Declaration officielle
Autres déclarations de cette vidéo 9 ▾
- □ Pourquoi Google n'indexe-t-il jamais l'intégralité d'un site web ?
- □ Pourquoi vos pages restent-elles en 'Découvert - actuellement non indexé' ?
- □ Faut-il vraiment attendre que Google indexe vos pages ?
- □ Comment Googlebot ajuste-t-il sa vitesse de crawl en fonction des performances de votre serveur ?
- □ Comment diagnostiquer les problèmes serveur qui freinent le crawl de Google ?
- □ Les problèmes de serveur ne touchent-ils vraiment que les très gros sites ?
- □ Google peut-il vraiment ignorer des pans entiers de votre site à cause d'un pattern de faible qualité ?
- □ Le maillage interne suffit-il vraiment à faire indexer vos pages découvertes ?
- □ Faut-il vraiment se préoccuper des pages non indexées par Google ?
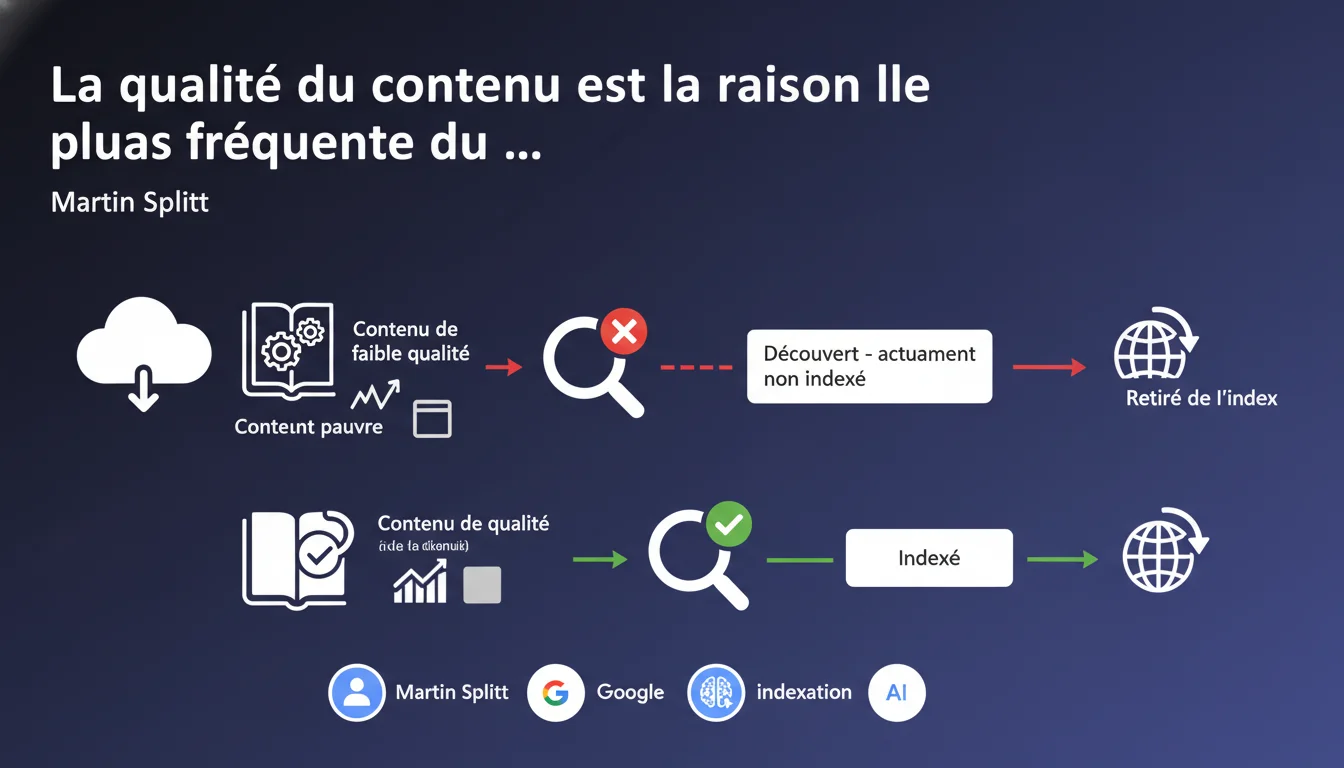
La principale raison pour laquelle des pages restent en statut 'Découvert - actuellement non indexé' est la qualité du contenu. Google détecte des patterns de contenu faible ou pauvre et décide de ne pas indexer ces pages, voire de les retirer de l'index. Un signal clair que le moteur privilégie la qualité à la quantité.
Ce qu'il faut comprendre
Martin Splitt, Developer Advocate chez Google, confirme ce que beaucoup suspectaient : le statut 'Découvert - actuellement non indexé' reflète souvent un problème de qualité de contenu. Ce statut apparaît dans la Search Console quand Googlebot a trouvé une URL mais a choisi de ne pas l'indexer.
Cette déclaration met fin à certaines spéculations. Beaucoup de SEO pensaient que ce statut relevait uniquement de problèmes techniques — crawl budget, robots.txt mal configuré, manque de liens internes. Splitt tranche : la qualité du contenu arrive en tête.
Comment Google détecte-t-il un pattern de faible qualité ?
Google analyse les pages d'un site et détecte des récurrences de contenu pauvre. Si plusieurs pages présentent des caractéristiques similaires — contenu mince, faible valeur ajoutée, duplication partielle — le moteur peut décider de ne pas indexer l'ensemble de ces pages.
