Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Google privilégie-t-il vraiment les pages de qualité dans son crawl ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ La qualité d'une page détermine-t-elle vraiment le crawl des pages suivantes ?
- □ Google peut-il vraiment pénaliser certaines sections de votre site en fonction de leur qualité ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
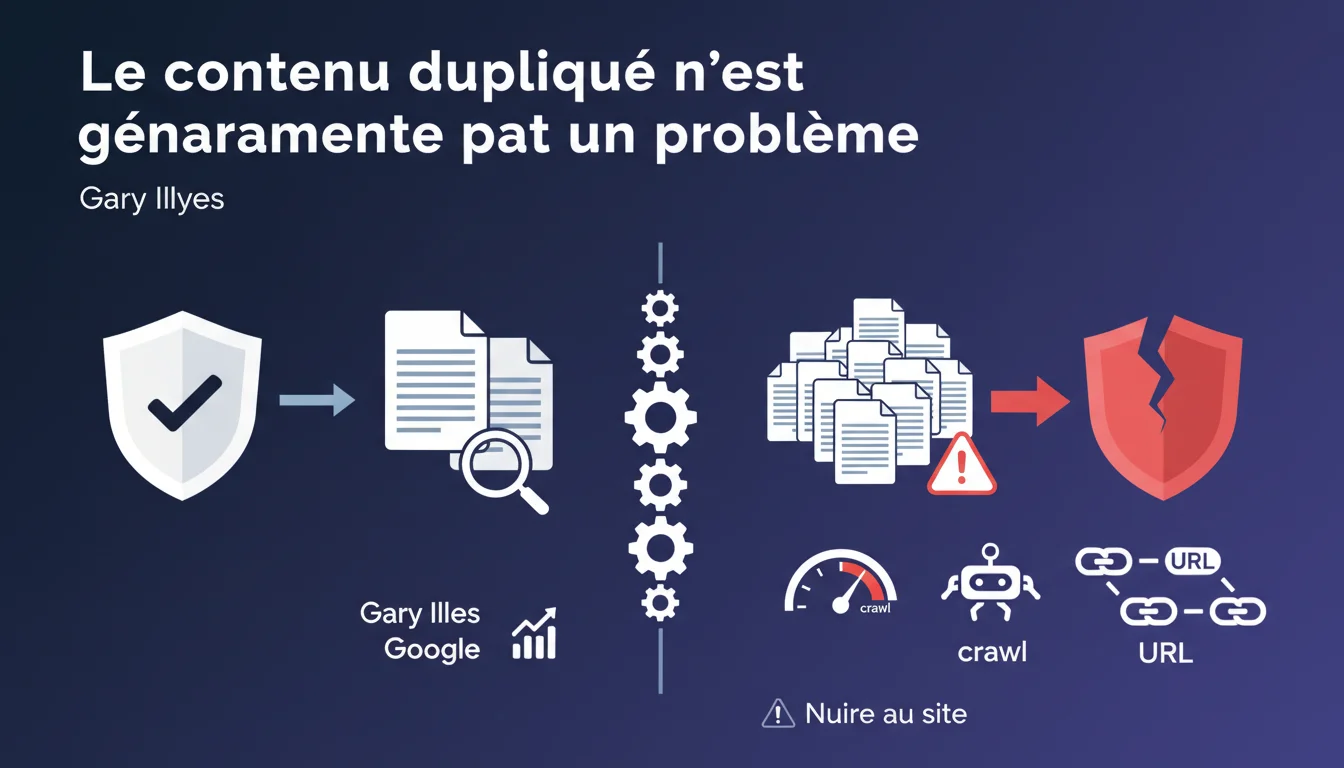
Google affirme que le contenu dupliqué n'est généralement pas un problème et fait partie du fonctionnement normal d'un site. La vraie menace ? Une multiplication excessive d'URLs qui épuise le crawl budget et dilue l'efficacité de l'exploration. La nuance est essentielle : le duplicate content n'est pas pénalisé directement, mais ses effets collatéraux peuvent saboter vos performances.
Ce qu'il faut comprendre
Pourquoi Google dédramatise-t-il le contenu dupliqué ?
Gary Illyes formule une position claire : le duplicate content fait partie de l'écosystème web normal. Les sites e-commerce avec des variantes produits, les sites multilingues, les blogs syndiqués — tous génèrent naturellement du contenu similaire ou identique.
Google ne pénalise pas cette duplication. Pas d'action manuelle, pas de déclassement automatique pour avoir des fiches produits similaires. Le moteur comprend que la réalité technique du web impose cette redondance.
Où se situe la limite entre normal et problématique ?
La déclaration introduit un point critique : l'excès accidentel de duplication. Google parle d'un moteur "très enthousiaste" à crawler les nouvelles URLs découvertes. C'est un euphémisme pour dire que Googlebot va perdre du temps sur des variations sans valeur.
Concrètement ? Si votre site génère 50 000 URLs de pagination, filtres à facettes ou sessions utilisateur, Google va tenter de tout crawler. Résultat : le crawl budget s'évapore sur du contenu redondant au lieu de se concentrer sur vos pages stratégiques.
Quelle distinction faire entre duplication interne et externe ?
La déclaration ne précise pas explicitement, mais le contexte suggère qu'on parle principalement de duplication interne — les URLs multiples d'un même site qui affichent un contenu identique ou quasi-identique.
