Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
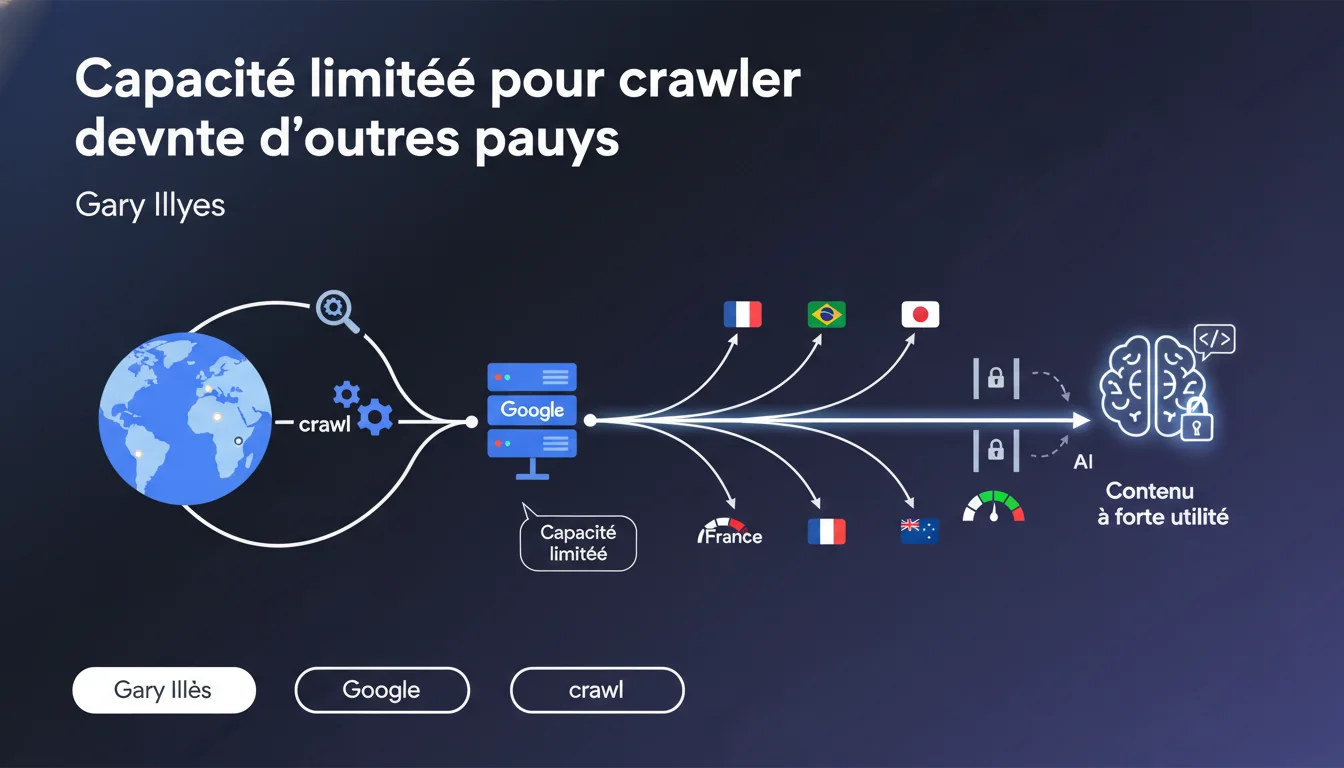
Google possède des IPs dans différents pays pour accéder aux contenus géobloqués, mais leur capacité de crawl est extrêmement limitée. Ces points de sortie internationaux sont réservés uniquement aux contenus jugés à forte utilité — autrement dit, la majorité du contenu géolocalisé ne sera jamais crawlé depuis ces IPs. Si votre stratégie repose sur du géoblocage, vous jouez avec le feu.
Ce qu'il faut comprendre
Qu'est-ce que cela signifie concrètement pour le crawl de Google ?
Google dispose d'une infrastructure distribuée à travers le monde, mais toutes les IPs ne se valent pas en termes de capacité. Les points de sortie situés dans des pays autres que les États-Unis n'ont qu'une fraction de la puissance de crawl disponible.
Concrètement ? Si votre site bloque l'accès selon la géolocalisation de l'IP, Google ne pourra pas crawler massivement depuis ces points de sortie internationaux. L'allocation de ces ressources est strictement rationnée — réservée aux contenus que Google juge suffisamment importants pour justifier cet effort.
Comment Google décide-t-il quel contenu mérite ces ressources limitées ?
Gary Illyes parle de « contenu à forte utilité », mais il ne précise pas les critères. On peut raisonnablement supposer qu'il s'agit de pages avec une forte demande utilisateur, des backlinks significatifs, ou un trafic organique établi depuis d'autres régions.
Le problème : si votre contenu géobloqué n'a pas encore démontré sa valeur, il risque de rester invisible. C'est un cercle vicieux — pas de crawl, pas d'indexation, pas de trafic, donc pas de signaux d'utilité.
Quelles sont les implications pour les sites avec versions régionales ?
