-ils vraiment que les très gros sites ?
- □ Pourquoi Google refuse-t-il d'indexer vos pages en statut 'Découvert' ?
- □ Le maillage interne suffit-il vraiment à faire indexer vos pages découvertes ?
- □ Faut-il vraiment se préoccuper des pages non indexées par Google ?
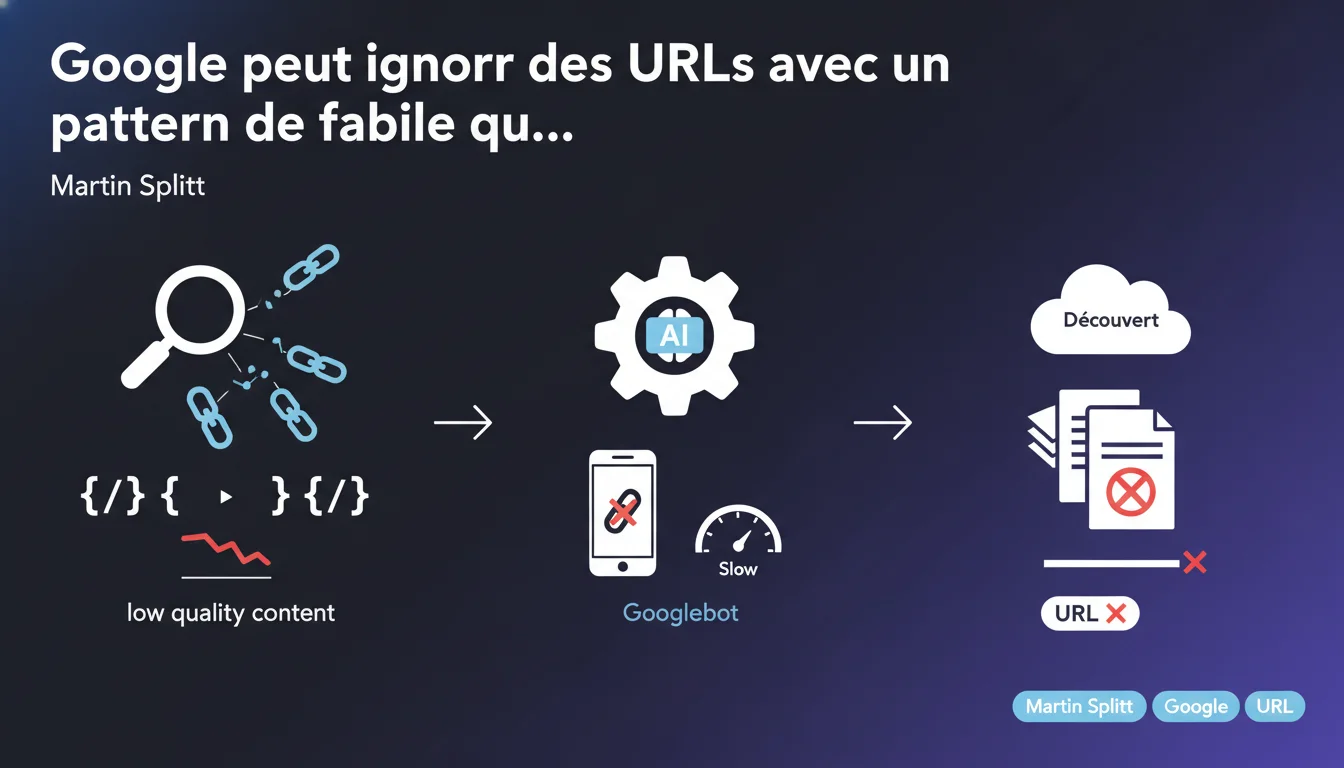
Google peut décider de ne pas traiter des URLs qu'il a découvertes si un pattern récurrent de contenu faible qualité est détecté sur ces URLs. Ces pages restent bloquées au statut 'Découvert' dans Search Console — crawlées mais jamais indexées. C'est une forme de pénalité silencieuse qui ne touche pas tout le site mais uniquement les sections identifiées comme problématiques.
Ce qu'il faut comprendre
Que signifie concrètement ce statut 'Découvert' ?
Dans Google Search Console, le statut 'Découvert – actuellement non indexé' indique que Googlebot connaît l'existence d'une URL — via un lien interne, un sitemap ou une redirection — mais qu'il a choisi de ne pas la crawler ni l'indexer.
Ce n'est pas un bug technique. C'est une décision algorithmique : Google estime que le jus de crawl serait mieux employé ailleurs. Quand ce statut touche des dizaines ou centaines d'URLs avec un pattern commun (même structure d'URL, même type de contenu), c'est rarement un hasard.
Comment Google détecte-t-il un pattern de faible qualité ?
