Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Google privilégie-t-il vraiment les pages de qualité dans son crawl ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ Google peut-il vraiment pénaliser certaines sections de votre site en fonction de leur qualité ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
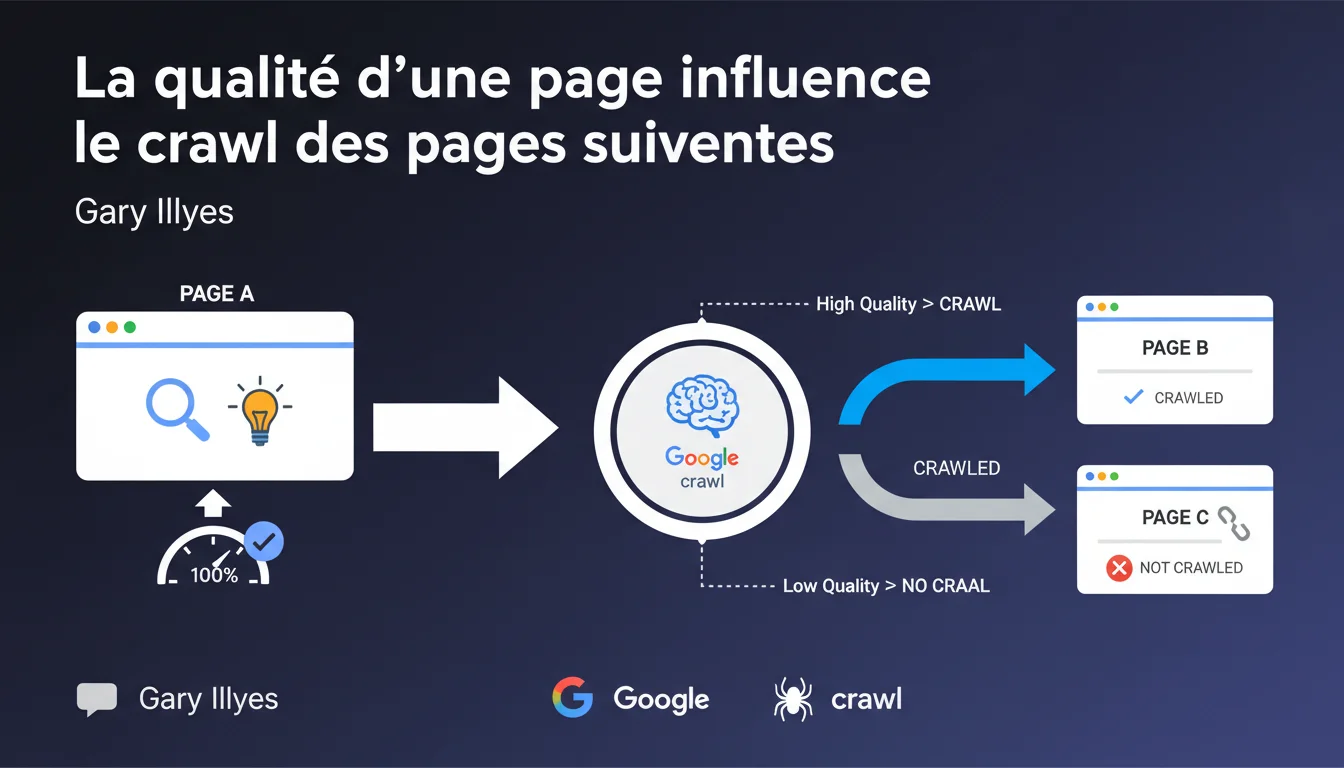
Google utilise la qualité des pages déjà crawlées (notamment la homepage) pour prédire si une nouvelle page découverte mérite d'être explorée. Un signal de qualité faible sur les pages d'entrée peut limiter le crawl des pages suivantes, indépendamment de leur propre qualité intrinsèque.
Ce qu'il faut comprendre
Comment Google évalue-t-il cette "qualité" pour prédire le crawl ?
Gary Illyes reste délibérément vague sur les critères précis. On peut supposer qu'il s'agit d'une combinaison de signaux : expérience utilisateur (Core Web Vitals, temps de chargement), qualité du contenu, maillage interne cohérent, absence de spam. Mais aucun détail technique n'est fourni.
Le terme "prédire" est central. Google utilise un modèle prédictif : si la homepage ou les pages précédemment crawlées affichent des signaux de qualité faibles, l'algorithme anticipe que les pages suivantes seront probablement du même acabit. C'est une logique d'efficacité — pourquoi gaspiller du crawl budget sur un site qui semble médiocre ?
Pourquoi la homepage joue-t-elle un rôle aussi déterminant ?
La homepage est souvent le premier point de contact de Googlebot avec un site. C'est la vitrine. Si cette vitrine est mal fichue — lente, bourée de JS bloquant, contenu creux — Google en tire une conclusion rapide : le reste du site ne vaut probablement pas mieux.
Les "pages précédentes" mentionnées par Illyes font référence au parcours de crawl. Si Googlebot découvre une nouvelle URL via une page déjà jugée faible, il hérite de ce contexte négatif. C'est un effet domino.
Quelles sont les implications concrètes pour le crawl budget ?
Cette déclaration confirme ce qu'on observe terrain : tous les sites n'ont pas un crawl budget infini. Google alloue des ressources en fonction de la "valeur" perçue. Un site de mauvaise qualité se verra explorer moins profondément, moins fréquemment.