La duplication externe (scraping, syndication, plagiat) relève d'une autre problématique. Google tente d'identifier la source originale et de privilégier celle-ci dans les SERP. Mais ici, Illyes s'adresse clairement aux webmasters qui s'inquiètent de leur propre structure technique.
- Le duplicate content n'entraîne pas de pénalité algorithmique automatique
- La multiplication excessive d'URLs dilue le crawl budget et réduit l'efficacité de l'indexation
- Google différencie le contenu dupliqué normal (variations techniques légitimes) du spam manipulateur
- Le vrai risque est l'inefficacité : Google crawle moins bien vos pages importantes
- Les canonicales et robots.txt restent vos outils principaux pour gérer cette duplication
Avis d'un expert SEO
Cette position de Google est-elle cohérente avec ce qu'on observe sur le terrain ?
Oui, globalement. Les sites avec du duplicate content modéré ne subissent pas d'effondrement brutal dans les SERP. Aucune pénalité Panda n'est documentée uniquement sur la base de contenu dupliqué interne depuis des années.
Par contre — et c'est là que la déclaration mérite un complément — on observe régulièrement des sites où Google indexe les mauvaises versions de pages. Des URLs de pagination qui cannibalisent les pages catégories principales, des variantes produit qui se battent entre elles pour le même mot-clé. Pas de pénalité, mais une inefficacité structurelle qui plombe les performances.
Que signifie vraiment "très enthousiaste à crawler" ?
C'est une formulation volontairement douce pour décrire un problème concret : Googlebot suit avidement chaque lien découvert, sans toujours distinguer une URL stratégique d'une variante parasite. Si vous avez 10 URLs qui affichent le même contenu, Google va dépenser du crawl budget sur les 10.
Soyons honnêtes : cette "enthousiasme" n'est pas un bug, c'est une caractéristique. Google privilégie l'exhaustivité de la découverte. À vous de structurer votre site pour orienter cette exploration vers ce qui compte. [À vérifier] : la déclaration ne précise pas si Google a amélioré sa capacité à détecter automatiquement les clusters de duplication sans balises explicites.
Dans quels cas cette règle ne s'applique-t-elle pas ?
La déclaration évoque le contenu dupliqué "normal". Mais qu'est-ce qui bascule du côté anormal ? Le spam de duplication à grande échelle — scraper 1 000 sites pour republier leur contenu — reste dans le viseur des actions manuelles.
De même, si votre site entier est un miroir d'un autre domaine, Google ne va pas vous pénaliser techniquement, mais il ne vous indexera probablement pas non plus. Il choisira la source qu'il juge originale ou autoritaire. Et c'est là que ça coince : Illyes dit "pas de problème", mais omet de préciser que ne pas être pénalisé n'est pas synonyme d'être bien classé.
Impact pratique et recommandations
Que faut-il faire concrètement pour gérer le contenu dupliqué ?
Première étape : identifier les clusters de duplication sur votre site. Utilisez Screaming Frog ou OnCrawl pour repérer les URLs qui partagent un contenu identique ou quasi-identique. Focalisez-vous d'abord sur les pages stratégiques — catégories, fiches produit phares, landing pages.
Ensuite, hiérarchisez. Toutes les duplications ne se valent pas. Des URLs de session utilisateur ou des variantes de tri ? Bloquez-les en robots.txt ou via noindex. Des variantes produit légitimes avec des différences mineures ? Implémentez des canonicales vers la version principale.
Quelles erreurs critiques éviter absolument ?
Ne pas utiliser de canonicales circulaires ou contradictoires. J'ai vu des sites où la page A pointe vers B en canonical, et B vers A. Google ignore ces signaux et choisit arbitrairement. Résultat : imprévisibilité totale dans l'indexation.
Autre piège : bloquer du contenu dupliqué en robots.txt ET ajouter une canonical. Google ne peut pas crawler la page bloquée pour lire la balise canonical — le signal est perdu. Si vous voulez consolider, laissez Google accéder à la page et guider avec la canonical.
Comment vérifier que votre gestion du duplicate content est efficace ?
Surveillez le taux d'indexation dans la Search Console. Si Google indexe 80 000 pages alors que vous n'en avez que 20 000 de stratégiques, vous avez un problème de duplication non maîtrisée. Regardez les "Pages explorées, actuellement non indexées" — souvent, ce sont des duplications que Google a crawlées puis écartées.
Analysez aussi les requêtes qui déclenchent l'affichage de versions non souhaitées. Si vos URLs de pagination ou de filtres apparaissent dans les SERP au lieu des pages principales, c'est que vos signaux de consolidation (canonical, noindex) ne fonctionnent pas comme prévu.
- Auditer les clusters de duplication avec un crawler technique
- Implémenter des canonicales cohérentes vers les versions principales
- Bloquer en robots.txt les URLs de session, paramètres inutiles, variations de tri
- Vérifier que les canonicales ne sont pas circulaires ou contradictoires
- Monitorer le taux d'indexation réel vs URLs stratégiques dans la Search Console
- Analyser les logs serveur pour repérer les crawls excessifs sur du contenu redondant
- Tester régulièrement les SERP pour vérifier que Google affiche les bonnes versions
❓ Questions frequentes
Le contenu dupliqué entraîne-t-il une pénalité Google ?
Quelle est la différence entre duplication interne et externe ?
Les balises canonical suffisent-elles pour gérer le contenu dupliqué ?
Comment savoir si mon contenu dupliqué affecte mes performances ?
Le contenu syndiqué compte-t-il comme duplication problématique ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 19/09/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.