Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Le crawl intensif garantit-il vraiment un site de qualité ?
- □ Faut-il forcer Google à crawler davantage pour améliorer son classement ?
- □ Peut-on vraiment augmenter le crawl budget de son site en contactant Google ?
- □ Pourquoi Google insiste-t-il sur l'implémentation du header If-Modified-Since ?
- □ Les paramètres d'URL créent-ils vraiment un espace de crawl infini pour Google ?
- □ Pourquoi les hashtags et ancres d'URL compliquent-ils le crawl de Google ?
- □ Pourquoi Google insiste-t-il autant sur les statistiques d'exploration dans Search Console ?
- □ Pourquoi un temps de réponse serveur lent tue-t-il votre crawl budget ?
- □ Googlebot suit-il vraiment les liens comme un utilisateur navigue de page en page ?
- □ Faut-il vraiment optimiser le crawl budget si Google a des ressources illimitées ?
- □ Les sitemaps sont-ils vraiment indispensables pour optimiser le crawl de votre site ?
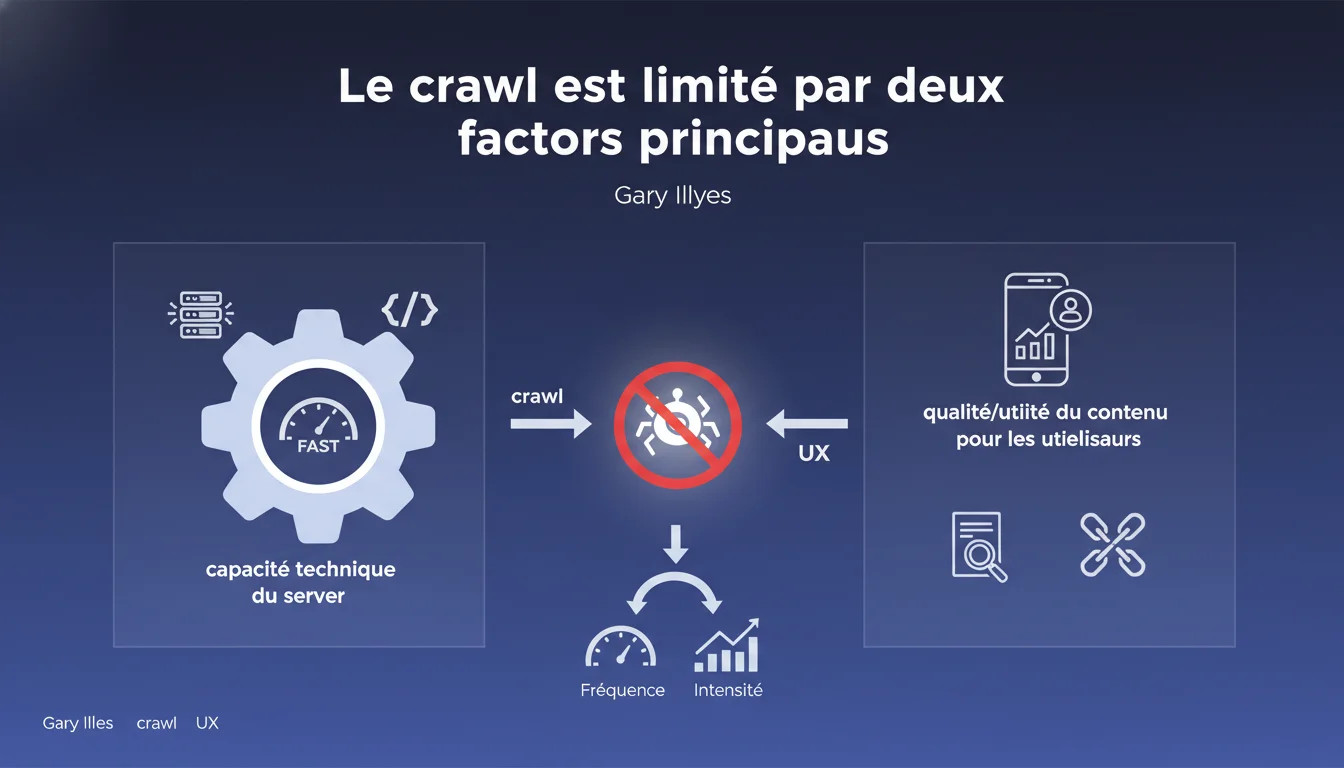
Google limite le volume de crawl en fonction de deux facteurs : la capacité technique de votre serveur à traiter les requêtes, et la qualité perçue du contenu pour les utilisateurs. Un serveur lent ou instable freine Googlebot, même si le contenu est excellent. À l'inverse, un serveur performant ne compense pas un contenu médiocre.
