Official statement
Other statements from this video 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Google privilégie-t-il vraiment les pages de qualité dans son crawl ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ La qualité d'une page détermine-t-elle vraiment le crawl des pages suivantes ?
- □ Google peut-il vraiment pénaliser certaines sections de votre site en fonction de leur qualité ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
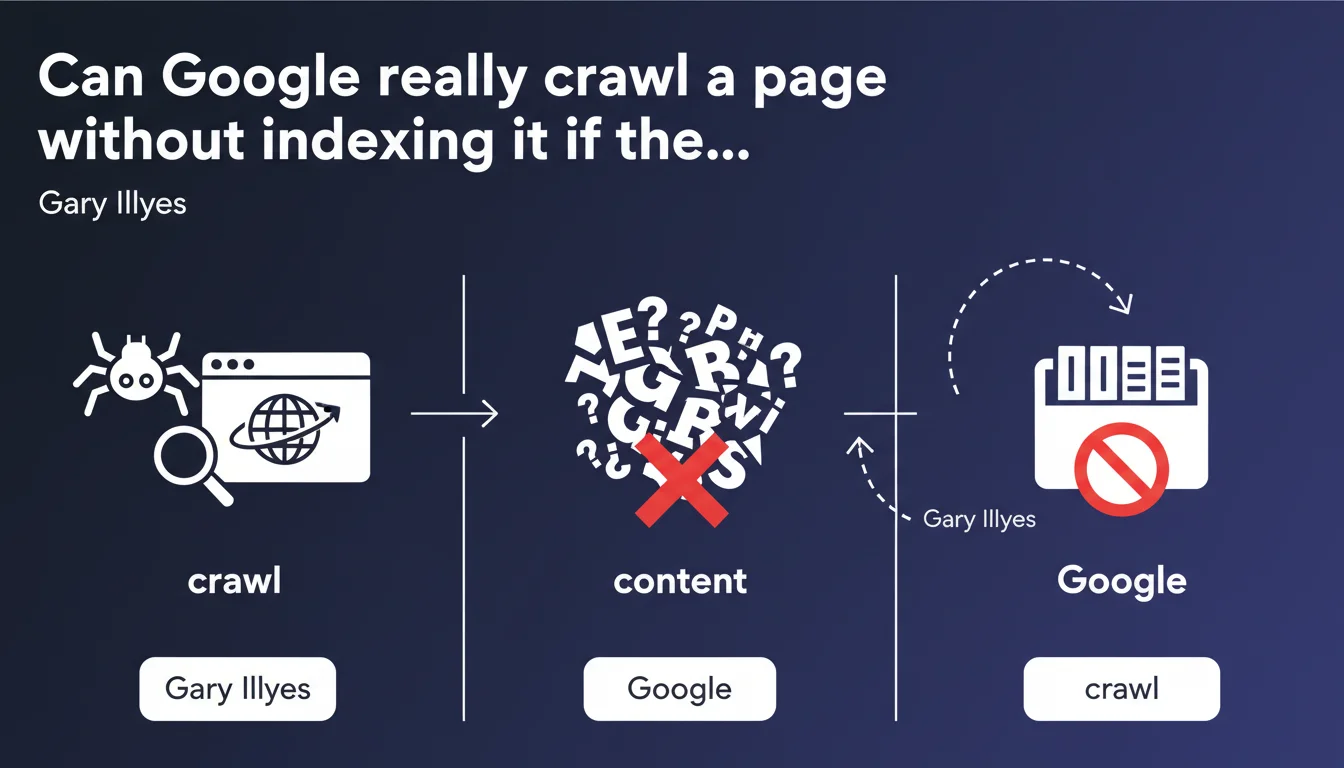
Google can crawl a page without indexing it if the content is gibberish or unintelligible. The engine must extract words and meaning — without that, no indexation. This distinction between crawl and indexation reminds us that semantic quality remains a critical filter, even after Googlebot's visit.
What you need to understand
Gary Illyes states a simple principle: crawling does not mean indexing. Googlebot visits billions of pages, but only a fraction ends up in the index. Content must be readable, structured, and meaningful.
This statement underscores that indexation is conditional. The engine analyzes text, extracts keywords, builds semantic signals. If the page is gibberish — randomly generated text, mixed languages, incoherent sentences — the system gives up.
What makes content "unintelligible" to Google?
Several situations trigger this filter. Automatically generated text without human review, pages stuffed with keywords without logical structure, malformed scripts that display code instead of content.
Google uses language models to evaluate syntactic and semantic coherence. If content looks like noise, the engine treats it as such. Pages in exotic languages with poor encoding, hidden CSS content that appears during crawl but not to users, or link farms generated by scraping often fall into this category.
Is the crawl/indexation distinction new?
Not at all. Google has been saying for years that crawling guarantees nothing. But this statement reformulates a filter often overlooked: semantic quality.