Ce mécanisme repose sur une analyse par pattern plutôt que page par page. Une seule page médiocre ne suffit pas : c'est la répétition du problème qui déclenche la sanction.
Quelles sont les implications pour l'indexation de votre site ?
Si Google détecte un pattern de contenu faible, deux scénarios se dessinent. Soit les nouvelles pages restent en statut 'Découvert' sans jamais être indexées. Soit des pages déjà indexées peuvent être retirées de l'index.
Ce second cas est plus préoccupant : vous perdez de la visibilité sur des pages qui performaient peut-être. Le signal envoyé par Google est sans ambiguïté : améliorez la qualité ou acceptez de disparaître des résultats.
- Le statut 'Découvert - actuellement non indexé' indique souvent un problème de qualité de contenu.
- Google détecte des patterns de contenu faible sur plusieurs pages, pas seulement des cas isolés.
- Les pages peuvent rester non indexées ou être retirées de l'index si le problème persiste.
- Ce mécanisme privilégie la qualité du contenu à la quantité de pages crawlées.
Avis d'un expert SEO
Cette déclaration confirme des observations terrain répétées depuis des mois. Sur de nombreux sites, les pages en statut 'Découvert' accumulent des signaux négatifs : contenu généré automatiquement, pages de pagination sans valeur ajoutée, fiches produits dupliquées.
Mais attention : Google reste flou sur les critères précis qui définissent un « contenu de faible qualité ». Splitt ne donne aucun seuil, aucun indicateur mesurable. [À vérifier] : comment déterminer si votre contenu franchit la ligne rouge ?
Cette règle s'applique-t-elle à tous les types de sites ?
Pas forcément. Les sites e-commerce avec des milliers de fiches produits sont particulièrement exposés. Les descriptions courtes et répétitives déclenchent facilement ce pattern de faible qualité.
En revanche, un site éditorial avec 50 articles longs et documentés a peu de risques. Même si un ou deux articles sont moyens, Google ne détectera pas de pattern systématique. Le volume de pages joue un rôle clé dans cette évaluation.
Quelles nuances faut-il apporter à cette déclaration ?
Splitt parle de « raison la plus courante », pas de « seule raison ». D'autres facteurs techniques peuvent bloquer l'indexation : canonicalisation incorrecte, pages orphelines sans liens internes, robots.txt restrictifs.
Un piège classique : confondre corrélation et causalité. Une page en statut 'Découvert' peut souffrir à la fois d'un problème de qualité ET d'un problème technique. Corriger un seul des deux ne suffira pas toujours.
Impact pratique et recommandations
Que faut-il faire concrètement pour sortir du statut 'Découvert' ?
Première étape : identifier les pages concernées dans la Search Console, section « Pages ». Exportez la liste et cherchez des patterns communs : même type de page, même structure, même longueur de contenu.
Ensuite, évaluez la valeur ajoutée réelle de ces pages. Posez-vous la question : si vous étiez un utilisateur, cette page répondrait-elle à une intention de recherche précise ? Si non, améliorez ou supprimez.
Quelles erreurs éviter absolument ?
Ne tentez pas de forcer l'indexation via des soumissions massives dans la Search Console. Google a déjà crawlé ces pages — le problème n'est pas la découverte, c'est la décision de ne pas indexer.
Évitez aussi de gonfler artificiellement le contenu avec du texte inutile. Google détecte le keyword stuffing et le remplissage creux. Mieux vaut 300 mots pertinents que 1000 mots dilués.
Comment mesurer l'amélioration après correction ?
Suivez l'évolution du nombre de pages en statut 'Découvert' dans la Search Console. Une baisse progressive indique que Google reconsidère vos pages. Patience : le recrawl peut prendre plusieurs semaines.
Parallèlement, surveillez l'évolution du trafic organique sur les sections corrigées. Si le contenu est réellement meilleur, vous devriez voir une hausse des impressions et des clics dans les 30 à 60 jours.
- Exportez la liste des pages en statut 'Découvert' depuis la Search Console.
- Identifiez les patterns de contenu faible récurrents (pages similaires, contenu mince).
- Évaluez la valeur ajoutée de chaque type de page : utile à l'utilisateur ou non ?
- Améliorez le contenu de manière substantielle ou supprimez les pages inutiles.
- Évitez les soumissions massives à l'indexation — ce n'est pas un problème de crawl.
- Surveillez l'évolution du statut sur 4 à 8 semaines après corrections.
- Mesurez l'impact sur le trafic organique des sections modifiées.
Corriger un problème de qualité à grande échelle demande un audit méthodique et des arbitrages stratégiques. Chaque section de votre site doit apporter une valeur claire et différenciée. Si cette démarche vous semble complexe à orchestrer en interne, collaborer avec une agence SEO spécialisée peut accélérer le diagnostic et la mise en œuvre des corrections adaptées à votre contexte.
❓ Questions frequentes
Le statut 'Découvert - actuellement non indexé' est-il toujours lié à la qualité du contenu ?
Combien de temps faut-il pour qu'une page corrigée sorte du statut 'Découvert' ?
Faut-il supprimer les pages en statut 'Découvert' ou les améliorer ?
Soumettre manuellement une page en statut 'Découvert' peut-il forcer son indexation ?
Comment savoir si mon contenu est considéré comme 'de faible qualité' par Google ?
🎥 De la même vidéo 9
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 20/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.