Official statement
Other statements from this video 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Google privilégie-t-il vraiment les pages de qualité dans son crawl ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ La qualité d'une page détermine-t-elle vraiment le crawl des pages suivantes ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
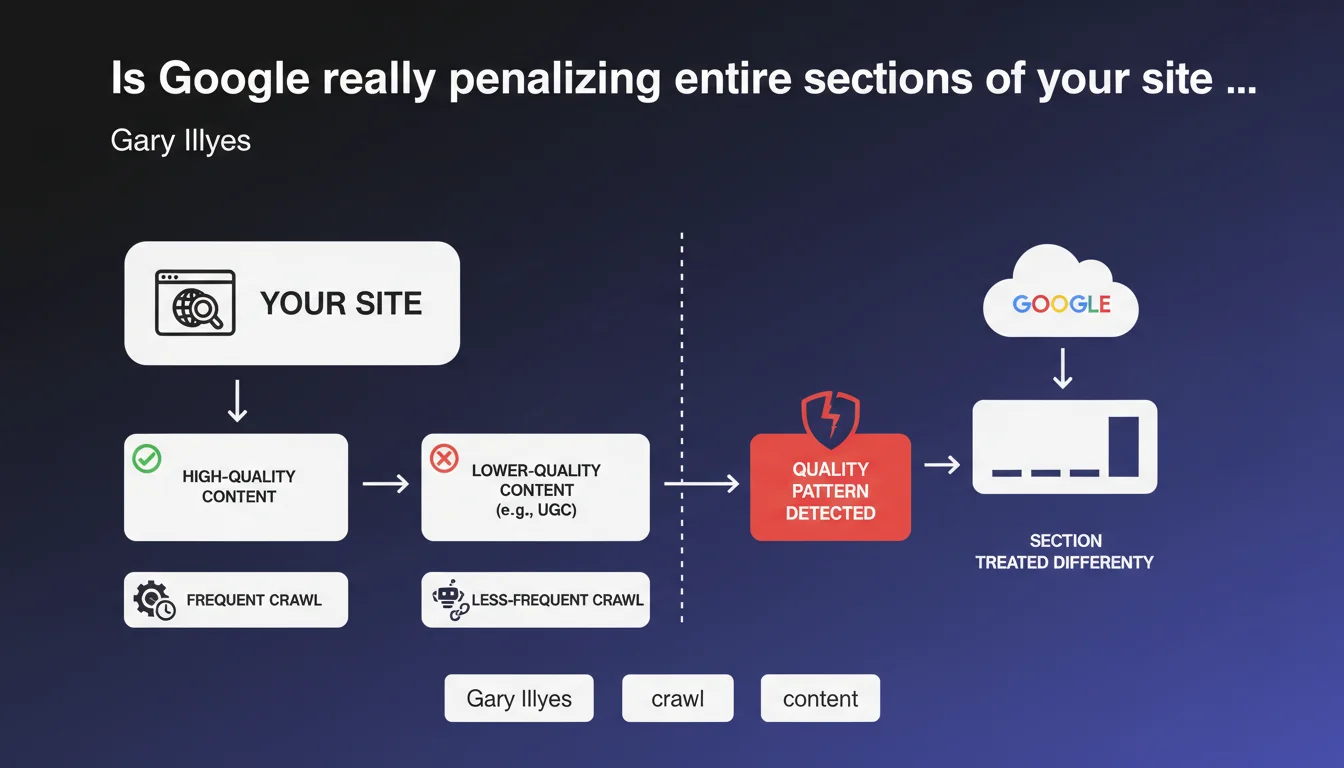
Google adapts its algorithmic treatment section by section within the same website. If certain URL patterns consistently show lower-quality content — typically poorly moderated user-generated content zones — the search engine adjusts crawl frequency, indexation, and likely ranking accordingly. Quality evaluation is therefore no longer limited to the domain level, but also extends to thematic or functional subsets.
What you need to understand
Does Google really analyze your site section by section?
Yes, and it's a major shift in how we think about site architecture. For a long time, we reasoned in terms of domain authority: a good site carried its weak pages. Gary Illyes' statement confirms that Google identifies URL patterns — forums, comments, auto-generated listings — and applies differentiated treatment to them.
Concretely? If /forum/* displays spam repeatedly, Google can decide to crawl that section less often, or even refrain from indexing certain pages, even if the rest of the site shines. The engine learns: it detects recurring signals (bounce rate, low engagement, duplicate content) and draws structural conclusions from them.
What types of sections are prioritized for this treatment?
User-generated content (UGC) tops the list: forums, comments, unmoderated reviews, community Q&A. Next come auto-generated pages with low added value — infinite facets, cross-referenced tags, chronological archives without unique content.
But it doesn't stop there. Entire sections of obsolete products, mass-created generic landing pages for long tail keywords, corporate blogs filled with press releases... all of this can fall under Google's negative radar if quality isn't there.
What triggers this differentiated treatment?
