Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ La qualité d'une page détermine-t-elle vraiment le crawl des pages suivantes ?
- □ Google peut-il vraiment pénaliser certaines sections de votre site en fonction de leur qualité ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
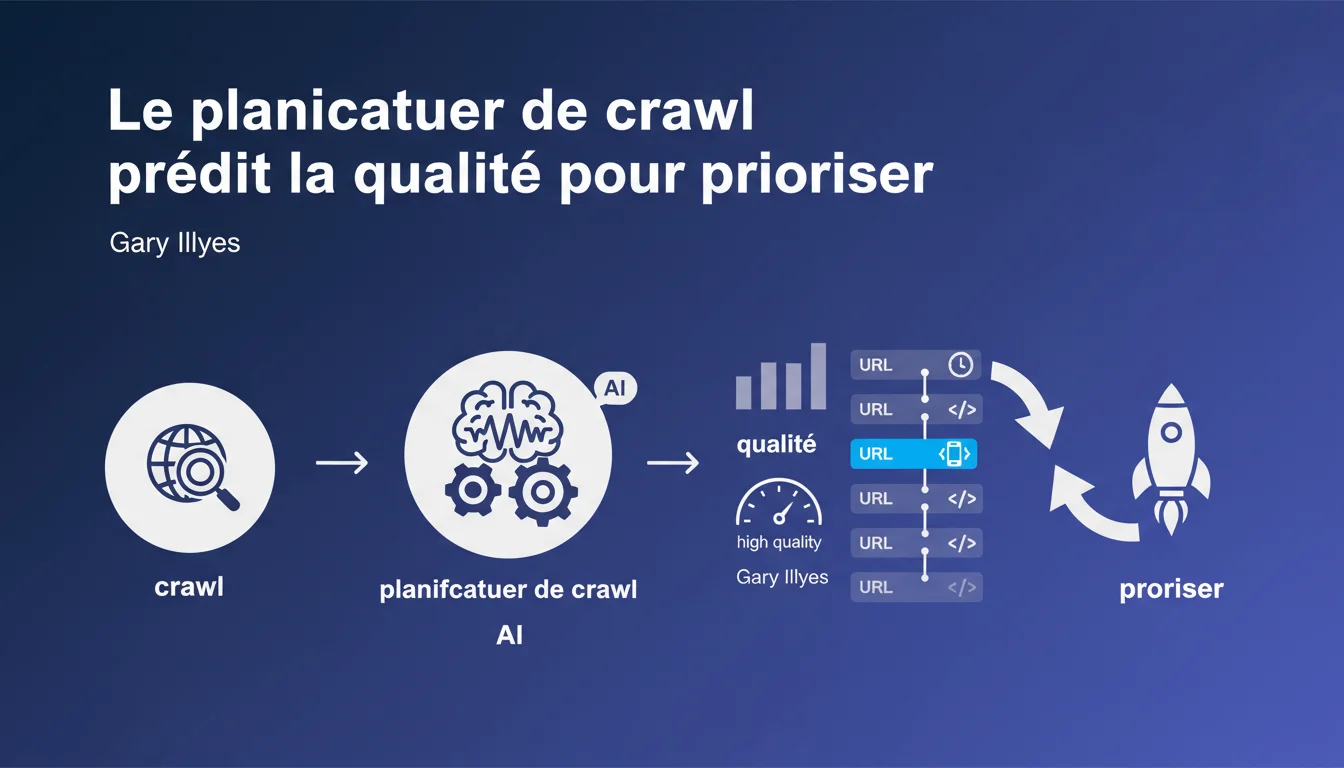
Le planificateur de crawl de Google établit une liste ordonnée d'URLs à explorer en prédisant leur qualité. Les pages jugées de meilleure qualité sont crawlées en priorité. Concrètement, votre crawl budget dépend directement de la qualité perçue de vos contenus.
Ce qu'il faut comprendre
Comment le planificateur de crawl priorise-t-il les URLs ?
Le crawl scheduler ne se contente pas de suivre aveuglément les liens qu'il découvre. Il établit une file d'attente ordonnée basée sur des prédictions de qualité. Les URLs perçues comme plus qualitatives passent devant les autres dans la liste d'exploration.
Cette priorisation signifie qu'un site avec majoritairement des contenus faibles risque de voir ses nouvelles pages crawlées plus lentement, même si elles sont techniquement accessibles.
Quels critères déterminent cette « qualité prédite » ?
Google ne détaille pas précisément ses critères de prédiction. On peut néanmoins supposer qu'interviennent des signaux de qualité globale du site (EAT, autorité thématique), la fraîcheur du contenu, les signaux d'engagement utilisateur et la pertinence historique des pages déjà crawlées.
Le système fonctionne par apprentissage : si vos précédents contenus étaient de faible qualité, les nouveaux risquent d'être crawlés moins vite.
Quel impact sur le crawl budget réel ?
Cette déclaration confirme que le crawl budget n'est pas uniquement une question de volume. Deux sites avec le même nombre de pages n'auront pas la même allocation si l'un produit du contenu de meilleure qualité.
