Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Le crawl intensif garantit-il vraiment un site de qualité ?
- □ Faut-il forcer Google à crawler davantage pour améliorer son classement ?
- □ Peut-on vraiment augmenter le crawl budget de son site en contactant Google ?
- □ Pourquoi Google crawle-t-il certains sites plus souvent que d'autres ?
- □ Pourquoi Google insiste-t-il sur l'implémentation du header If-Modified-Since ?
- □ Les paramètres d'URL créent-ils vraiment un espace de crawl infini pour Google ?
- □ Pourquoi les hashtags et ancres d'URL compliquent-ils le crawl de Google ?
- □ Pourquoi Google insiste-t-il autant sur les statistiques d'exploration dans Search Console ?
- □ Pourquoi un temps de réponse serveur lent tue-t-il votre crawl budget ?
- □ Googlebot suit-il vraiment les liens comme un utilisateur navigue de page en page ?
- □ Les sitemaps sont-ils vraiment indispensables pour optimiser le crawl de votre site ?
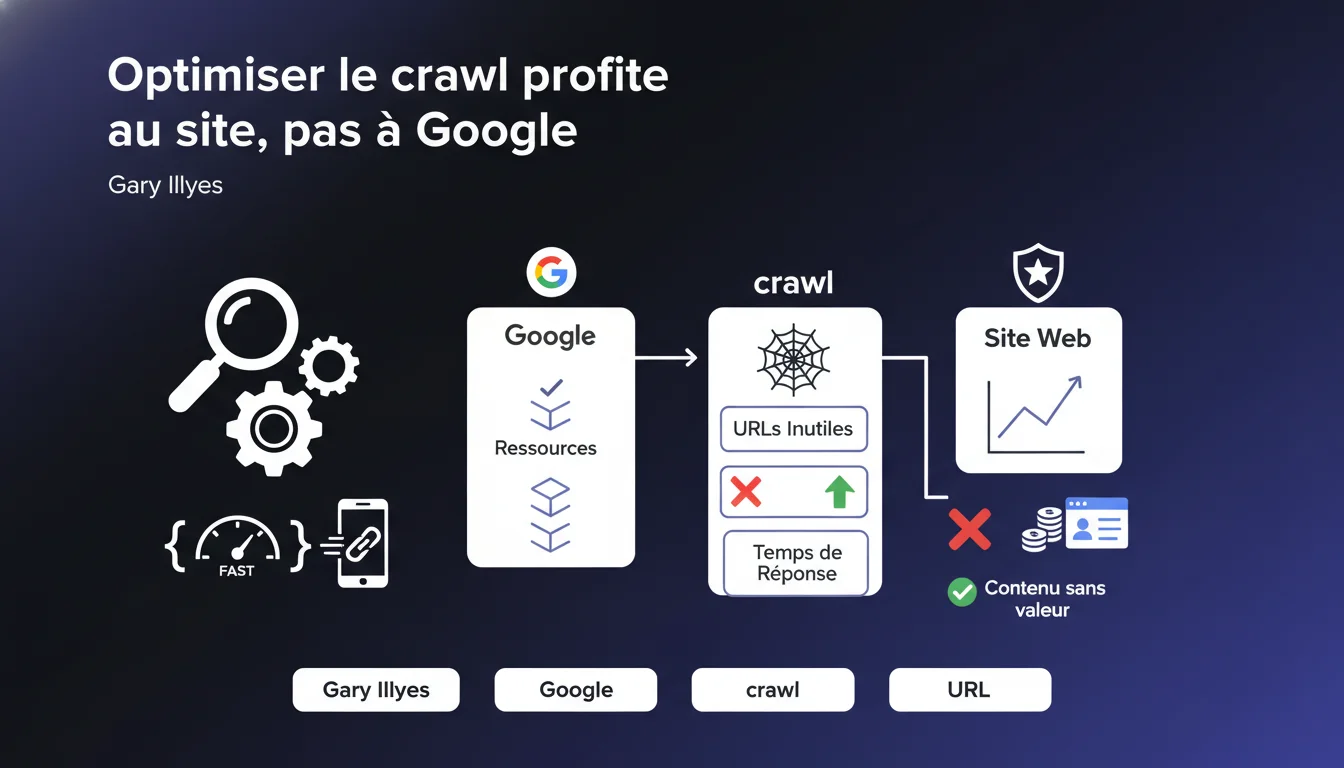
Google affirme disposer de ressources suffisantes pour crawler tous les sites. Pourtant, optimiser le crawl (éliminer les URLs parasites, accélérer les temps de réponse) reste crucial — non pas pour Google, mais pour votre propre site. L'objectif : forcer Googlebot à crawler vos pages stratégiques plutôt que du contenu inutile.
