Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Le crawl intensif garantit-il vraiment un site de qualité ?
- □ Faut-il forcer Google à crawler davantage pour améliorer son classement ?
- □ Peut-on vraiment augmenter le crawl budget de son site en contactant Google ?
- □ Pourquoi Google crawle-t-il certains sites plus souvent que d'autres ?
- □ Pourquoi Google insiste-t-il sur l'implémentation du header If-Modified-Since ?
- □ Les paramètres d'URL créent-ils vraiment un espace de crawl infini pour Google ?
- □ Pourquoi les hashtags et ancres d'URL compliquent-ils le crawl de Google ?
- □ Pourquoi Google insiste-t-il autant sur les statistiques d'exploration dans Search Console ?
- □ Pourquoi un temps de réponse serveur lent tue-t-il votre crawl budget ?
- □ Faut-il vraiment optimiser le crawl budget si Google a des ressources illimitées ?
- □ Les sitemaps sont-ils vraiment indispensables pour optimiser le crawl de votre site ?
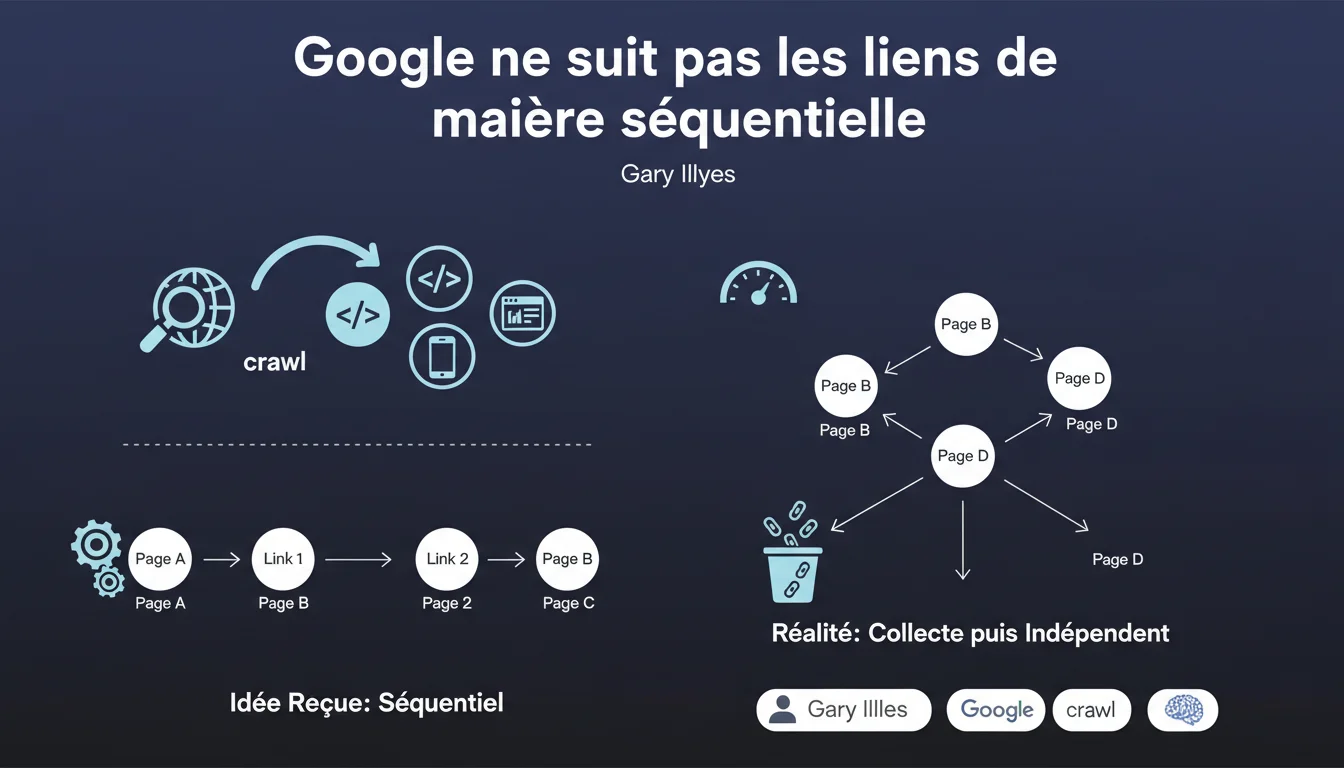
Googlebot ne suit pas les liens de manière séquentielle comme le ferait un internaute. Il collecte d'abord tous les liens découverts, puis y accède de manière indépendante et non linéaire. Cette distinction technique change la façon dont on doit penser le crawl et le maillage interne.
Ce qu'il faut comprendre
Quelle est la différence entre le crawl séquentiel et le crawl par collecte ?
L'idée reçue est simple : Googlebot atterrit sur une page, lit le contenu, clique sur un lien, arrive sur la page suivante, et répète l'opération. Comme un utilisateur qui naviguerait de lien en lien. Sauf que non.
En réalité, le processus est découplé. Le bot analyse d'abord la page, extrait tous les liens présents, puis les stocke dans une file d'attente. Ces URLs sont ensuite crawlées de manière indépendante, sans forcément respecter l'ordre de découverte ni la structure hiérarchique du site. Le comportement est asynchrone et parallélisé.
Pourquoi Google utilise-t-il cette méthode plutôt qu'un crawl linéaire ?
Parce que c'est infiniment plus efficace à grande échelle. Crawler le web de manière séquentielle serait d'une lenteur catastrophique. Google doit gérer des milliards de pages — il a besoin de distribuer le travail, prioriser certaines URLs, et optimiser l'usage de sa bande passante.