Google doesn't give a precise threshold — obviously — but several signals likely come into play. First, qualitative consistency: if 80% of URLs in a given pattern generate little interaction, few backlinks, lots of pogo-sticking, the algorithm draws conclusions.
Next, thin content density: short pages, lack of semantic structure, internal duplication. Finally, behavioral signals — even though Google always downplays their official weight, a URL pattern systematically avoided by users eventually sends a clear message.
- Google segments sites into URL patterns and applies distinct treatment to each based on observed quality
- Poorly moderated UGC sections are the first to be affected, but any low-quality zone can be impacted
- Crawl, indexation, and likely ranking are adjusted section by section — not just at the domain level
- The algorithm learns from recurring signals: low engagement, duplicate content, absence of natural backlinks
SEO Expert opinion
Does this statement match what we observe in practice?
Yes, and it has for a while now. Crawl audits regularly show entire site sections being crawled once a month, while others are crawled daily. This isn't random. Google allocates its crawl budget based on perceived value — and sectional quality weighs heavily in this equation.
We also see sites where certain sections barely appear in the SERPs, even with precise branded queries. It's not a noindex — it's soft deindexation, where Google technically indexes but never shows the pages. That perfectly aligns with what Illyes describes.
What nuances should be added to this claim?
First nuance: Google doesn't explicitly say this impacts ranking — only crawl. But let's be honest, if a section is crawled less often, it will take longer to index, and will have fewer chances to rank. The cascade effect is obvious.
Second point: the term "lower quality" remains vague. Google specifies neither threshold nor metric. Does 30% of weak pages condemn a section? 50%? 80%? No answer. [To be verified] on your own data via Search Console and server logs.
Third element — and this is crucial — this logic can backfire on you if you isolate your content poorly. If Google confuses a UGC section with your editorial blog because the information architecture is unclear, it can penalize the entire site. Architecture therefore becomes a survival issue for SEO, not just an ergonomics question.
In what cases might this rule not apply?
On very large authoritative sites with solid history, Google seems more tolerant. A Reddit forum can contain millions of low-quality pages — it doesn't prevent the domain from ranking massively. Notoriety and quality backlinks create a kind of buffer.
Another case: sites whose weak sections are so marginal that they don't weigh statistically. If you have 10,000 excellent product pages and 50 old crappy blog posts, Google won't degrade your entire site. But if the proportions reverse, watch out.
Practical impact and recommendations
What should you concretely do to protect fragile sections?
First, identify at-risk URL patterns. Analyze your server logs and Search Console: which sections are crawled infrequently? Which ones generate few organic clicks? Cross-reference with your engagement metrics (time on page, bounce rate) to spot problem areas.
Next, decide the fate of each section. Three options: improve quality (UGC moderation, editorial enrichment, redesign), block crawl (robots.txt, noindex) if the content has no SEO value, or delete outright if it's dead weight. Don't keep a section just because it's existed for 10 years.
Finally, clearly separate in your information architecture sections with variable quality. If your corporate blog (/news/) sits beside a user forum, isolate the latter in /community/ with distinct architecture. This limits the risk of algorithmic contamination.
What mistakes should you absolutely avoid?
Mistake number one: letting thousands of spammy UGC pages sit around "just in case". Google has no mercy for zombie content. If a page delivers nothing — neither traffic, nor backlinks, nor conversions — it hurts more than it helps.
Mistake two: creating infinite facets or tags without editorial control. Each new filter combination generates a URL — and if 90% of these URLs display 3 generic products, you've just signaled a low-quality section to Google. Limit indexable combinations or add unique content per facet.
Mistake three: ignoring crawl signals. If Googlebot avoids a section for months, it's not a bug — it's a message. Don't force indexation via XML sitemap without first fixing the underlying problem.
How do you verify your site isn't already impacted?
Analyze your server logs over at least 3 months. Segment by URL pattern and compare crawl frequency. If certain sections are visited 10 times less often than others, dig deeper. Next check Search Console for indexed vs submitted pages: a significant gap often signals a quality issue.
Also test manually: run site:yourdomain.com/suspect-section/ queries in Google. If results are minimal while hundreds of pages exist, that's a bad sign. Finally, monitor organic traffic evolution by section in Analytics — a progressive drop without external cause often indicates differentiated algorithmic treatment.
- Audit server logs and Search Console to identify under-crawled or under-indexed sections
- Clean or block low-quality UGC content (spam, duplicates, empty pages)
- Limit indexable facets and tags to only high-value combinations
- Architecturally separate sections with variable quality (distinct URLs, clear silos)
- Regularly monitor crawl by URL pattern to detect degradation
- Enrich fragile sections with structured editorial content or deindex them completely
❓ Frequently Asked Questions
Google peut-il vraiment dégrader tout un domaine à cause d'une seule section de mauvaise qualité ?
Faut-il systématiquement bloquer l'indexation des contenus UGC ?
Comment savoir si Google traite différemment certaines sections de mon site ?
Est-ce que cette logique s'applique aussi aux sous-domaines ?
Améliorer progressivement une section dégradée peut-il inverser la tendance ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 19/09/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.