Ce qu'il faut comprendre
Google manque-t-il vraiment de ressources pour crawler le web ?
Non. Gary Illyes le dit sans détour : Google dispose de ressources suffisantes pour explorer l'ensemble du web crawlable. Le géant de Mountain View n'est pas limité par sa puissance de calcul ou sa bande passante.
Alors pourquoi parler encore de crawl budget ? Parce que même si Google peut tout crawler, il ne le fera pas si votre site lui sert massivement du contenu redondant, des URLs paramétrées à l'infini ou des pages à faible valeur ajoutée. Le crawl budget n'est pas une contrainte technique chez Google — c'est une allocation logique basée sur la qualité perçue de votre site.
Pourquoi optimiser le crawl si Google n'a pas de limites ?
L'optimisation du crawl ne profite pas à Google. Elle profite à votre site. Concrètement : si Googlebot passe 80% de son temps à crawler des facettes de filtres ou des sessions ID, il lui reste 20% pour découvrir vos nouvelles pages stratégiques.
Réduire les URLs inutiles et améliorer les temps de réponse, c'est rediriger l'effort de crawl vers ce qui compte vraiment : vos contenus à forte valeur, vos landings SEO, vos pages fraîchement mises à jour. Google ne ralentit pas — mais vous décidez où il met son énergie.
- Le crawl budget est une allocation logique, pas une contrainte matérielle chez Google
- Optimiser le crawl redirige Googlebot vers vos URLs stratégiques
- Réduire le bruit (URLs inutiles, temps de réponse longs) améliore la fraîcheur de l'indexation
- Les sites mal optimisés diluent leur propre potentiel de crawl sur du contenu sans valeur
Quels sites sont vraiment concernés par cette optimisation ?
Tous les sites de moyenne à grande taille. Si vous avez quelques dizaines de pages statiques, le sujet ne se pose même pas. En revanche, dès que vous dépassez quelques milliers d'URLs — e-commerce, marketplace, sites d'actualité, portails de contenu — la question devient critique.
Les sites les plus exposés sont ceux qui génèrent des URLs dynamiques à la volée : facettes de filtres, tris multiples, paramètres de session, calendriers infinis. Si vous ne cadrez pas proprement ce qui doit être crawlé, Googlebot passe son temps sur des variantes sans valeur.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, mais avec une nuance de taille. Google a effectivement les ressources techniques pour crawler massivement. Personne ne conteste cela. En revanche, observer les logs Apache ou Nginx révèle que Googlebot ne visite pas toutes les URLs avec la même fréquence — loin de là.
Sur les gros sites e-commerce, on constate régulièrement que certaines sections sont crawlées quotidiennement, d'autres hebdomadairement, et certaines URLs stratégiques ne sont jamais visitées parce qu'elles sont noyées dans du bruit. Donc oui, Google peut tout crawler — mais dans les faits, il priorise selon des signaux de qualité et d'autorité. [A vérifier] : la définition exacte de ces signaux de priorisation reste floue.
Quelles nuances faut-il apporter à cette affirmation ?
La première nuance, c'est que Google parle de ressources globales, pas d'allocation par site. Dire « nous avons assez de ressources » ne signifie pas « nous allons tout crawler sur votre site ». Il y a une différence fondamentale entre capacité théorique et comportement réel.
