Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
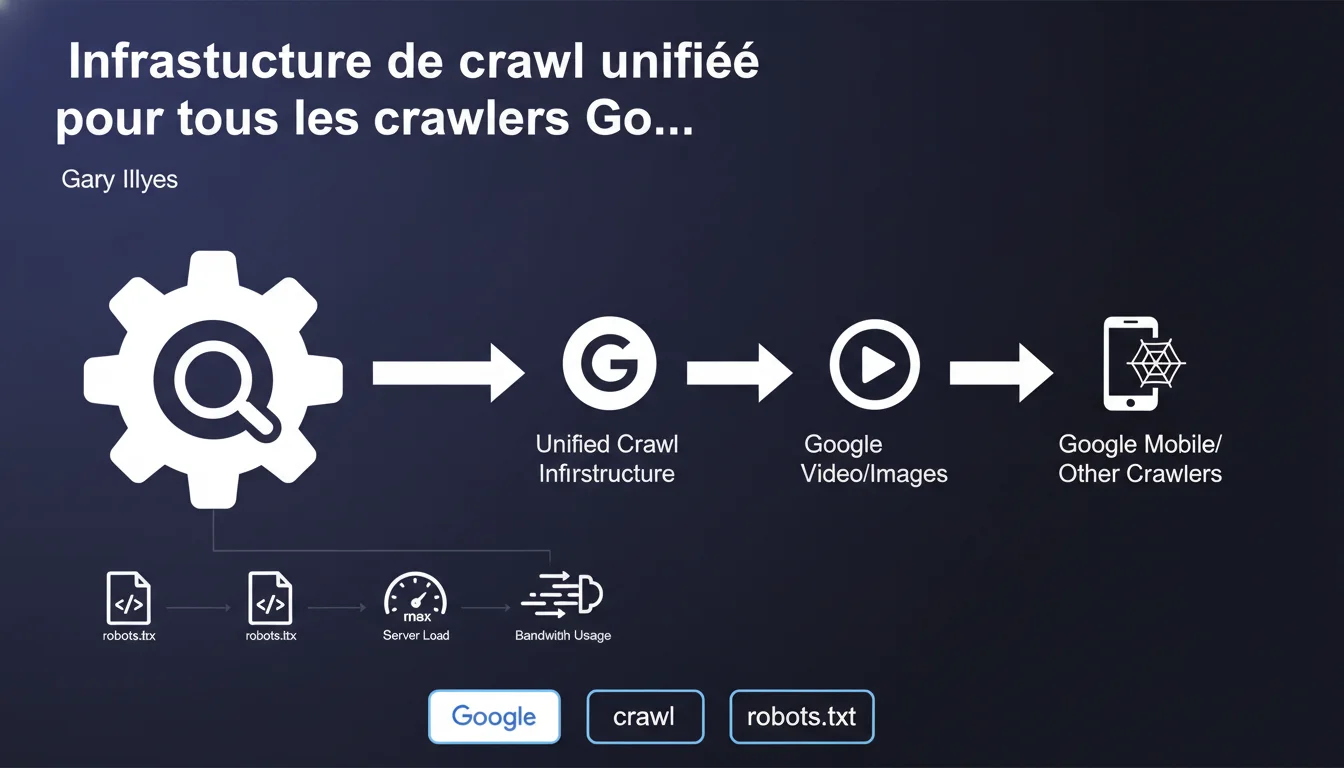
Google utilise une seule et même infrastructure de crawl pour tous ses produits — Googlebot Search, Googlebot Images, Googlebot News, etc. Tous partagent le même code et appliquent les mêmes règles concernant robots.txt, la charge serveur et la bande passante. Conséquence directe : bloquer un crawler, c'est potentiellement en bloquer plusieurs.
Ce qu'il faut comprendre
Que signifie « infrastructure de crawl unifiée » concrètement ?
Google a regroupé tous ses crawlers spécialisés sous une même base technique. Que ce soit Googlebot pour la recherche classique, Googlebot Images, ou encore Googlebot News, tous reposent désormais sur le même moteur de crawl.
Cette consolidation technique implique que les règles de comportement sont identiques : respect de robots.txt, politesse vis-à-vis de la charge serveur, gestion de la bande passante. Un seul code, une seule logique d'exploration.
Pourquoi Google a-t-il pris cette direction ?
L'unification simplifie la maintenance et garantit une cohérence comportementale. Plus besoin de gérer des dizaines de crawlers avec des politiques divergentes — ce qui était source de bugs et d'incohérences.
Pour les éditeurs de sites, ça signifie aussi que bloquer un crawler dans robots.txt peut avoir des effets collatéraux sur d'autres services Google. Si vous bloquez Googlebot-Image pour économiser de la bande passante, vous risquez d'impacter également l'indexation de vos images dans Google Images.
Quelles sont les implications pour le crawl budget ?
L'infrastructure unifiée applique les mêmes limites de politesse à tous les crawlers. Concrètement, Google ne va pas multiplier les requêtes juste parce qu'il utilise plusieurs user-agents différents.