Cette architecture permet aussi de revisiter certaines pages plus souvent que d'autres, sans être contraint par un parcours linéaire. Une page peut être crawlée plusieurs fois avant que le bot ne passe à une autre découverte lors de la même session.
Quelles sont les implications directes pour le référencement ?
- La profondeur de clic n'a pas le même impact qu'on pourrait croire — une page à 5 clics de la home peut être crawlée avant une page à 2 clics si elle est jugée plus prioritaire.
- Le maillage interne ne fonctionne pas comme un "chemin" unique — chaque lien est une opportunité de découverte indépendante, pas une étape dans un parcours.
- Les patterns de crawl ne reflètent pas forcément la structure logique du site — Googlebot peut sauter d'une section à l'autre sans suivre votre arborescence.
- La fréquence de crawl d'une URL dépend de sa priorité individuelle, pas de sa position dans un parcours global.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Oui, et c'est même un point que beaucoup de SEO expérimentés savent déjà — mais que peu verbalisent clairement. Les logs serveur montrent des patterns de crawl erratiques, avec des sauts non linéaires entre sections, des retours en arrière, des pages orphelines découvertes via des liens externes avant même d'être crawlées via le maillage interne.
Ce qui est intéressant, c'est que Google le confirme explicitement. Trop de débutants pensent encore que positionner un lien "plus haut" dans la page ou "plus tôt" dans le parcours utilisateur garantit un crawl prioritaire. C'est faux. La priorité se joue ailleurs : popularité de l'URL, fraîcheur perçue, budget de crawl global du domaine.
Quelles nuances faut-il apporter à cette affirmation ?
Attention : dire que Googlebot ne suit pas les liens de manière séquentielle ne signifie pas que l'ordre des liens ou leur position dans le DOM n'a aucune importance. Google a confirmé à plusieurs reprises que les premiers liens dans le code HTML ont plus de poids. [À vérifier] si cela impacte la priorisation du crawl ou uniquement le PageRank interne — les deux hypothèses coexistent.
De plus, cette déclaration ne dit rien sur la fréquence de collecte des liens. Si Googlebot ne recrawle la page A que tous les 30 jours, un lien ajouté sur cette page vers la page B ne sera découvert qu'à la prochaine visite. La non-linéarité du crawl ne compense pas un déficit de fréquence de passage.
Dans quels cas cette distinction technique change-t-elle vraiment la donne ?
Surtout sur les gros sites avec un crawl budget limité. Si vous avez un site de 100 000 pages et que Googlebot ne crawle que 5 000 URLs par jour, comprendre que le crawl n'est pas séquentiel vous aide à optimiser la découvrabilité sans vous focaliser uniquement sur la structure hiérarchique.
Concrètement ? Multiplier les points d'entrée vers vos pages stratégiques — pas juste depuis la home, mais depuis plusieurs hubs crawlés fréquemment. Utiliser le maillage interne comme un réseau de distribution décentralisé, pas comme un arbre unique avec une racine unique.
Impact pratique et recommandations
Que faut-il faire concrètement pour tirer parti de cette réalité technique ?
Repensez votre stratégie de maillage interne en termes de réseau, pas de hiérarchie linéaire. Identifiez les pages qui sont crawlées fréquemment (vérifiez vos logs serveur) et utilisez-les comme relais de découverte pour les pages stratégiques moins bien crawlées.
Ensuite, ne vous contentez pas de créer un lien unique vers une page importante. Multipliez les occurrences de liens internes depuis différentes sections du site, en veillant à ce qu'elles restent contextuellement pertinentes. Plus une URL apparaît dans la file d'attente de crawl, plus elle a de chances d'être visitée rapidement.
Enfin, surveillez la fréquence de crawl de vos hubs de contenu (blog, catégories principales, pages listing). Si une section est crawlée tous les jours, c'est un point d'entrée idéal pour faire découvrir de nouvelles pages — même si elles sont éloignées dans l'arborescence logique.
Quelles erreurs éviter dans cette logique de crawl non séquentiel ?
Ne tombez pas dans le piège du sur-maillage anarchique. Ajouter des liens partout sans logique thématique dégrade la qualité de l'expérience utilisateur et dilue le PageRank interne. Google comprend de mieux en mieux la pertinence contextuelle — un lien forcé ne vaut rien.
Autre erreur courante : négliger la vélocité de crawl de vos pages relais. Si vous comptez sur une page pour faire découvrir d'autres URLs, mais qu'elle n'est crawlée qu'une fois par mois, vous perdez du temps. Vérifiez les logs avant de bâtir votre stratégie.
Comment vérifier que votre site est optimisé pour cette réalité du crawl ?
- Analysez vos logs serveur pour identifier les pages les plus fréquemment crawlées et les patterns de visite de Googlebot.
- Cartographiez votre maillage interne avec un outil comme Screaming Frog ou Oncrawl pour repérer les pages isolées ou mal distribuées.
- Vérifiez que vos pages stratégiques reçoivent des liens depuis plusieurs hubs crawlés régulièrement, pas seulement depuis la home.
- Testez la vitesse de découverte de nouvelles URLs en publiant une page test et en observant combien de temps Google met à la crawler (via Search Console).
- Contrôlez que votre fichier sitemap XML est à jour et soumis — c'est un canal de découverte complémentaire qui contourne le crawl par liens.
❓ Questions frequentes
Est-ce que la profondeur de clic n'a donc plus aucune importance pour le crawl ?
Si Googlebot ne suit pas les liens de manière séquentielle, comment priorise-t-il les URLs à crawler ?
Faut-il abandonner l'idée d'une structure en silo thématique avec cette logique de crawl ?
Le sitemap XML devient-il plus important dans cette logique de crawl asynchrone ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.