Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
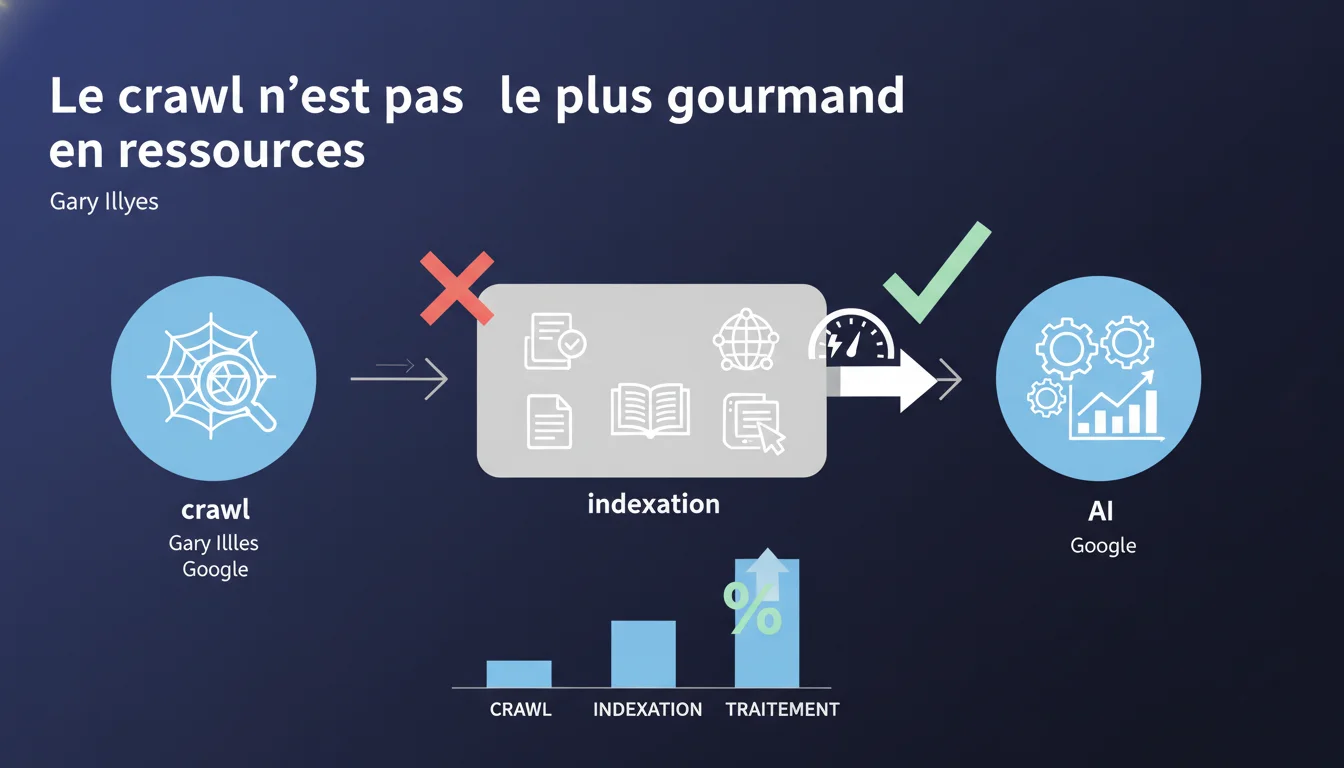
Gary Illyes renverse une idée reçue : ce n'est pas le crawl qui bouffe les ressources chez Google, mais l'indexation et le traitement des données. Une nuance majeure pour comprendre où se situent vraiment les goulets d'étranglement côté moteur — et pourquoi optimiser le crawl budget n'est peut-être pas votre priorité absolue.
Ce qu'il faut comprendre
Qu'est-ce qui consomme vraiment le plus de ressources côté Google ?
Gary Illyes affirme que le crawling n'est pas l'opération la plus coûteuse dans le pipeline de traitement de Google. Ce sont l'indexation et le traitement des données récupérées qui mobilisent le plus de puissance de calcul.
Concrètement ? Aller chercher le HTML d'une page, c'est relativement peu gourmand. En revanche, analyser ce contenu, extraire les entités, calculer les scores de pertinence, gérer les liens internes et externes, appliquer les filtres de qualité — tout ça, c'est une autre paire de manches.
Pourquoi cette distinction change notre perception du crawl budget ?
Pendant des années, le SEO s'est focalisé sur le crawl budget comme enjeu majeur. L'idée : Google a des ressources limitées pour crawler votre site, donc mieux vaut optimiser pour qu'il ne gaspille pas son temps sur des pages inutiles.
Sauf que si le crawl n'est pas le vrai goulet, cette obsession pourrait être mal placée. Ce n'est pas qu'optimiser le crawl soit inutile — mais ce n'est peut-être pas là que se joue votre bataille d'indexation si vous avez un site de taille moyenne.