La seconde nuance : les optimisations de crawl ne se limitent pas au volume d'URLs. Les temps de réponse serveur jouent un rôle énorme. Un site qui renvoie du 200 en 3 secondes sera crawlé moins agressivement qu'un site répondant en 200ms. Google ajuste la fréquence de ses requêtes pour ne pas surcharger les serveurs — sauf que si votre infra est lente, vous vous auto-limitez.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Sur les très petits sites (moins de 500 pages), l'optimisation du crawl est anecdotique. Googlebot va tout explorer de toute façon, et rapidement. Inutile de perdre du temps à sur-optimiser un robots.txt ou à configurer finement les paramètres dans la Search Console.
En revanche, sur les sites de plusieurs dizaines ou centaines de milliers de pages, ignorer le sujet revient à saboter sa propre stratégie SEO. Le crawl devient alors un levier de compétitivité direct : ceux qui savent le piloter gagnent en réactivité d'indexation, en fraîcheur de contenu, en capacité à pousser rapidement de nouveaux contenus dans l'index.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser le crawl ?
D'abord, identifier les URLs inutiles que Googlebot visite. Cela passe par une analyse sérieuse des logs serveur : quelles sections sont crawlées ? Lesquelles consomment du crawl sans apporter de valeur ? On cherche les facettes inutiles, les pages de pagination infinies, les paramètres de session, les doublons techniques.
Ensuite, agir sur deux leviers : le robots.txt pour bloquer proprement les sections parasites, et les balises canonical + noindex pour traiter les cas limites. Parallèlement, travailler la performance serveur : réduire les temps de réponse, optimiser la base de données, mettre en place un CDN si nécessaire.
- Analyser les logs serveur pour identifier les URLs crawlées sans valeur SEO
- Bloquer via robots.txt les sections inutiles (filtres, tris, sessions, calendriers infinis)
- Utiliser les canonical et noindex pour gérer les doublons techniques
- Réduire les temps de réponse serveur sous 200ms dans l'idéal
- Configurer les paramètres d'URL dans Google Search Console si applicable
- Prioriser l'exploration des nouvelles pages stratégiques via XML sitemaps segmentés
- Monitorer régulièrement le taux de crawl et les erreurs dans la Search Console
Quelles erreurs éviter absolument ?
Première erreur : croire qu'optimiser le crawl, c'est limiter l'accès de Googlebot. Non. L'objectif n'est pas de bloquer massivement, mais de rediriger l'effort vers les URLs qui comptent. Bloquer trop large peut nuire à la découverte de nouveaux contenus.
Deuxième erreur : ignorer les temps de réponse. Vous pouvez avoir une architecture URL parfaite, si votre serveur met 2 secondes à répondre, Googlebot va ralentir son crawl pour ne pas vous planter. La performance serveur est un prérequis non négociable.
Troisième erreur : ne jamais analyser les logs. Sans données réelles sur ce que Googlebot fait chez vous, vous naviguez à l'aveugle. Les logs sont la seule source de vérité pour comprendre le comportement de crawl — la Search Console ne suffit pas.
Comment vérifier que les optimisations fonctionnent ?
Le meilleur indicateur reste l'analyse des logs avant/après. Vous devez constater une réallocation du crawl : moins de hits sur les URLs inutiles, plus de hits sur les sections stratégiques. Le volume total de crawl peut rester stable, mais la répartition change.
Autre signal : la fraîcheur d'indexation. Si vos nouvelles pages ou mises à jour de contenu apparaissent plus rapidement dans l'index après optimisation, c'est que Googlebot passe plus de temps sur ce qui compte. Surveillez aussi les erreurs de crawl dans la Search Console : elles doivent diminuer si vous avez bien nettoyé l'architecture.
❓ Questions frequentes
Le crawl budget existe-t-il encore si Google a des ressources illimitées ?
Mon site de 500 pages doit-il optimiser son crawl ?
Quelle est la priorité : réduire les URLs ou améliorer les temps de réponse ?
Comment savoir quelles URLs Googlebot visite vraiment ?
Bloquer des sections entières via robots.txt est-il risqué ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.