Official statement
Other statements from this video 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ La qualité d'une page détermine-t-elle vraiment le crawl des pages suivantes ?
- □ Google peut-il vraiment pénaliser certaines sections de votre site en fonction de leur qualité ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
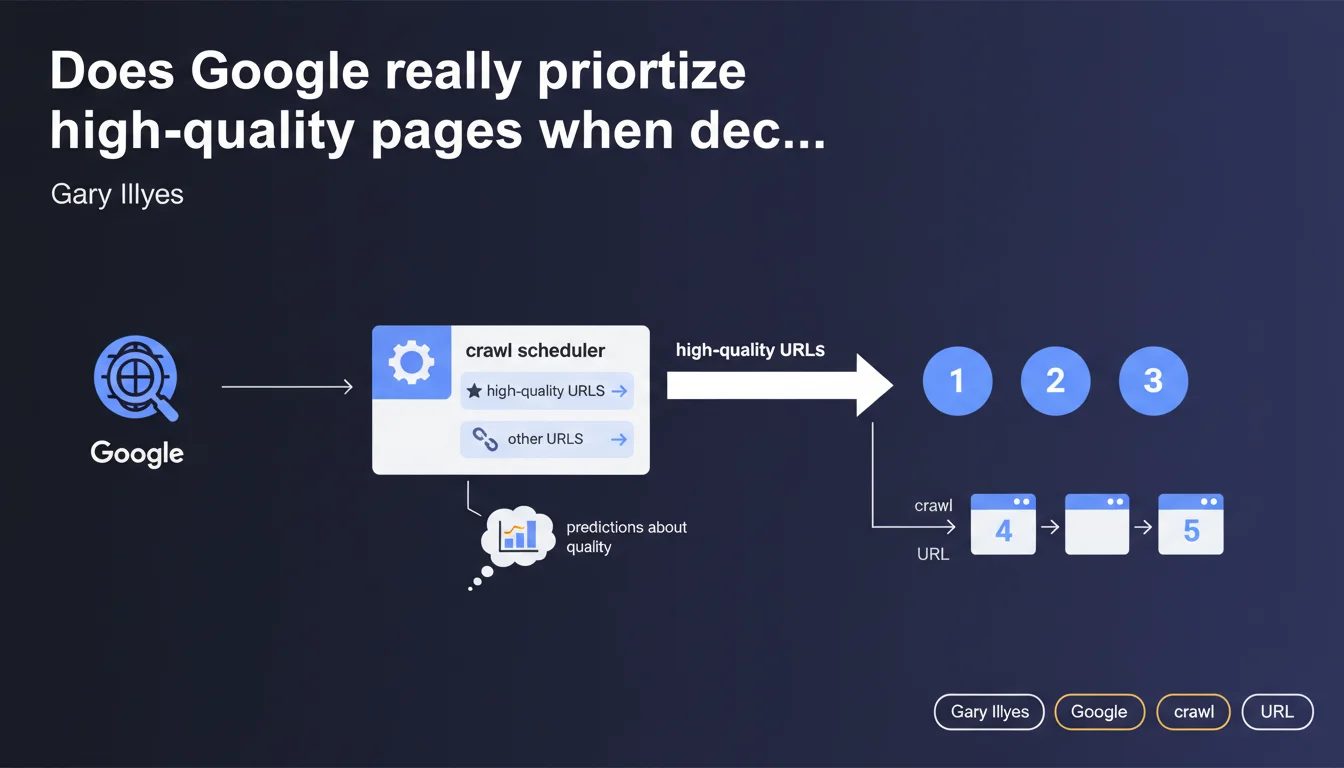
Google's crawl scheduler makes predictions about the quality of pages to crawl and establishes an ordered list of URLs to explore, with higher-quality pages being crawled first. In practice, your crawl budget directly depends on the perceived quality of your content.
What you need to understand
How does the crawl scheduler prioritize URLs?
The crawl scheduler doesn't simply follow every link it discovers blindly. It establishes an ordered queue based on quality predictions. URLs perceived as higher quality move ahead of others in the crawl queue.
This prioritization means that a site with mostly low-quality content risks having its new pages crawled more slowly, even if they're technically accessible.
What criteria determine this "predicted quality"?
