Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Le crawl intensif garantit-il vraiment un site de qualité ?
- □ Faut-il forcer Google à crawler davantage pour améliorer son classement ?
- □ Peut-on vraiment augmenter le crawl budget de son site en contactant Google ?
- □ Pourquoi Google crawle-t-il certains sites plus souvent que d'autres ?
- □ Pourquoi Google insiste-t-il sur l'implémentation du header If-Modified-Since ?
- □ Pourquoi les hashtags et ancres d'URL compliquent-ils le crawl de Google ?
- □ Pourquoi Google insiste-t-il autant sur les statistiques d'exploration dans Search Console ?
- □ Pourquoi un temps de réponse serveur lent tue-t-il votre crawl budget ?
- □ Googlebot suit-il vraiment les liens comme un utilisateur navigue de page en page ?
- □ Faut-il vraiment optimiser le crawl budget si Google a des ressources illimitées ?
- □ Les sitemaps sont-ils vraiment indispensables pour optimiser le crawl de votre site ?
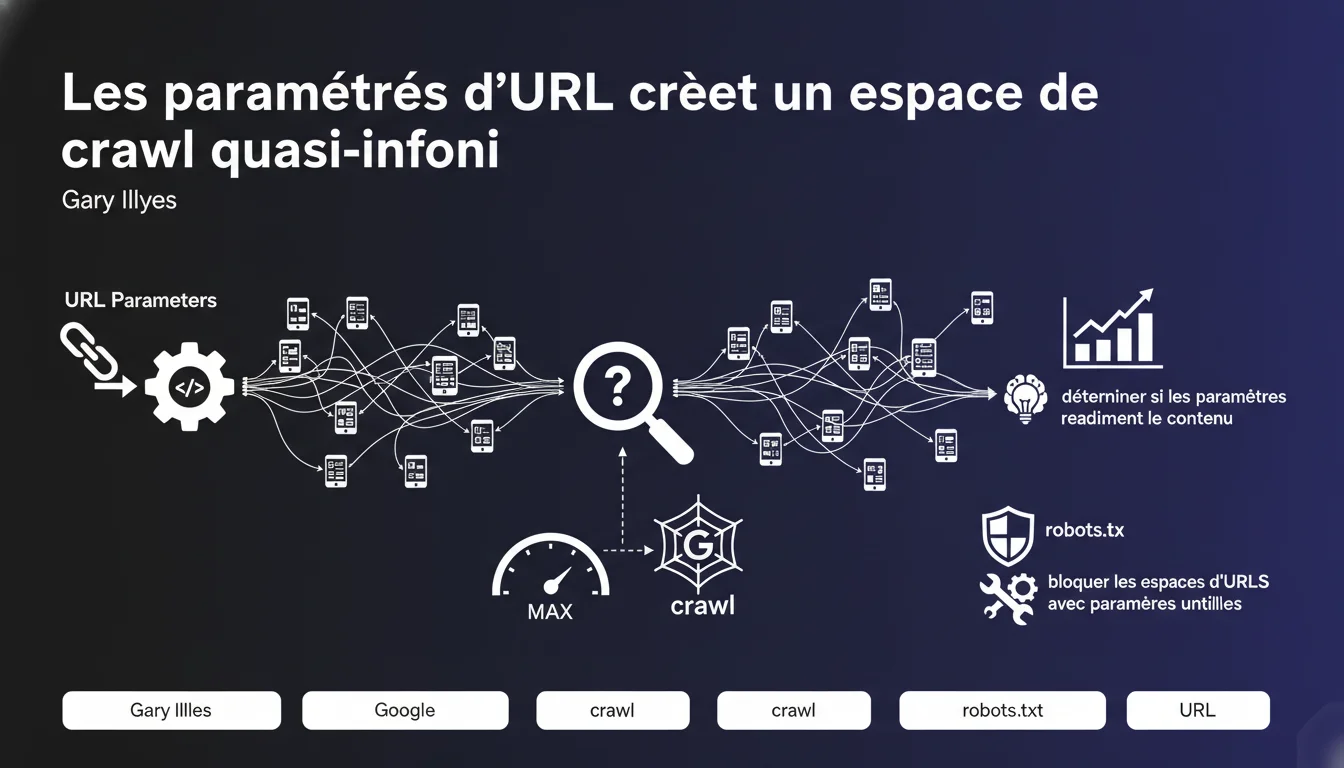
Les paramètres d'URL génèrent un nombre quasi-infini de versions d'une même page, forçant Google à crawler un large échantillon pour déterminer si ces paramètres modifient réellement le contenu. Cette déclaration confirme que les URLs paramétrées impactent directement le crawl budget et que robots.txt reste l'outil privilégié pour bloquer ces espaces inutiles.
Ce qu'il faut comprendre
Pourquoi les paramètres d'URL posent-ils un problème de crawl ?
Un paramètre d'URL — ces ?id=123 ou &sort=price — peut générer des milliers, voire des millions de combinaisons de la même page. Tri par prix, filtre par couleur, pagination, identifiants de session : chaque variation crée une URL unique aux yeux de Googlebot.
Le problème ? Google doit explorer suffisamment de ces URLs pour comprendre si le paramètre change vraiment le contenu ou s'il s'agit de la même page sous différentes formes. Ce processus consomme du crawl budget — cette ressource limitée que Google alloue à chaque site.