Les sites avec des versions spécifiques par pays (ex : .fr accessible uniquement depuis la France) prennent un risque majeur. La majorité du crawl de Google se fait depuis les États-Unis, et si votre contenu est bloqué pour ces IPs, vous limitez drastiquement votre visibilité.
Même avec du hreflang correctement configuré, Google doit pouvoir accéder au contenu pour valider les signaux. Si le bot se heurte à un mur géographique, les balises hreflang ne servent à rien.
- Les IPs de Google hors États-Unis ont une capacité de crawl très réduite
- Seul le contenu jugé « à forte utilité » bénéficie de ces ressources limitées
- Le géoblocage strict empêche l'indexation correcte, même avec hreflang
- Pas de crawl = pas de signaux d'utilité = cercle vicieux
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Absolument. Depuis des années, on constate que les sites avec géoblocage strict rencontrent des problèmes d'indexation récurrents. Pages non découvertes, versions régionales ignorées, hreflang non pris en compte — tout cela s'explique par cette limitation de capacité.
Ce qui est intéressant, c'est que Gary Illyes l'avoue enfin ouvertement. Avant, Google restait vague sur le sujet, laissant croire que le bot pouvait crawler « depuis n'importe où ». La réalité est moins rose : la majorité du crawl reste concentré sur les IPs américaines, et le reste est du dépannage ponctuel.
Quelles zones d'ombre subsistent dans cette déclaration ?
Gary Illyes ne définit pas précisément ce qu'est un « contenu à forte utilité ». Est-ce basé sur la Search Console ? Les liens entrants ? Le trafic direct ? La popularité de la marque ? [À vérifier] — aucune métrique claire n'est fournie.
Autre flou : quelle est exactement cette « capacité limitée » ? On parle d'un ratio de 1 pour 10 ? 1 pour 100 ? Sans chiffres, difficile d'évaluer le risque réel. Ce qu'on sait par expérience : si votre site n'est pas majeur, ne comptez pas sur ces IPs internationales.
Dans quels cas cette règle pourrait-elle être contournée ?
Il existe des cas où Google peut obtenir le contenu sans passer par le crawl classique. Par exemple, si votre contenu est distribué via des APIs tierces, des flux RSS largement relayés, ou si des CDN exposent vos données sans restriction géographique.
Mais soyons honnêtes : ces cas sont minoritaires. La majorité des sites avec géoblocage se retrouvent dans une impasse — pas de crawl, pas d'indexation. Et même si Google accède ponctuellement au contenu, rien ne garantit une indexation complète ou régulière.
Impact pratique et recommandations
Que faut-il faire concrètement si votre site utilise du géoblocage ?
Première règle : ne bloquez jamais les bots de Google, quelle que soit leur IP d'origine. Utilisez le fichier robots.txt ou les en-têtes X-Robots-Tag pour contrôler l'indexation, mais laissez toujours l'accès au contenu.
Si vous devez absolument restreindre l'accès géographiquement (conformité légale, droits de diffusion), configurez une exception pour les user-agents Googlebot. Cela permet au bot de crawler depuis n'importe quelle IP tout en maintenant vos restrictions pour les utilisateurs humains.
Comment vérifier que votre site n'est pas victime de ce problème ?
Utilisez la Search Console pour surveiller les erreurs de crawl liées aux versions régionales. Si des pages importantes ne sont pas indexées ou si les balises hreflang ne sont pas détectées, c'est souvent lié au géoblocage.
Testez également avec l'outil d'inspection d'URL : soumettez vos URLs régionales et vérifiez que Google peut bien accéder au contenu. Si vous constatez des blocages, ajustez immédiatement vos règles de géolocalisation.
Quelles erreurs éviter absolument ?
Ne comptez pas sur les balises hreflang pour compenser un géoblocage strict — elles ne fonctionnent que si Google peut accéder au contenu. Beaucoup de sites pensent qu'indiquer une version alternative suffit, mais si cette version est bloquée, hreflang est inutile.
Autre erreur fréquente : bloquer les IPs suspectes « par précaution ». Si vous utilisez un WAF ou un CDN avec géofiltrage automatique, vérifiez que les ranges d'IPs de Google ne sont pas blacklistées par erreur. Cela arrive plus souvent qu'on ne le croit.
- Autoriser explicitement tous les user-agents Googlebot, quelle que soit l'IP d'origine
- Vérifier régulièrement la Search Console pour détecter les erreurs de crawl régionales
- Tester l'accès au contenu via l'outil d'inspection d'URL pour chaque version linguistique/régionale
- Auditer les règles de géofiltrage du WAF/CDN pour éviter de bloquer Google par erreur
- Ne pas compter uniquement sur hreflang — le contenu doit être accessible avant tout
- Documenter les exceptions géographiques pour Googlebot dans la configuration serveur
❓ Questions frequentes
Google crawle-t-il mon contenu géobloqué depuis des IPs locales ?
Puis-je bloquer les IPs américaines de Google si mon audience est uniquement européenne ?
Les balises hreflang fonctionnent-elles si mon contenu est géobloqué ?
Comment autoriser Googlebot tout en maintenant un géoblocage pour les utilisateurs ?
Comment savoir si mon site est affecté par cette limitation de crawl ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.