Le crawl budget est géré globalement, avec une répartition interne entre les différents types de contenus (HTML, images, CSS, JS). Bloquer un type de ressource ne libère pas forcément du budget pour un autre — ça dépend de la manière dont Google priorise vos contenus.
- Tous les crawlers Google partagent la même base de code
- Ils respectent les mêmes directives robots.txt
- La gestion de la charge serveur est unifiée
- Bloquer un crawler peut impacter l'indexation dans plusieurs produits Google
- Le crawl budget est géré de manière globale, pas par crawler
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, globalement. On observe effectivement que les différents Googlebots respectent les mêmes directives robots.txt et ont des comportements similaires en termes de politesse. Les logs serveur montrent que Google ne spamme pas avec des dizaines de crawlers distincts fonctionnant en parallèle.
Mais — et c'est un point important — cette unification ne signifie pas que tous les crawlers explorent exactement de la même manière. Les priorités d'exploration diffèrent selon le type de contenu. Googlebot News crawle plus fréquemment les sites d'actualité que Googlebot Search classique. [A vérifier] si cette différence de fréquence relève de la même infrastructure ou de couches de priorisation supérieures.
Quelles nuances faut-il apporter à cette affirmation ?
L'infrastructure est unifiée, mais les user-agents restent distincts. Google continue d'identifier ses crawlers avec des noms différents dans les logs — Googlebot, Googlebot-Image, Googlebot-News, etc. Ce n'est pas qu'une question cosmétique : ça permet de bloquer sélectivement certains types de contenus.
Sauf que — et c'est là que ça coince — bloquer un crawler spécifique dans robots.txt peut avoir des effets de bord. Si vous bloquez Googlebot-Image, vos images risquent de ne plus apparaître dans Google Images, mais aussi de ne plus être indexées dans les résultats de recherche classique où elles peuvent booster la pertinence.
Faut-il revoir ses stratégies de blocage robots.txt ?
Probablement, oui. Beaucoup de sites bloquent encore certains crawlers Google par réflexe ou par habitude, sans mesurer l'impact réel. Avec une infrastructure unifiée, ces blocages peuvent se retourner contre vous.
La bonne pratique : ne bloquer que ce qui doit vraiment l'être (contenus dupliqués, pages de test, ressources inutiles). Pour le reste, laissez Google faire son travail — l'infrastructure unifiée est conçue pour être respectueuse de vos ressources serveur.
Impact pratique et recommandations
Que faut-il faire concrètement avec son fichier robots.txt ?
Première étape : auditer votre robots.txt pour identifier les blocages spécifiques de crawlers Google. Cherchez les lignes « User-agent: Googlebot-Image » ou « User-agent: Googlebot-News » avec des Disallow associés.
Ensuite, posez-vous la question : ce blocage est-il toujours justifié ? Si l'objectif était d'économiser de la bande passante, sachez que l'infrastructure unifiée gère déjà cela intelligemment. Si c'était pour éviter l'indexation d'images sensibles, préférez un X-Robots-Tag: noindex au niveau HTTP.
Comment vérifier que Google crawle correctement mon site ?
Analysez vos logs serveur pour voir quels user-agents Google utilisent réellement. Vous devriez observer une diversité de crawlers (Googlebot, Googlebot-Image, etc.) avec des fréquences cohérentes par rapport à la taille et la fraîcheur de votre contenu.
Dans Google Search Console, vérifiez les statistiques d'exploration : nombre de pages crawlées par jour, temps de téléchargement, réponses serveur. Des pics inhabituels ou des erreurs récurrentes peuvent indiquer un problème de configuration robots.txt ou de performance serveur.
Quelles erreurs éviter absolument ?
- Ne bloquez pas Googlebot-Image si vous voulez que vos images apparaissent dans les résultats de recherche
- Ne bloquez pas les ressources CSS et JS — Google en a besoin pour le rendering
- N'utilisez pas de blocages génériques « User-agent: * » qui s'appliqueraient à tous les crawlers
- Ne comptez pas sur robots.txt pour protéger des contenus sensibles — utilisez l'authentification ou le noindex
- Ne bloquez pas les crawlers Google pour « économiser du crawl budget » — c'est contre-productif
L'infrastructure unifiée de Google simplifie la gestion du crawl, mais exige une révision des stratégies de blocage. Privilégiez la transparence et laissez Google crawler ce qui doit l'être — avec un robots.txt minimaliste et des directives noindex ciblées pour les contenus à exclure.
Ces optimisations techniques peuvent sembler simples en théorie, mais leur mise en œuvre correcte demande une analyse fine des logs, une compréhension des priorités d'indexation et un monitoring régulier. Si vous manquez de temps ou de ressources internes, faire appel à une agence SEO spécialisée peut vous éviter des erreurs coûteuses et accélérer votre visibilité.
❓ Questions frequentes
Bloquer Googlebot-Image empêche-t-il mes images d'apparaître dans Google Images ?
Tous les crawlers Google respectent-ils vraiment les mêmes limites de politesse ?
Peut-on encore bloquer sélectivement certains types de contenus avec robots.txt ?
L'infrastructure unifiée change-t-elle quelque chose au crawl budget ?
Faut-il modifier son robots.txt après cette annonce de Google ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/05/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.