Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google privilégie-t-il vraiment les pages de qualité dans son crawl ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ La qualité d'une page détermine-t-elle vraiment le crawl des pages suivantes ?
- □ Google peut-il vraiment pénaliser certaines sections de votre site en fonction de leur qualité ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
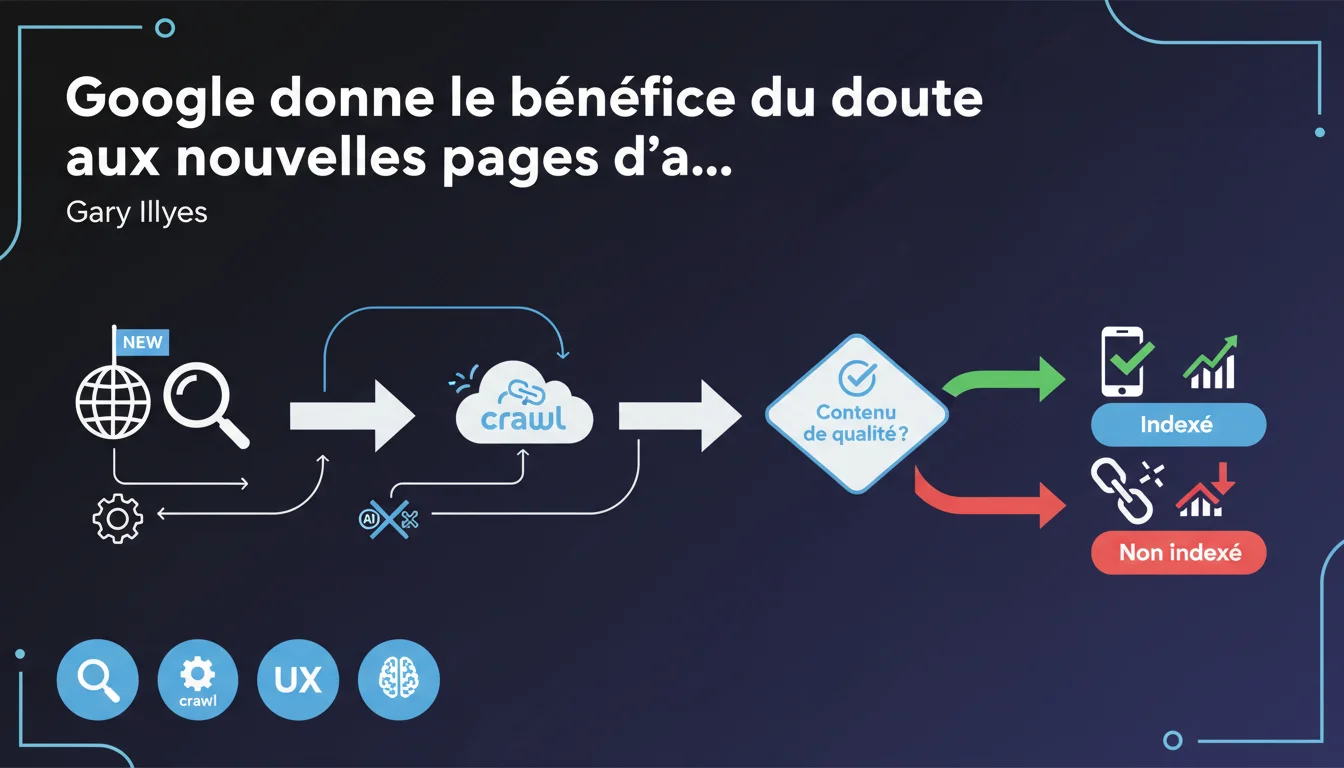
Gary Illyes affirme que Google crawle les pages d'accueil de nouveaux sites sans biais préalable et leur donne le bénéfice du doute pour l'indexation. Seul un contenu de très mauvaise qualité bloquerait cette indexation initiale. Une affirmation qui soulève des questions sur ce que Google considère réellement comme « très mauvaise qualité ».
Ce qu'il faut comprendre
Que signifie concrètement « donner le bénéfice du doute » ?
Google admet ici qu'il ne peut pas évaluer la qualité d'un nouveau site avant de l'avoir crawlé. La page d'accueil bénéficie donc d'un traitement neutre initial — aucun filtre préventif ne l'empêche d'entrer dans l'index.
Cette approche contraste avec d'autres scénarios où Google applique des prédictions basées sur des signaux externes (domaine expiré racheté, réseau de sites détecté, patterns suspects). Pour une homepage totalement nouvelle, ces signaux n'existent pas encore.
Qu'est-ce qu'un contenu de « très mauvaise qualité » selon Google ?
La formulation reste floue. On peut supposer qu'il s'agit de pages vides, de spam évident, de scraping massif ou de contenu auto-généré sans valeur. Mais la limite exacte n'est pas définie. [À vérifier]
L'historique montre que Google indexe régulièrement des pages médiocres — le vrai tri se fait après, via les mises à jour algorithmiques. L'indexation initiale n'est donc pas un gage de qualité.
