Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
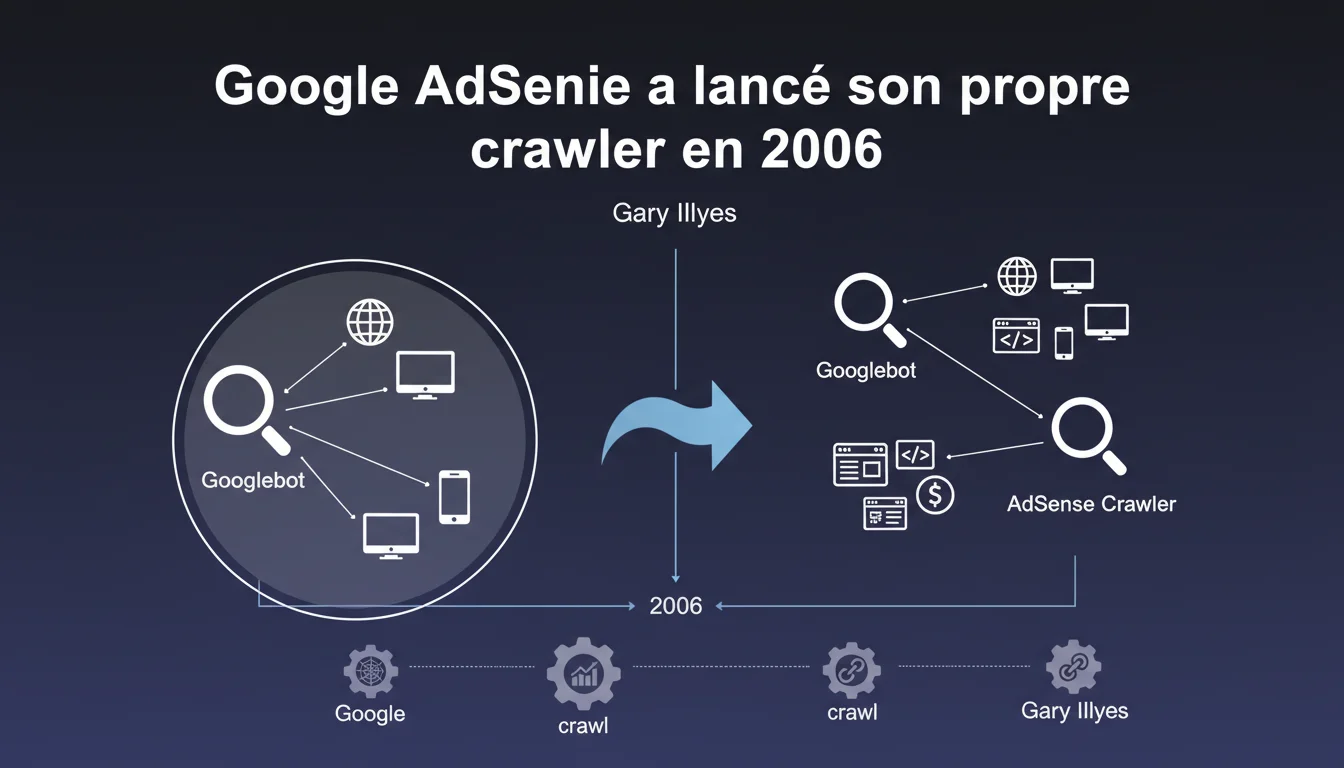
Google AdSense a déployé son propre user agent distinct de Googlebot en 2006, marquant le début d'une fragmentation stratégique du crawl. Depuis, l'écosystème de crawlers Google n'a cessé de se diversifier — chaque bot ayant son rôle, ses règles, et ses implications SEO spécifiques. Comprendre cette architecture multi-crawlers devient indispensable pour diagnostiquer précisément les problèmes de visibilité.
Ce qu'il faut comprendre
Qu'est-ce que Mediapartners-Google et pourquoi son lancement marque-t-il un tournant ?
Mediapartners-Google est le crawler dédié à AdSense, introduit en 2006 pour analyser le contenu des pages et afficher des publicités contextuelles pertinentes. Contrairement à Googlebot, il ne participe pas directement à l'indexation organique.
Son apparition a initié une logique de spécialisation fonctionnelle : plutôt qu'un seul bot universel, Google a progressivement segmenté ses crawlers selon les usages — publicité, images, actualités, mobile, JavaScript rendering, etc.
Combien de crawlers Google utilise-t-il aujourd'hui et à quoi servent-ils ?
Google dispose désormais d'une dizaine de crawlers identifiables par leur user agent distinct : Googlebot Desktop, Googlebot Smartphone, Googlebot Image, Googlebot Video, Googlebot News, Google-InspectionTool, AdsBot-Google, Mediapartners-Google, Google-Read-Aloud, Storebot-Google, GoogleOther.
Chaque bot a un rôle précis : Googlebot Smartphone évalue l'expérience mobile pour le mobile-first indexing, AdsBot-Google teste la qualité des landing pages publicitaires, GoogleOther effectue des tests internes non documentés. Cette fragmentation complique le diagnostic — un blocage partiel peut passer inaperçu si on ne surveille qu'un seul user agent.
Quelle est l'implication directe pour le SEO technique ?
La multiplication des crawlers impose une gestion granulaire du robots.txt et des directives de crawl. Bloquer Mediapartners-Google n'impacte pas l'indexation organique, mais désactive AdSense. Bloquer GoogleOther peut perturber des tests Google sans conséquence visible immédiate.