Ce qu'il faut comprendre
Qu'est-ce que le crawl budget et pourquoi Google le limite-t-il ?
Le crawl budget correspond au nombre de pages que Googlebot accepte de visiter sur votre site pendant une période donnée. Cette limitation existe pour deux raisons : Google ne dispose pas de ressources infinies, et il préfère concentrer son énergie sur les contenus utiles plutôt que d'épuiser vos serveurs.
Cette déclaration de Gary Illyes officialise ce que beaucoup observaient déjà — mais avec un détail crucial. Google ne limite pas le crawl par caprice ou algorithme obscur. Il réagit d'abord à ce que votre infrastructure lui permet, puis à la valeur réelle de vos pages pour les internautes.
Comment la capacité technique limite-t-elle concrètement le crawl ?
Si votre serveur renvoie des erreurs 5xx, des timeouts ou des temps de réponse catastrophiques, Googlebot ralentit automatiquement le rythme. C'est une protection : il ne veut pas contribuer à planter votre site. Le problème ? Un serveur qui rame sabote votre indexation, même si vous publiez du contenu exceptionnel.
Google ajuste son comportement en temps réel. Un serveur stable et rapide obtient un crawl plus agressif. Un serveur capricieux ? Googlebot devient prudent et réduit la fréquence. Cette autorégulation signifie que votre infrastructure joue un rôle direct dans votre visibilité.
Qu'entend Google par « qualité et utilité du contenu » ?
C'est le second facteur — et le plus flou. Google évalue si vos pages méritent d'être crawlées souvent en fonction de signaux comme le taux de mise à jour, l'engagement des utilisateurs, la fraîcheur, ou encore la popularité. Un blog qui publie chaque jour aura un crawl plus intense qu'un site statique inchangé depuis 2 ans.
Mais attention : quantité ne veut pas dire qualité. Publier 50 pages médiocres quotidiennement ne garantit pas un crawl plus fréquent. Google privilégie les sites dont les contenus génèrent des interactions, des clics, du temps de lecture. Si vos pages ne servent personne, Googlebot finit par espacer ses visites.
- Le crawl budget est limité par deux piliers : performance technique du serveur et pertinence du contenu pour les utilisateurs.
- Un serveur lent bride l'indexation, même si le contenu est excellent — et réciproquement.
- Google ajuste le crawl en temps réel selon la stabilité de votre infrastructure.
- La qualité du contenu se mesure en signaux d'engagement et de fraîcheur, pas uniquement en volume de pages.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, globalement. Les audits montrent que les sites avec des temps de réponse serveur catastrophiques (>2s) subissent un ralentissement visible du crawl. Google Search Console le confirme avec des graphiques qui plongent quand les erreurs 5xx grimpent. Rien de neuf ici — sauf que Gary Illyes formalise enfin ce qui relevait de l'empirisme.
Par contre, le second facteur — la « qualité/utilité du contenu » — reste volontairement vague. Google ne donne aucun seuil, aucun indicateur mesurable. Est-ce que 1000 visiteurs/jour suffisent ? Est-ce que le taux de rebond compte ? On navigue en aveugle. [A vérifier] : Google n'a jamais publié de liste de critères précis pour ce volet.
Quelles nuances faut-il apporter à cette règle ?