Unlike other signals — speed, mobile-first, backlinks — this one is binary. Either content is understandable or it isn't. No technical work will compensate for incoherent text.
What signals does Google analyze to decide?
We can assume the engine evaluates lexical density, grammatical coherence, the presence of recognizable syntactic structures. NLP (Natural Language Processing) models detect anomalies: aberrant repetitions, lack of verbs, sequences of unrelated words.
Google doesn't publish a precise threshold, but field observations show that pages generated by poor-quality spinners or automatically translated content without review are regularly excluded from the index.
- Crawling does not imply indexing — Google visits billions of pages, only a fraction enters the index
- Content must be semantically exploitable — coherent text, identifiable words, logical structure
- Gibberish is grounds for rejection — randomly generated text, mixed languages, incoherent keyword stuffing
- NLP models detect anomalies — lexical density, grammatical coherence, syntactic structures
- No technical signal compensates for unintelligible content — semantic quality is a binary filter
SEO Expert opinion
Is this statement really useful for practitioners?
Let's be honest: 99% of legitimate sites have no issues with this filter. "Unintelligible" content mainly concerns automated content farms, poorly calibrated AI-generated pages, or outdated black hat techniques.
The value of this statement isn't so much in diagnosis as in the confirmation of a principle often forgotten: Google doesn't just read HTML, it looks for meaning. Practitioners who optimize for robots while forgetting semantic coherence take a risk.
What gray areas does this rule leave?
Gary Illyes doesn't specify where "gibberish" begins. Will content generated by AI with awkward phrasing but grammatically correct be indexed? Probably yes. [To verify] Text in French mixed with English in a multilingual context? It depends.
Pages with highly specialized technical jargon — API documentation, patents, scientific literature — can trigger false positives. Google claims to handle these cases, but we regularly observe expert pages excluded from the index for "low quality," even though the content is perfectly coherent for a knowledgeable audience.
Another gray area: pages in languages poorly represented in Google's training corpus. A page in Breton or Quechua, even perfectly written, could be poorly evaluated if the engine doesn't have enough data to validate linguistic coherence.
Does this statement contradict field observations?
Not really, but it simplifies. We know Google sometimes indexes pages with low semantic quality if they receive powerful backlinks or if the domain has strong authority. The "gibberish" filter thus seems applied with variable tolerance.
Experience also shows that technically valid pages — well-structured, with clean Hn tags — can be excluded if content lacks depth or coherence. Google doesn't say "short content = gibberish," but the two problems often overlap.
Practical impact and recommendations
How do I verify that my content is "understandable" to Google?
First step: read the text aloud. If it doesn't sound natural, if sentences lack logical connections, Google will have the same problem. NLP tools like Hemingway, Grammarly, or French semantic analyzers (Antidote, TextRazor) detect inconsistencies.
Also check Search Console. If Google crawls your pages but doesn't index them ("Crawled, currently not indexed" status), the problem may come from semantic quality. Compare with indexed pages: is there a difference in structure, length, or coherence?
What mistakes should I absolutely avoid?
Keyword stuffing remains the first pitfall. Repeating "plumber Paris" 15 times in 200 words doesn't create meaning, just noise. Google detects it immediately.
Automatically generated content without human validation is problematic. Poor-quality text spinners, misconfigured RSS aggregators, pages created by scraping produce gibberish more often than we think.
Watch out for poorly managed multilingual pages too. If your CMS mixes French, English, and German fragments on the same page without proper hreflang tags, Google might abandon semantic analysis.
What should I do concretely?
- Review every piece of content before publication — human review remains the best filter
- Verify semantic coherence with NLP tools (Hemingway, Antidote, TextRazor)
- Check Search Console for "Crawled, not indexed" pages without obvious technical reasons
- Avoid text spinners and auto-generated content without human validation
- Structure text with Hn tags, short paragraphs, logical transitions
- Test readability with Flesch or Gunning Fog scores (although Google doesn't use them directly, they correlate with semantic coherence)
- Remove keyword stuffing and favor natural lexical fields
- Validate multilingual pages with proper hreflang tags and distinct content per language
Indexation depends on Google's ability to extract meaning. Technically perfect but semantically incoherent content will be crawled then abandoned.
Human review remains the best guarantee. NLP tools help, but don't replace the judgment of a skilled writer. If you manage a complex site with thousands of pages or highly specialized technical content, an in-depth semantic audit may be necessary — in that case, support from a specialized SEO agency will help you identify fragile areas and calibrate your editorial processes to maximize your indexation chances.
❓ Frequently Asked Questions
Google peut-il indexer une page sans la crawler ?
Un contenu généré par IA est-il considéré comme du charabia ?
Comment savoir si Google trouve mon contenu inintelligible ?
Le jargon technique ou scientifique pose-t-il problème ?
Un contenu court peut-il être considéré comme du charabia ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 19/09/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.