Que signifie « espace de crawl quasi-infini » concrètement ?
Prenons un site e-commerce avec 1 000 produits. Ajoutons 5 options de tri, 3 options d'affichage, 10 filtres de prix, et une pagination de 20 pages. Le calcul devient vite astronomique : des centaines de milliers d'URLs générées automatiquement.
Google ne peut pas toutes les crawler. Il va tenter d'échantillonner cette masse pour identifier les patterns — mais pendant ce temps, vos pages stratégiques attendent peut-être leur tour dans la file d'attente.
Quelle est la position officielle de Google sur le sujet ?
Gary Illyes confirme que Google reconnaît ce problème structurel. La solution recommandée : utiliser robots.txt pour bloquer les espaces d'URLs avec paramètres inutiles. Pas de canonical ici, pas de noindex : un blocage pur et simple au niveau du crawl.
- Les paramètres d'URL créent un espace combinatoire quasi-infini d'URLs distinctes
- Google doit crawler un large échantillon pour déterminer si les paramètres modifient le contenu réel
- Ce processus consomme du crawl budget qui pourrait être alloué ailleurs
- La solution préconisée est robots.txt, pas les balises meta ou canonical
- Cette approche permet de bloquer le crawl en amont, avant même que Googlebot ne découvre ces URLs
Avis d'un expert SEO
Cette recommandation est-elle vraiment la plus efficace dans tous les cas ?
Soyons honnêtes : robots.txt est un outil puissant mais binaire. Vous bloquez ou vous ne bloquez pas. Le problème ? Certains paramètres ont une valeur SEO — une pagination bien gérée, des filtres à fort volume de recherche, des variantes régionales.
Bloquer aveuglément tous les paramètres, c'est risquer de perdre du trafic long-tail. À l'inverse, laisser Google se débrouiller seul avec un espace infini, c'est diluer votre crawl budget. La nuance manque dans cette déclaration. [À vérifier] : Google ne précise pas comment distinguer les paramètres à valeur SEO de ceux qui sont purement techniques.
Pourquoi Google ne recommande-t-il pas d'autres solutions ?
La Search Console proposait autrefois un outil de gestion des paramètres d'URL — abandonné depuis. Les balises canonical sont mentionnées nulle part ici, alors qu'elles permettent justement de consolider ces variations sans bloquer le crawl.
Cette omission est troublante. En pratique, une combinaison canonical + robots.txt sélectif fonctionne souvent mieux qu'un blocage total. Mais Google simplifie son message — ce qui peut induire en erreur les praticiens moins expérimentés.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Les sites à faible volumétrie n'ont pas ce problème. Si votre site génère 500 URLs au total, les paramètres ne créeront pas d'espace infini critique. Google crawlera l'ensemble sans difficulté.
Impact pratique et recommandations
Que faut-il faire concrètement pour gérer ces paramètres ?
Première étape : auditer vos URLs via Google Search Console et vos logs serveur. Identifiez quels paramètres génèrent le plus d'URLs, lesquels sont crawlés massivement, lesquels apportent du trafic. Cette cartographie est indispensable.
Ensuite, classez vos paramètres en trois catégories : ceux qui modifient réellement le contenu (à indexer), ceux qui ne changent rien (à bloquer), et la zone grise (filtres à volume de recherche moyen — décision cas par cas).
Quelles erreurs éviter absolument ?
Ne bloquez jamais un paramètre en robots.txt si Google l'a déjà indexé massivement. Vous créerez un trou noir : des URLs indexées mais non-crawlables, que Google mettra des mois à purger. Utilisez d'abord les canonical pour consolider, puis bloquez progressivement.
Autre piège classique : bloquer ?page= en pensant résoudre un problème de pagination. Résultat ? Google ne peut plus crawler vos pages 2, 3, 4… et vous perdez la profondeur de votre indexation. La pagination nécessite une gestion spécifique (rel=next/prev ou canonical vers une page « Voir tout »), pas un blocage brutal.
Comment vérifier que votre site est correctement configuré ?
Trois vérifications essentielles. Premièrement, analysez vos logs serveur pour repérer les patterns de crawl sur les URLs paramétrées — si Googlebot passe 80% de son temps sur des URLs inutiles, vous avez un problème. Deuxièmement, utilisez la Search Console pour identifier les URLs indexées avec paramètres et mesurer leur performance. Troisièmement, testez vos règles robots.txt avec l'outil de test pour éviter les blocages accidentels de pages stratégiques.
- Auditer les paramètres d'URL via Search Console et logs serveur
- Classifier les paramètres : contenu unique vs technique inutile
- Utiliser robots.txt pour bloquer les espaces paramétrés sans valeur SEO
- Combiner avec des canonical pour les paramètres à zone grise
- Ne jamais bloquer un paramètre déjà massivement indexé sans transition
- Vérifier régulièrement les logs pour détecter les dérives de crawl
- Tester toute modification robots.txt avant déploiement
❓ Questions frequentes
Dois-je bloquer tous les paramètres d'URL en robots.txt ?
Que se passe-t-il si je bloque un paramètre déjà indexé par Google ?
Les balises canonical suffisent-elles à résoudre le problème de crawl budget ?
Comment savoir si mes paramètres d'URL consomment trop de crawl budget ?
Google peut-il comprendre automatiquement quels paramètres sont inutiles ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.