Cette déclaration s'applique-t-elle uniquement aux homepages ?
Oui, et c'est un point crucial. Illyes parle spécifiquement des pages d'accueil de nouveaux sites. Les pages internes, elles, dépendent du crawl budget, de la profondeur de liens, de la qualité perçue du site.
Un nouveau site avec une homepage indexée rapidement peut très bien voir ses pages secondaires ignorées pendant des semaines si la structure est faible ou si le contenu ne justifie pas un crawl approfondi.
- Google crawle les nouvelles homepages sans biais algorithmique préalable
- L'indexation initiale ne garantit pas un positionnement favorable
- Seul un contenu ouvertement spam bloquerait l'indexation — la barre est basse
- Cette règle ne s'étend pas automatiquement aux pages internes
- Le vrai test de qualité intervient après l'indexation, lors des évaluations algorithmiques
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Partiellement. Dans la pratique, on observe effectivement que la plupart des nouvelles homepages sont crawlées et indexées en quelques jours — même pour des sites très modestes. Rien de surprenant ici.
En revanche, l'affirmation selon laquelle il n'y a « ni biais ni prédictions préalables » mérite des nuances. Google analyse le nom de domaine (historique WHOIS, similarité avec des domaines sanctionnés), les premiers backlinks pointant vers le site, et peut très bien appliquer un filtre si des signaux négatifs apparaissent dès le départ.
Quelles limites faut-il poser à cette affirmation ?
Le « bénéfice du doute » ne signifie pas traitement équitable. Un nouveau site sans autorité, sans backlinks, sans historique restera en bas de classement même s'il est techniquement indexé. L'indexation n'est qu'une première étape administrative, pas une validation de qualité.
De plus, la notion de « très mauvaise qualité » reste un critère subjectif et opaque. Google ne fournit aucune métrique concrète — un site jugé acceptable aujourd'hui peut être rétrogradé demain si un filtre se déclenche. [À vérifier]
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si le site est lancé sur un domaine ayant un historique toxique (spam, pénalité manuelle antérieure), le bénéfice du doute peut sauter. Si le site appartient à un réseau de sites détecté par Google, le crawl peut être retardé ou filtré.
Enfin, un site sans aucun signal de découvrabilité — zéro backlink, non déclaré dans Search Console, sitemap absent — peut rester invisible plusieurs semaines, même si techniquement Google pourrait le crawler.
Impact pratique et recommandations
Que faut-il faire concrètement pour maximiser cette fenêtre de bienveillance ?
Puisque Google crawle la homepage sans préjugé, autant optimiser cette première impression. Le contenu de la page d'accueil doit être clair, structuré, et signaler immédiatement la thématique du site. Pas de placeholder générique, pas de « site en construction ».
Déclarer le site dans Search Console dès le lancement et soumettre le sitemap XML accélère le processus. Même si Google finit par découvrir le site naturellement, pourquoi attendre ?
Quelles erreurs éviter pour ne pas gâcher ce bénéfice du doute ?
Ne pas lancer un site avec une homepage vide ou quasi-vide. Google peut indexer la page, mais si elle ne contient que quelques lignes de texte générique, l'algorithme la classera comme low-quality content dès la première évaluation.
Éviter également de lancer un site avec des dizaines de pages internes de mauvaise qualité — même si la homepage passe, les signaux agrégés du site peuvent rapidement déclencher un filtre de qualité global.
Comment vérifier que mon site profite bien de ce traitement neutre ?
Surveiller l'indexation dans Search Console. Si la homepage n'apparaît pas dans l'index sous 7 à 10 jours, c'est soit un problème technique (robots.txt, noindex accidentel), soit un signal négatif détecté par Google.
Utiliser site:votredomaine.com dans Google pour confirmer l'indexation. Si la page apparaît mais ne se positionne sur aucun mot-clé, même branded, c'est un indicateur que le bénéfice du doute ne s'étend pas au classement.
- Créer une homepage avec un contenu substantiel et structuré avant le lancement
- Déclarer le site dans Search Console et soumettre le sitemap dès le premier jour
- Vérifier l'absence de directives bloquantes (robots.txt, balise noindex)
- Ajouter quelques backlinks initiaux depuis des sources légitimes pour accélérer la découverte
- Surveiller l'indexation sous 7 jours — si rien n'apparaît, diagnostiquer rapidement
- Ne pas se reposer uniquement sur l'indexation : produire du contenu pertinent rapidement pour valider la qualité perçue
❓ Questions frequentes
Est-ce que Google crawle toutes les nouvelles homepages automatiquement ?
Une homepage indexée rapidement garantit-elle un bon classement ?
Qu'est-ce qui bloque réellement l'indexation d'une nouvelle homepage ?
Les pages internes bénéficient-elles aussi de ce traitement neutre ?
Faut-il attendre avant de soumettre un nouveau site à Google ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 19/09/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.