- La qualité des pages d'entrée (homepage, pages de catégorie) impacte directement le crawl des pages orphelines ou profondes
- Un site peut avoir d'excellentes pages en profondeur qui ne seront jamais découvertes si les pages de surface sont faibles
- Le maillage interne devient critique : une page de qualité peut "porter" les pages suivantes dans la chaîne de crawl
- Cette logique prédictive explique pourquoi certains sites voient leurs nouvelles pages indexées en quelques heures, d'autres en plusieurs semaines
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées ?
Oui, et c'est même une confirmation officielle de ce qu'on constate depuis des années. Les sites avec une homepage lente, mal structurée ou pauvre en contenu ont systématiquement des problèmes d'indexation en profondeur. Les logs serveur le montrent : Googlebot ralentit son rythme après quelques pages médiocres.
Mais — et c'est là où ça coince — Illyes ne donne aucun seuil. Qu'est-ce qu'une "mauvaise" qualité pour Google ? Un Core Web Vitals rouge ? Un taux de rebond élevé ? Un contenu dupliqué partiel ? On reste dans le flou. [A vérifier] : les critères précis restent opaques.
Quelles nuances faut-il apporter à cette règle ?
Première nuance : cette logique prédictive n'est pas une fatalité définitive. Si Google découvre une nouvelle page via un backlink externe de qualité, le contexte change. La page hérite alors de la confiance du site qui la recommande, pas seulement de celle des pages précédentes du même domaine.
Deuxième nuance : la "qualité" n'est pas statique. Si tu améliores massivement ta homepage et tes pages piliers, Google réévaluera progressivement son approche de crawl. Mais ce n'est pas instantané — il faut du temps pour inverser une réputation établie.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Les sites avec une autorité de domaine très élevée bénéficient d'un passe-droit. Un média comme Le Monde peut avoir une page moyenne médiocre, Google crawlera quand même massivement le site. L'historique et la confiance globale l'emportent.
Les pages découvertes via Google Search Console (URL Inspection Tool) court-circuitent cette logique. Tu forces manuellement le crawl, indépendamment du contexte de qualité. Idem pour les sitemaps XML bien configurés : ils signalent une priorité explicite.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl de son site ?
Commence par la homepage. C'est ton levier principal. Si elle est pourrie, tout le reste est compromis. Optimise les Core Web Vitals, allège le DOM, réduis les scripts tiers. Mets du contenu de qualité dès la home — pas juste un carrousel d'images et trois CTA vagues.
Ensuite, structure ton maillage interne pour que les pages stratégiques soient accessibles en 2-3 clics maximum depuis la home. Les pages orphelines sont des pages invisibles pour Google, peu importe leur qualité intrinsèque.
Utilise les logs serveur pour identifier les pages que Googlebot visite et celles qu'il ignore. Si des sections entières ne sont jamais crawlées, c'est un signal que les pages d'entrée vers ces sections sont jugées faibles.
Quelles erreurs éviter pour ne pas saboter son crawl budget ?
Ne néglige jamais les pages de catégorie ou les pages intermédiaires. Beaucoup de sites focalisent tout sur les fiches produits ou articles, mais si les pages de catégorie sont médiocres, Google ne descendra pas jusqu'aux produits.
Évite les contenus dupliqués ou quasi-dupliqués sur les pages d'entrée. Si Google crawle trois variantes de ta homepage (www, non-www, https, http) et qu'elles sont toutes moyennes, tu cumules les handicaps.
- Auditer la homepage et les pages de catégorie principales avec PageSpeed Insights et Lighthouse
- Vérifier que les pages stratégiques sont accessibles en 2-3 clics depuis la home
- Analyser les logs serveur pour identifier les zones sous-crawlées
- Éliminer tout contenu dupliqué ou thin content sur les pages d'entrée
- Tester l'accessibilité des pages importantes via Google Search Console (URL Inspection)
- Améliorer le maillage interne pour créer des chemins de crawl clairs vers les pages profondes
Comment vérifier que mon site est conforme à cette logique de crawl ?
Compare le taux de crawl dans Google Search Console avec le volume de pages réellement importantes sur ton site. Si 80 % de ton crawl budget est gaspillé sur des URLs inutiles (pagination, facettes, paramètres), c'est un signal d'alarme.
Regarde la vitesse d'indexation de nouvelles pages. Si une page publiée met plus de 48h à être indexée alors qu'elle est bien maillée, c'est probablement un problème de perception de qualité sur les pages précédentes du parcours.
Cette déclaration confirme que Google évalue la qualité de manière holistique : une page isolée ne suffit pas, c'est tout le contexte de crawl qui compte. Les sites avec une homepage et des pages piliers solides bénéficient d'un crawl plus agressif et plus profond. À l'inverse, une homepage faible agit comme un frein pour tout le reste du site.
Ces optimisations croisées — qualité technique, contenu, maillage interne — demandent une expertise pointue et une coordination entre plusieurs métiers (SEO, dev, UX). Si ton équipe interne manque de ressources ou de compétences sur l'un de ces axes, un accompagnement par une agence SEO spécialisée peut accélérer sensiblement les résultats et éviter des erreurs coûteuses.
❓ Questions frequentes
Google crawle-t-il toujours toutes les pages d'un site ?
Une excellente page profonde peut-elle être ignorée si la homepage est médiocre ?
Le maillage interne peut-il compenser une homepage de faible qualité ?
Les backlinks externes peuvent-ils court-circuiter cette logique prédictive ?
Combien de temps faut-il pour inverser une mauvaise réputation de crawl ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 19/09/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.