Qu'est-ce que ça implique pour les gros sites ?
Pour les sites massifs (millions de pages), le crawl reste un enjeu — Google ne crawlera jamais tout, même si c'est techniquement léger. Mais la vraie contrainte, c'est l'indexation : combien de pages Google peut-il réellement traiter et stocker dans son index ?
Cette déclaration suggère que même si Google crawle votre page, rien ne garantit qu'elle sera indexée correctement ou rapidement. Le traitement post-crawl peut prendre du temps, surtout si votre contenu nécessite une analyse complexe ou si votre site génère beaucoup de signal contradictoire.
- Le crawl est relativement peu coûteux pour Google
- L'indexation et le traitement des données sont les vraies opérations gourmandes
- Optimiser le crawl reste pertinent, mais ce n'est pas le seul levier pour améliorer l'indexation
- Pour les gros sites, le vrai enjeu est la qualité du contenu à indexer, pas juste sa disponibilité au crawl
Avis d'un expert SEO
Cette déclaration contredit-elle les pratiques observées sur le terrain ?
Pas vraiment. On sait depuis longtemps que Google ne crawle pas tout ce qu'il indexe (pensez aux flux sociaux agrégés) et n'indexe pas tout ce qu'il crawle. Mais cette affirmation repositionne les priorités.
Dans la pratique, on observe que des sites crawlés massivement peuvent avoir des problèmes d'indexation — et inversement, des sites peu crawlés peuvent avoir un excellent taux d'indexation si le contenu est pertinent et bien structuré. Le crawl n'est qu'une étape, et Gary Illyes nous rappelle qu'elle n'est pas la plus critique du point de vue ressources.
Quelles nuances faut-il apporter à cette affirmation ?
Même si le crawl consomme peu de ressources chez Google, il peut en consommer beaucoup chez vous. Un bot agressif peut saturer votre serveur, surtout si votre infrastructure est fragile ou si vous générez du contenu dynamique coûteux.
Donc oui, optimiser le crawl reste pertinent — mais pour protéger vos propres ressources, pas celles de Google. [A verifier] : Gary Illyes ne précise pas comment Google arbitre entre sites quand ses capacités d'indexation sont saturées — critère de qualité, freshness, autorité ?
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre site génère du contenu massivement dupliqué ou de très faible qualité, Google peut limiter le crawl avant même d'arriver à la phase d'indexation. Dans ce cas, le crawl redevient un goulot — mais c'est une conséquence, pas la cause première.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser l'indexation ?
Première étape : facilitez le traitement post-crawl. Ça passe par une structure HTML propre, des données structurées cohérentes, un maillage interne clair. Plus votre contenu est facile à analyser, moins Google dépense de ressources dessus.
Deuxième axe : réduisez le bruit. Si vous envoyez à Google 10 000 pages dont 8 000 sont du quasi-duplicate ou du thin content, vous saturez son pipeline d'indexation pour rien. Mieux vaut 2 000 pages solides que 10 000 pages médiocres.
Quelles erreurs éviter face à cette réalité ?
Arrêtez de croire qu'augmenter artificiellement le crawl va mécaniquement booster votre indexation. Si Google crawle vos pages mais ne les indexe pas, le problème est ailleurs : qualité du contenu, duplication, cannibalisation, signaux contradictoires.
Autre erreur classique : négliger la vitesse de traitement côté serveur sous prétexte que Google s'en fiche. Faux. Un serveur lent ralentit le crawl, donc retarde l'indexation — même si le crawl en lui-même n'est pas gourmand pour Google.
Comment vérifier que votre site est optimisé pour l'indexation ?
Analysez le taux d'indexation réel via la Search Console : combien de pages crawlées vs pages indexées ? Un écart important signale un problème de qualité ou de traitement, pas forcément de crawl.
Vérifiez aussi la profondeur de crawl et le temps moyen de réponse serveur. Si Google met 2 secondes à récupérer une page, même si le crawl est léger pour lui, ça ralentit tout le processus.
- Structurez votre HTML proprement et utilisez les données structurées pour faciliter le traitement
- Éliminez les pages de faible qualité ou dupliquées pour ne pas saturer le pipeline d'indexation
- Surveillez le taux d'indexation dans la Search Console, pas juste le crawl
- Optimisez le temps de réponse serveur pour accélérer le crawl (même si Google n'est pas limité par ça)
- Concentrez-vous sur la qualité du contenu plutôt que sur la quantité de pages crawlables
❓ Questions frequentes
Le crawl budget est-il toujours un concept pertinent si le crawl consomme peu de ressources ?
Si l'indexation est plus coûteuse, Google peut-il refuser d'indexer certaines pages pour économiser des ressources ?
Faut-il privilégier l'optimisation du crawl ou celle de l'indexation ?
Cette déclaration change-t-elle la façon dont on doit gérer un site de plusieurs millions de pages ?
Google communique-t-il clairement sur les critères qui rendent l'indexation coûteuse ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/05/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.