Google doesn't detail its prediction criteria precisely. However, we can reasonably assume that overall site quality signals (EAT, topical authority), content freshness, user engagement signals, and historical relevance of previously crawled pages all play a role.
The system works through machine learning: if your previous content was low quality, new content risks being crawled more slowly.
What's the real impact on crawl budget?
This statement confirms that crawl budget isn't just a matter of volume. Two sites with the same number of pages won't receive equal allocation if one produces higher-quality content.
Sites with many weak or duplicate pages waste their crawl budget on content that Google actively deprioritizes.
- The crawl scheduler ranks URLs by predicted quality before exploring them
- Overall site quality influences how quickly new pages are crawled
- A history of low-quality content penalizes future crawls
- Crawl budget is allocated primarily to content deemed relevant
- Poor-quality pages may remain uncrawled for extended periods
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. We've observed for years that sites with strong authority and quality content get crawled more frequently and more deeply. Server logs clearly show that Googlebot allocates its time differently based on perceived reputation.
However, the concept of "quality prediction" remains vague. Google doesn't clarify whether this prediction happens before crawling (based on external signals) or during crawling (real-time content analysis). Likely a mix of both. [To be verified]
What nuances should we add to this claim?
Let's be honest: not all sites are treated equally. A major news site will be crawled in near-real-time even for average content, while a small site must prove its value page by page.
"Quality" remains a multidimensional and subjective concept. What's considered high-quality for an e-commerce site differs from what's considered quality for an editorial blog. Google likely adapts its criteria based on industry and content type.
Another critical point: this prioritization can create a vicious cycle. If your first pages are poorly rated, subsequent pages take longer to crawl, so they're indexed more slowly, so they generate fewer positive signals. You must break this cycle from the start.
When doesn't this rule apply fully?
Sites with high editorial freshness (news outlets, highly active forums) likely receive exceptions. Google knows that a tweet or news article must be crawled quickly, even if the site doesn't have maximum authority.
Pages linked from high-authority external sources also move faster through the queue. A backlink from a major site acts as an implicit quality signal.
Practical impact and recommendations
What should you do concretely to optimize your prioritization?
First lever: ruthlessly clean up weak content. Every mediocre indexed page tanks your overall quality score and slows crawling of your strategic content. Deindex or dramatically improve it.
Next, focus on topical coherence. A site publishing on 15 different topics without clear expertise sends contradictory signals. Better to dominate 2-3 topics than be average everywhere.
How should you structure your site to maximize crawl efficiency?
Place your strategic content at shallow depth from the homepage. Internal linking should reflect importance: priority pages should receive more internal links and internal PageRank.
Use your sitemap.xml file to explicitly flag important URLs and their update frequency. While Google doesn't blindly follow these indications, they reinforce prioritization signals.
Monitor your server logs regularly. If Googlebot only crawls certain sections monthly while you publish daily, that's a red flag: these sections are deemed low-priority.
What mistakes should you avoid at all costs?
Don't leave zombie pages indexed (obsolete content, out-of-stock product pages without redirects, unnecessary archives). They consume crawl budget and degrade your average quality score.
Avoid massive duplicate or near-duplicate content. Google wastes time crawling unnecessary variations instead of discovering your new strategic content.
Watch out for redirect chains and frequent 404 errors. They waste crawl budget and signal poor maintenance, which can degrade your overall quality score.
- Audit and deindex or improve all existing weak content
- Strengthen topical coherence and expertise in your main subjects
- Optimize internal linking to push strategic content
- Maintain an up-to-date sitemap.xml with clear prioritization of important URLs
- Analyze server logs to identify sections deprioritized by Googlebot
- Eliminate zombie pages, duplicate content, and technical errors
- Concentrate editorial efforts on fewer topics but with greater depth
❓ Frequently Asked Questions
Le crawl budget existe-t-il vraiment pour tous les sites ?
Comment savoir si mon site est pénalisé par une mauvaise prédiction de qualité ?
Les sitemaps XML influencent-ils vraiment la priorisation du crawl ?
Faut-il bloquer les pages de faible qualité dans le robots.txt ?
Un site neuf peut-il gagner rapidement en priorisation de crawl ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 19/09/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.