Les sites avec beaucoup de pages faibles ou dupliquées gaspillent leur crawl budget sur du contenu que Google déprioritise activement.
- Le planificateur de crawl classe les URLs par qualité prédite avant de les explorer
- La qualité globale du site influence la vitesse de crawl des nouvelles pages
- Un historique de contenus faibles pénalise les futurs crawls
- Le crawl budget est alloué prioritairement aux contenus jugés pertinents
- Les pages de mauvaise qualité peuvent rester longtemps sans être recrawlées
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. On observe depuis des années que les sites à forte autorité et contenus de qualité se font crawler plus fréquemment et plus profondément. Les logs serveur montrent clairement que Googlebot alloue différemment son temps selon la « réputation » perçue.
Par contre, la notion de « prédiction de qualité » reste floue. Google ne dit pas si cette prédiction intervient avant le crawl (basée sur des signaux externes) ou pendant (analyse du contenu en temps réel). Probablement un mix des deux. [À vérifier]
Quelles nuances faut-il apporter à cette affirmation ?
Soyons honnêtes : tous les sites ne sont pas logés à la même enseigne. Un site d'actualité majeur sera crawlé en quasi-temps réel même pour des contenus moyens, tandis qu'un petit site devra prouver sa valeur page après page.
La « qualité » reste un concept multidimensionnel et subjectif. Ce qui est considéré comme qualitatif pour un site e-commerce n'est pas la même chose que pour un blog éditorial. Google adapte probablement ses critères selon le secteur et le type de contenu.
Autre point critique : cette priorisation peut créer un cercle vicieux. Si vos premières pages sont mal jugées, les suivantes mettent plus de temps à être crawlées, donc à être indexées, donc à générer des signaux positifs. Il faut casser ce cycle dès le départ.
Dans quels cas cette règle ne s'applique-t-elle pas pleinement ?
Les sites avec une forte fraîcheur éditoriale (actualités, forums très actifs) bénéficient probablement d'exceptions. Google sait qu'un tweet ou un article d'actualité doit être crawlé rapidement, même si le site n'a pas une autorité maximale.
Les pages liées depuis des sources externes de forte autorité passent également plus vite dans la file. Un backlink depuis un site majeur agit comme un signal de qualité implicite.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser sa priorisation ?
Premier levier : nettoyer impitoyablement les contenus faibles. Chaque page médiocre indexée plombe votre score de qualité global et ralentit le crawl de vos contenus stratégiques. Désindexez ou améliorez radicalement.
Ensuite, concentrez vos efforts sur la cohérence thématique. Un site qui publie sur 15 sujets différents sans expertise claire envoie des signaux contradictoires. Mieux vaut dominer 2-3 thématiques que d'être moyen partout.
Comment structurer son site pour maximiser l'efficacité du crawl ?
Placez vos contenus stratégiques à faible profondeur depuis la homepage. Le maillage interne doit refléter l'importance : les pages prioritaires doivent recevoir plus de liens internes et de PageRank interne.
Utilisez le fichier sitemap.xml pour signaler explicitement les URLs importantes et leur fréquence de mise à jour. Même si Google ne suit pas aveuglément ces indications, elles renforcent les signaux de priorisation.
Surveillez vos logs serveur régulièrement. Si Googlebot ne crawle certaines sections qu'une fois par mois alors que vous publiez quotidiennement, c'est un signal d'alarme : ces contenus sont jugés peu prioritaires.
Quelles erreurs éviter absolument ?
Ne pas laisser des pages zombies indexées (contenus obsolètes, pages produits épuisés sans redirection, archives inutiles). Elles consomment du crawl budget et dégradent votre score de qualité moyen.
Évitez les contenus dupliqués ou quasi-dupliqués massifs. Google va perdre du temps à crawler des variations inutiles au lieu de découvrir vos nouveaux contenus stratégiques.
Attention aux redirections en chaîne et erreurs 404 fréquentes. Elles gaspillent du crawl budget et signalent une mauvaise maintenance technique, ce qui peut dégrader votre score de qualité globale.
- Auditer et désindexer ou améliorer tous les contenus faibles existants
- Renforcer la cohérence thématique et l'expertise sur vos sujets principaux
- Optimiser le maillage interne pour pousser les contenus stratégiques
- Maintenir un sitemap.xml à jour avec priorisation claire des URLs importantes
- Analyser les logs serveur pour identifier les sections dépriorisées par Googlebot
- Éliminer les pages zombies, contenus dupliqués et erreurs techniques
- Concentrer les efforts éditoriaux sur moins de thématiques mais avec plus de profondeur
❓ Questions frequentes
Le crawl budget existe-t-il vraiment pour tous les sites ?
Comment savoir si mon site est pénalisé par une mauvaise prédiction de qualité ?
Les sitemaps XML influencent-ils vraiment la priorisation du crawl ?
Faut-il bloquer les pages de faible qualité dans le robots.txt ?
Un site neuf peut-il gagner rapidement en priorisation de crawl ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 19/09/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.