Google ne le dit pas explicitement, mais on peut recouper plusieurs signaux : taux de rebond élevé sur ces pages si elles ont été crawlées initialement, absence de backlinks, contenu dupliqué ou thin content, temps de crawl excessif pour un retour perçu comme faible.
L'algorithme apprend vite. Si les 10 premières URLs d'une catégorie donnée sont jugées sans intérêt, Google peut décider de sauter les 1000 suivantes qui partagent la même structure. C'est une extrapolation économique : pourquoi crawler ce qui ne sera probablement jamais bien classé ?
Quels types de contenus sont visés en priorité ?
- Pages de tags automatiques générées sans curation éditoriale
- Fiches produits sans stock ou abandonnées (e-commerce)
- Pages de résultats de recherche interne indexables
- Archives par date sans valeur ajoutée
- Contenus générés par utilisateurs non modérés (forums, avis)
- Variantes paramétrées d'une même page (filtres, tris)
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. Depuis des années, on voit des sites avec des milliers d'URLs en 'Découvert' qui ne bougent jamais, même après des soumissions répétées via sitemap. La nouveauté ici, c'est que Martin Splitt confirme ce que beaucoup soupçonnaient : ce n'est pas un problème de capacité de crawl, c'est un choix délibéré de Google basé sur un pattern détecté.
Ce qui est intéressant — et agaçant — c'est que Google ne vous dit pas quel pattern précis il a détecté. Vous devez deviner. Est-ce la structure d'URL ? Le contenu ? Le comportement utilisateur ? Probablement un mix. [A verifier] : aucune donnée officielle sur les seuils ou critères précis.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre site a une autorité forte et un historique de contenu de qualité, Google sera plus tolérant. Un média établi peut se permettre quelques sections faibles sans que tout soit boycotté. Un petit site récent, non.
Autre cas : les URLs stratégiques fortement maillées et avec des backlinks externes ne tomberont probablement pas dans cette trappe, même si elles partagent un pattern avec d'autres pages ignorées. Google pondère ses décisions.
Faut-il voir cela comme une pénalité ?
Pas au sens classique. Ce n'est pas une manual action, et ça ne touche pas tout le site. Mais c'est quand même une sanction : Google vous dit implicitement que vous générez trop de pages sans valeur et qu'il va trier à votre place.
Le vrai problème ? Vous perdez le contrôle. Impossible de savoir précisément quelles URLs sont blacklistées, ni de forcer une réévaluation facilement. Google vous laisse dans le flou — et c'est frustrant pour un SEO qui aime piloter proprement son indexation.
Impact pratique et recommandations
Que faut-il faire si des centaines d'URLs sont bloquées en 'Découvert' ?
D'abord, identifiez le pattern. Exportez vos URLs en statut 'Découvert' depuis Search Console, groupez-les par structure (regex, préfixe, catégorie). Regardez ce qu'elles ont en commun : URL, contenu, ancienneté, maillage interne.
Ensuite, posez-vous la vraie question : ces pages méritent-elles vraiment d'être indexées ? Soyons honnêtes, dans 70% des cas, la réponse est non. Si c'est du contenu faible généré automatiquement, mieux vaut le noindexer proprement ou le supprimer. Google vous fait un service en ne les indexant pas — ne le forcez pas à le faire.
Comment relancer l'indexation des pages légitimes ?
Si le contenu est réellement de qualité mais ignoré par association, plusieurs leviers :
- Enrichir substantiellement le contenu (pas juste 50 mots de plus, un vrai apport éditorial)
- Améliorer le maillage interne depuis des pages déjà crawlées et de confiance
- Changer la structure d'URL pour casser le pattern suspect (redirection 301 propre)
- Obtenir des backlinks externes vers quelques-unes de ces pages pour signaler leur valeur
- Soumettre manuellement un petit batch via l'API Indexing (pas le sitemap — trop passif)
Ne soumettez pas 500 URLs d'un coup. Commencez par 10-20 des meilleures, améliorées et renforcées. Si Google les indexe, c'est que le signal de qualité est passé. Déployez progressivement.
Quelles erreurs absolument éviter ?
Ne tentez pas de forcer l'indexation via des outils automatisés de ping ou en spammant l'API. Google détecte ces manipulations et ça ne fera qu'empirer le problème.
Ne laissez pas traîner indéfiniment des milliers d'URLs en 'Découvert'. Ça pollue votre crawl budget et envoie des signaux négatifs sur la gouvernance de votre site. Mieux vaut un site de 1000 pages bien indexées qu'un site de 10 000 pages dont 8000 sont ignorées.
❓ Questions frequentes
Combien de temps faut-il pour que Google réévalue un pattern d'URLs ignorées ?
Le statut 'Découvert' affecte-t-il le reste du site ?
Peut-on forcer l'indexation avec l'outil d'inspection d'URL ?
Les sitemaps servent-ils encore à quelque chose dans ce contexte ?
Faut-il supprimer ou noindexer les pages en 'Découvert' ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 20/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.