Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
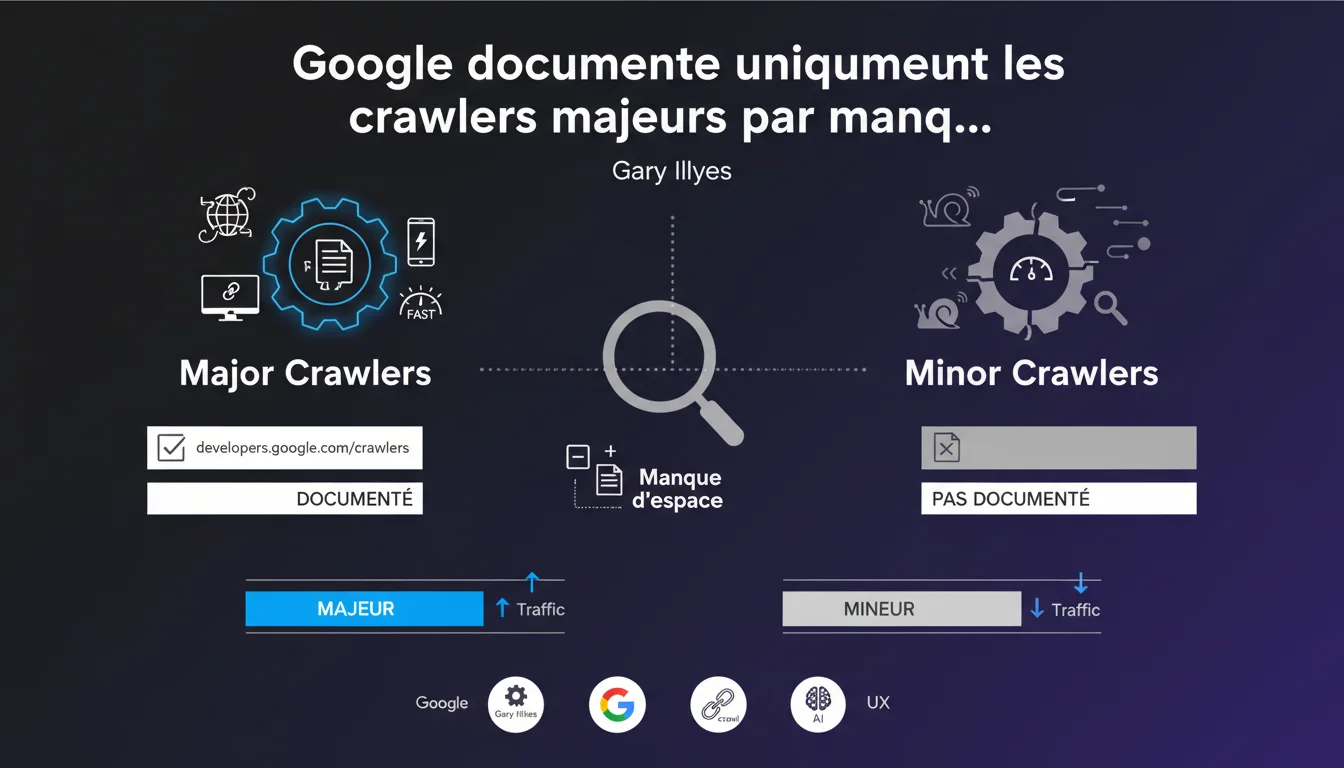
Google admet ne pas documenter l'ensemble de ses crawlers sur developers.google.com/crawlers. Seuls les crawlers majeurs et spéciaux figurent dans la liste officielle, les petits robots générant peu de trafic restent volontairement non documentés pour des raisons de « contraintes d'espace ». Cette révélation soulève des questions sur la transparence réelle de Google concernant l'activité de crawl sur nos sites.
Ce qu'il faut comprendre
Que signifie réellement cette « contrainte d'espace » invoquée par Google ?
L'argument avancé par Gary Illyes paraît pour le moins surprenant. Une page de documentation technique n'a pas vraiment de limite d'espace physique — nous ne sommes pas en train d'imprimer un manuel papier.
Ce que Google admet en creux, c'est qu'une partie de son infrastructure de crawl reste volontairement dans l'ombre. Les robots non documentés génèrent peu de trafic individuellement, mais leur cumul peut représenter une charge non négligeable sur certains sites. Le choix de ne pas les lister relève davantage d'une décision éditoriale que d'une impossibilité technique.
Quels crawlers Google considère-t-il comme « majeurs » ?
La documentation officielle liste une vingtaine de crawlers, dont Googlebot (desktop et mobile), Google-Extended, GoogleOther, ou encore les crawlers spécialisés comme AdsBot et Google-InspectionTool.
Ces robots ont des rôles clairement définis : indexation web, validation AMP, prévisualisation d'annonces, vérification de sécurité. Mais cette transparence ne couvre qu'une fraction de l'écosystème réel. Les crawlers internes dédiés aux tests, aux expérimentations ou à des services secondaires n'apparaissent nulle part.
Quelle est l'implication concrète pour l'analyse des logs serveur ?
