Official statement
What you need to understand
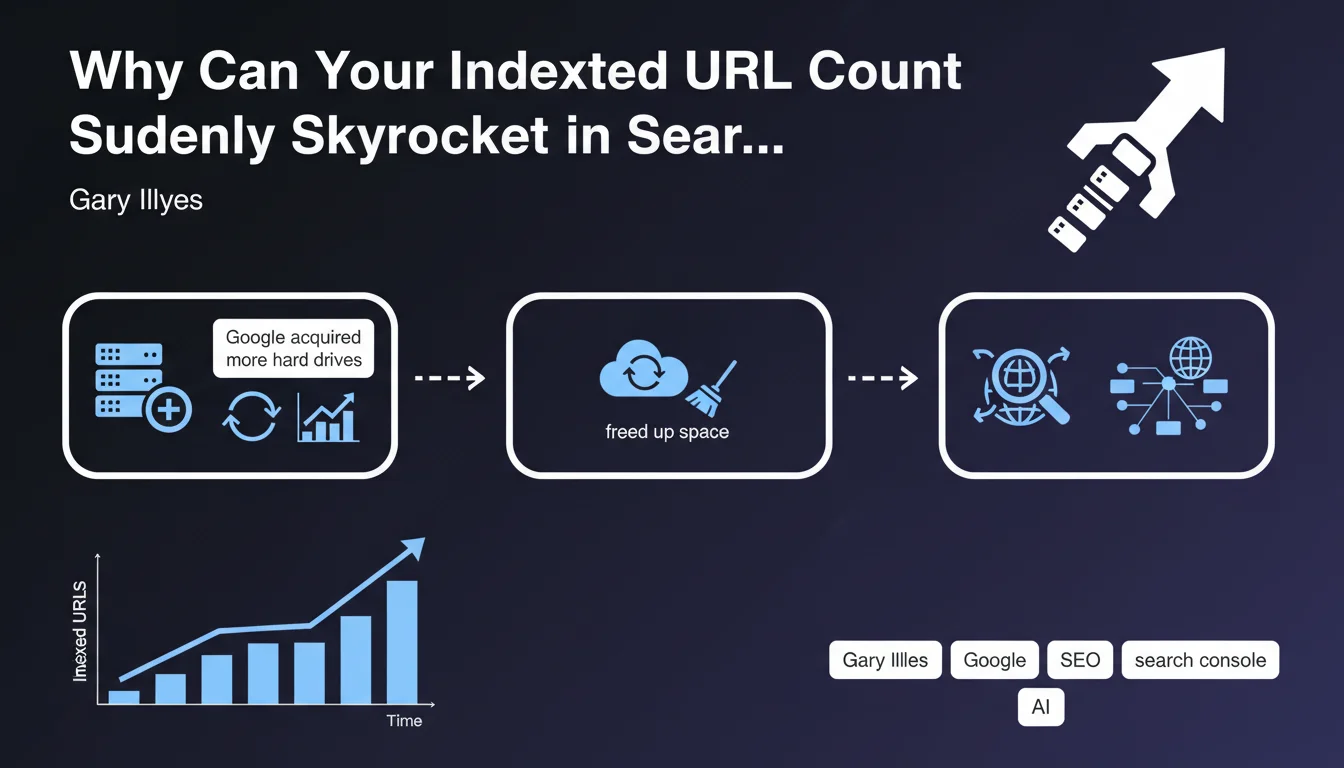
Google has shed light on a phenomenon that many SEOs regularly observe: sudden spikes in indexed URLs in Search Console. These variations can be spectacular and raise questions.
Gary Illyes identifies three main causes related to Google's infrastructure: the acquisition of new servers increasing storage capacity, the freeing up of space on existing disks, or the discovery of new URLs by crawlers. These reasons are essentially technical and independent of your site.
However, other factors directly related to your SEO optimizations can also explain these increases: improvement in content quality, resolution of technical blockages (robots.txt, meta tags), faster loading times, or a redesign of internal linking.
- Google infrastructure: storage capacity and discovery of new pages
- Site quality: content improvement and resolution of technical issues
- Technical performance: loading speed and optimized internal architecture
- Crawlability: better accessibility for indexing robots
SEO Expert opinion
This statement is perfectly consistent with real-world observations. It is indeed crucial to distinguish indexation spikes coming from improvements on Google's side (over which you have no control) from those resulting from your own optimizations.
An important nuance: a spike in indexed URLs is not always positive. If Google massively indexes low-quality or duplicate pages (infinite pagination, URL parameters, automatically generated content), it can dilute your crawl budget and harm your visibility. The goal is not to have the maximum number of indexed pages, but the right number of quality pages.
Practical impact and recommendations
When facing a significant variation in the number of indexed URLs, here are the concrete actions to implement:
- Analyze newly indexed URLs via Search Console to identify their typology and relevance
- Check your technical files (robots.txt, XML sitemaps, meta tags) to ensure no unintended modifications have occurred
- Monitor quality: make sure indexed pages provide real value and are not duplicate or thin content
- Optimize your internal linking to facilitate the discovery of strategic pages by robots
- Audit technical performance: loading times, URL structure, pagination management
- Use strategic deindexing (noindex, robots.txt) for non-relevant sections consuming crawl budget
- Monitor evolution over time: an isolated spike may be normal, a lasting trend requires action
💬 Comments (0)
Be the first to comment.