Le budget de crawl se répartit désormais entre ces différents agents. Un site peut être correctement crawlé en desktop mais sous-exploré en mobile, ou vice-versa. Les logs serveur deviennent indispensables pour identifier quel crawler accède réellement à quelles sections.
- Mediapartners-Google : crawler AdSense, aucun impact SEO organique direct
- Fragmentation progressive depuis 2006 : chaque produit Google a progressivement obtenu son propre bot
- Diagnostic complexifié : un problème d'indexation peut provenir d'un blocage ciblé sur un seul user agent
- Logs serveur indispensables pour cartographier précisément l'activité de chaque crawler
- Robots.txt et meta robots doivent être testés contre chaque bot pertinent pour votre activité
Avis d'un expert SEO
Cette déclaration résout-elle des zones d'ombre historiques ?
Oui, mais partiellement. Gary Illyes ancre officiellement le départ de la multi-crawler strategy en 2006, ce qui clarifie la chronologie. Avant cette confirmation, certains considéraient Mediapartners-Google comme un simple sous-programme de Googlebot.
En revanche, Google reste vague sur GoogleOther, le bot fourre-tout utilisé pour des tâches internes non spécifiées. Aucune documentation précise n'existe sur ses critères de crawl, sa fréquence, ou son rôle exact. [A vérifier] : l'impact réel de GoogleOther sur les performances SEO reste largement spéculatif.
Les observations terrain confirment-elles cette fragmentation ?
Absolument. L'analyse de logs serveur sur des milliers de sites révèle que Googlebot Smartphone et Googlebot Desktop n'ont pas les mêmes priorités de crawl. Des sections entières peuvent être explorées intensément par l'un et ignorées par l'autre.
Un cas fréquent : les sites e-commerce avec des facettes complexes. Googlebot Desktop peut crawler massivement les URLs paramétrées, tandis que Googlebot Smartphone se concentre sur les pages principales. Résultat : des incohérences d'indexation mobile-first que les SEO attribuent à tort à des problèmes de performance, alors que c'est un problème de priorisation du crawl.
Faut-il traiter différemment chaque crawler dans sa stratégie SEO ?
Oui, mais avec discernement. Bloquer Mediapartners-Google si vous n'utilisez pas AdSense est logique — ça libère du budget de crawl. En revanche, bloquer AdsBot-Google alors que vous faites du Google Ads peut dégrader votre Quality Score publicitaire.
Pour GoogleOther, la prudence s'impose. Certains SEO le bloquent pour économiser du crawl budget, d'autres le laissent passer pour éviter de contrarier d'éventuels tests Google. Aucune donnée publique fiable ne tranche le débat. Mon approche : le laisser actif sur les sites stratégiques, le bloquer sur les plateformes à crawl budget critique.
Impact pratique et recommandations
Comment auditer précisément l'activité de chaque crawler sur mon site ?
L'analyse des logs serveur bruts reste la méthode de référence. Segmentez les requêtes par user agent et identifiez quels bots accèdent à quelles sections, à quelle fréquence, et avec quels taux d'erreur.
Croisez ces données avec les rapports Search Console : si Googlebot Smartphone visite peu vos pages stratégiques alors que le trafic mobile est majoritaire, vous avez un problème de priorisation. Les outils comme Screaming Frog Log Analyzer ou OnCrawl facilitent cette segmentation.
Quelles règles robots.txt appliquer pour optimiser le budget de crawl multi-crawlers ?
Soyez sélectif et documenté. Bloquez explicitement les crawlers non pertinents pour votre modèle économique : Mediapartners-Google si pas d'AdSense, AdsBot-Google si pas de campagnes display, Google-Read-Aloud si vous n'avez pas d'ambition audio.
Autorisez toujours Googlebot, Googlebot-Image, Googlebot-Video et le crawler mobile prioritaire pour le mobile-first indexing. Testez chaque directive avec l'outil de test robots.txt de la Search Console — et vérifiez que les blocs n'impactent pas involontairement d'autres bots par effet de bord.
Que faire si un crawler spécifique semble ignorer certaines pages critiques ?
Identifiez d'abord la cause : robots.txt restrictif, meta noindex accidentelle, chaînes de redirection, profondeur de lien excessive. Utilisez l'outil d'inspection d'URL pour simuler le crawl du bot concerné.
Si le problème persiste malgré une configuration technique correcte, augmentez la visibilité interne de ces pages : ajoutez des liens depuis la home ou des hubs thématiques, soumettez un sitemap XML dédié, réduisez la profondeur d'arborescence. Pour les sites complexes avec des milliers d'URLs, un sitemap segmenté par type de contenu améliore la priorisation.
- Analysez vos logs serveur en segmentant par user agent (Googlebot Desktop, Smartphone, Image, etc.)
- Testez votre robots.txt contre chaque crawler pertinent via la Search Console
- Bloquez uniquement les bots non essentiels à votre stratégie (Mediapartners si pas d'AdSense, par exemple)
- Surveillez les rapports de couverture pour détecter des divergences entre crawlers mobile et desktop
- Optimisez la profondeur de lien et la structure interne pour les pages stratégiques sous-crawlées
- Documentez chaque directive robots.txt pour éviter les oublis lors des migrations ou refonte
❓ Questions frequentes
Mediapartners-Google impacte-t-il le référencement naturel de mon site ?
Puis-je bloquer Mediapartners-Google sans risque si je n'utilise pas AdSense ?
GoogleOther est-il important pour le SEO ?
Comment savoir quel crawler Google visite mes pages stratégiques ?
Le mobile-first indexing utilise-t-il exclusivement Googlebot Smartphone ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/05/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.