Si vous analysez vos logs avec rigueur, vous avez probablement déjà repéré des user-agents Google non documentés. Certains ne matchent aucune entrée officielle, d'autres utilisent des patterns génériques difficiles à identifier formellement.
Cette opacité complique l'analyse du crawl budget et la détection d'anomalies. Comment distinguer un crawler légitime d'un bot malveillant usurpant un user-agent Google si la liste de référence est incomplète ?
- Google ne documente volontairement qu'une partie de ses crawlers
- L'argument des « contraintes d'espace » masque une décision éditoriale délibérée
- Les crawlers non documentés génèrent individuellement peu de trafic mais peuvent peser collectivement
- L'analyse des logs devient plus complexe sans référentiel exhaustif
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Absolument. Tout analyste SEO qui examine régulièrement ses logs serveur a déjà rencontré des user-agents Google mystérieux. Certains apparaissent sporadiquement, d'autres semblent liés à des projets expérimentaux jamais annoncés publiquement.
Le problème, c'est que Google valide ces crawlers via reverse DNS — mais sans documentation officielle, impossible de savoir pourquoi tel robot crawle telle section du site. On navigue à l'aveugle. Cette zone grise complique particulièrement la gestion des sites à fort volume de pages ou des infrastructures complexes. [A vérifier] : Google pourrait documenter au moins les patterns génériques de ces crawlers mineurs sans nécessairement détailler leur fonction exacte.
Quels risques cette opacité fait-elle peser sur les sites ?
Premier risque : la sur-consommation de crawl budget non détectée. Si vous bloquez agressivement les bots non identifiés, vous risquez de couper un service légitime de Google. Si vous laissez tout passer, vous gaspillez peut-être des ressources serveur sur des crawlers à faible valeur ajoutée.
Deuxième risque : la confusion avec des bots malveillants. Les scrapers usurpent régulièrement des user-agents Google. Sans liste exhaustive, comment valider la légitimité d'un crawler inconnu ? La vérification par reverse DNS fonctionne, mais elle demande une expertise technique que tous les webmasters n'ont pas.
Faut-il attendre plus de transparence de la part de Google ?
Soyons réalistes : Google n'a aucun intérêt stratégique à documenter exhaustivement tous ses crawlers internes. Certains servent probablement à des tests A/B, d'autres à du machine learning, d'autres encore à des projets abandonnés mais dont l'infrastructure tourne toujours.
La vraie question n'est pas « pourquoi Google ne documente pas tout » mais « comment s'adapter à cette réalité ». L'analyse des logs doit intégrer une part d'incertitude. Les outils de log analysis doivent maintenir leurs propres bases de données de user-agents observés, au-delà de la doc officielle.
Impact pratique et recommandations
Comment identifier les crawlers Google non documentés dans vos logs ?
La méthode de référence reste la vérification par reverse DNS. Récupérez l'IP du crawler, faites un reverse DNS lookup, puis vérifiez que le domaine obtenu appartient bien à Google (googlebot.com ou google.com). Enfin, faites un forward lookup pour confirmer que le domaine pointe vers l'IP d'origine.
Cette double vérification élimine les usurpations d'identité. Les crawlers légitimes, documentés ou non, passeront ce test. Les scrapers échoueront.
Faut-il bloquer les crawlers Google non documentés ?
Pas systématiquement. Si un crawler génère peu de trafic et ne pose aucun problème de charge serveur, laissez-le tranquille. Bloquer un service Google dont vous ignorez la fonction peut avoir des effets de bord imprévisibles.
En revanche, si vous détectez un crawler non documenté qui aspire massivement des ressources ou crawle des sections sensibles, vous pouvez le gérer via robots.txt ou via des règles serveur spécifiques. Documentez chaque intervention pour pouvoir faire marche arrière si nécessaire.
Quelles règles de robots.txt adopter face à cette opacité ?
Restez sur des directives génériques et prudentes. Bloquez par patterns de contenu plutôt que par user-agent : sections admin, fichiers de dev, pages de test. Évitez de blacklister des user-agents Google spécifiques sauf si vous êtes absolument certain de leur rôle et de l'absence d'impact.
Maintenez une whitelist des crawlers majeurs que vous voulez voir sur votre site. Pour tout le reste, adoptez une approche de surveillance active plutôt que de blocage préventif.
- Mettez en place une analyse régulière des logs serveur centrée sur les user-agents Google
- Documentez tous les crawlers Google non officiels que vous repérez avec leurs patterns d'activité
- Implémentez une procédure de vérification reverse DNS pour valider les crawlers inconnus
- Évitez les blocages massifs par user-agent — privilégiez le blocage sélectif par type de contenu
- Surveillez l'évolution de votre crawl budget global plutôt que de vous focaliser sur un crawler isolé
- Testez tout changement de robots.txt en environnement de staging avant déploiement en production
❓ Questions frequentes
Comment vérifier qu'un crawler inconnu appartient bien à Google ?
Est-ce risqué de bloquer un crawler Google non documenté ?
Où trouver la liste officielle des crawlers Google documentés ?
Les crawlers non documentés consomment-ils du crawl budget inutilement ?
Peut-on forcer Google à révéler tous ses crawlers ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.