La déclaration oublie un troisième facteur observé sur le terrain : la structure du site. Un maillage interne chaotique, des URLs orphelines ou une profondeur de clic excessive freinent le crawl, même avec un serveur rapide et du contenu pertinent. Googlebot ne trouve tout simplement pas certaines pages.
Autre point — les sites avec un historique de spam ou de contenu dupliqué massif subissent parfois un bridage du crawl qui ne s'explique ni par la technique ni par la qualité actuelle. Google semble appliquer une forme de « punition résiduelle » même après nettoyage. Ça reste officieux, mais les cas sont documentés.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Les très gros sites (millions de pages) jouent avec des règles différentes. Google utilise des systèmes de priorisation algorithmique qui vont bien au-delà du simple couple serveur/qualité. Par exemple, un e-commerce géant avec 10 millions de produits ne sera pas crawlé uniformément — Google cible les catégories populaires et laisse de côté les pages à faible trafic.
Les sites d'actualité bénéficient aussi d'un traitement spécial. Même si leur infrastructure n'est pas parfaite, Google crawle certaines sections en quasi temps réel parce que la fraîcheur prime. Le facteur « utilité » devient alors prépondérant, au point de tolérer quelques lenteurs serveur.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl ?
Première étape : diagnostiquer la santé technique de votre serveur. Utilisez Google Search Console pour repérer les pics d'erreurs 5xx, les timeouts et les temps de téléchargement anormaux. Si votre serveur plafonne à 500ms de temps de réponse, vous laissez de la marge à Googlebot. Au-delà de 1,5s, vous commencez à freiner le crawl.
Ensuite, auditez vos logs serveur pour identifier les pages que Googlebot visite réellement. Souvent, il perd du temps sur des URLs inutiles — filtres, paramètres de session, pages paginées infinies. Bloquez ces sections via robots.txt ou des directives noindex pour rediriger le crawl vers les pages stratégiques.
Quelles erreurs éviter absolument ?
Ne bradez pas votre crawl budget en publiant des centaines de pages quasi identiques ou à faible valeur ajoutée. Google finit par considérer votre site comme du bruit et réduit la fréquence de crawl. Mieux vaut 50 pages excellentes que 500 pages médiocres.
Évitez aussi les redirections en chaîne (A → B → C → D). Googlebot suit les redirections, mais chaque saut consomme du crawl budget et ralentit la découverte de vos contenus. Nettoyez impitoyablement : une redirection = une seule étape.
Comment vérifier que mon site est conforme ?
Dans Google Search Console, consultez le rapport « Statistiques d'exploration ». Vous y trouvez trois courbes : nombre de requêtes crawlées, Ko téléchargés, et temps de réponse moyen. Un crawl qui s'effondre sans raison apparente ? Cherchez du côté des erreurs serveur ou d'une chute de trafic/engagement.
Comparez aussi la fréquence de crawl avec votre rythme de publication. Si vous publiez 10 articles/semaine mais que Googlebot ne passe que 2 fois/mois sur ces sections, il y a un décalage. Posez-vous la question : ces contenus génèrent-ils vraiment de l'intérêt, ou est-ce du remplissage ?
- Auditer les logs serveur pour identifier les URLs inutilement crawlées
- Bloquer via robots.txt les sections non stratégiques (filtres, paramètres de session)
- Réduire le temps de réponse serveur sous 1s si possible
- Nettoyer les redirections en chaîne et les erreurs 4xx/5xx récurrentes
- Consolider ou supprimer les pages à faible valeur ajoutée ou dupliquées
- Surveiller le rapport « Statistiques d'exploration » dans Google Search Console
- Améliorer le maillage interne pour faciliter la découverte des nouvelles pages
❓ Questions frequentes
Un serveur ultra-rapide garantit-il un crawl budget élevé ?
Google crawle-t-il toutes les pages d'un site de la même manière ?
Le crawl budget impacte-t-il directement le classement dans les résultats ?
Combien de temps faut-il pour que Google ajuste le crawl après une optimisation serveur ?
Les sites de petite taille doivent-ils s'inquiéter du crawl budget ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.