Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
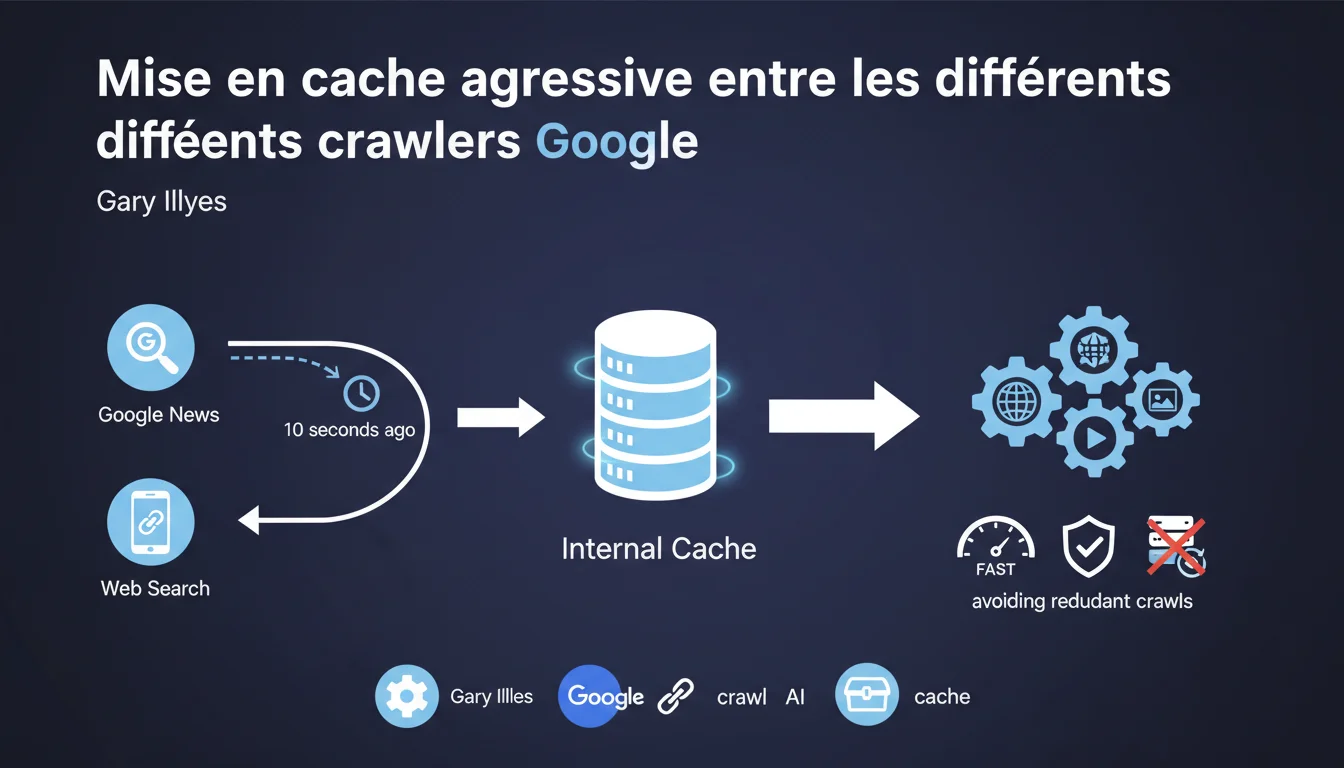
Google utilise un cache interne agressif qui permet à ses différents robots (Search, News, etc.) de partager les versions crawlées d'une même page. Si Google News crawle votre page, Googlebot Search peut réutiliser cette copie quelques secondes plus tard au lieu de refaire une requête HTTP. Ce mécanisme contourne totalement les directives HTTP standard et impacte directement votre crawl budget.
Ce qu'il faut comprendre
Comment fonctionne ce cache partagé entre crawlers ?
Google maintient un cache interne centralisé qui stocke temporairement les versions crawlées de vos pages. Quand Google News visite votre article à 10h00, cette copie est mise en cache. Si Googlebot Search décide de crawler la même URL à 10h00:10, il récupère directement la version cachée au lieu de solliciter à nouveau votre serveur.
Ce système fonctionne indépendamment des headers HTTP classiques (Cache-Control, ETag, Last-Modified). Vous ne contrôlez pas ce cache via vos configurations serveur habituelles. Google décide seul de la durée de rétention et des conditions de réutilisation.
Pourquoi Google a-t-il mis en place ce mécanisme ?
L'objectif affiché est d'optimiser le crawl budget global et de réduire la charge sur les serveurs web. En évitant les crawls redondants entre services, Google économise des ressources et limite l'impact sur votre infrastructure.
Mais soyons honnêtes : ce système sert aussi les intérêts de Google. Moins de requêtes HTTP = moins de bande passante consommée côté Googlebot, donc crawl plus rapide et moins coûteux pour eux.
Quelle est la durée de rétention de ce cache ?
Gary Illyes mentionne 10 secondes dans son exemple, mais aucune donnée précise n'est fournie sur la durée maximale. Est-ce 10 secondes, 1 minute, 5 minutes ? Impossible à dire officiellement.
Ce flou est problématique. Sans fenêtre temporelle claire, difficile d'anticiper quand vos modifications seront effectivement recrawlées par tous les robots concernés.
- Google partage les versions crawlées entre ses différents bots (Search, News, Discover, etc.)
- Ce cache fonctionne indépendamment des mécanismes HTTP standard que vous contrôlez
- La durée de rétention reste floue — au moins quelques secondes, probablement plus
- Objectif affiché : réduire les crawls redondants et préserver votre crawl budget
- Implication : une page peut être indexée avec une version crawlée par un autre service Google
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement cohérente. On observe régulièrement des décalages entre le moment où une page est modifiée et celui où tous les services Google reflètent le changement. Par exemple, vous corrigez un titre à 14h, Google News l'affiche à 14h02, mais la Search Console montre encore l'ancien titre 10 minutes plus tard.
Ce cache partagé explique aussi pourquoi certaines pages apparaissent dans Google Discover avec un snippet crawlé par Googlebot-News, même si la version "principale" indexée diffère légèrement. Les incohérences qu'on attribuait à des bugs de synchronisation trouvent ici une explication structurelle.
Quelles sont les limites de cette transparence ?
Gary Illyes reste vague sur les détails critiques. Quelle est la durée maximale de ce cache ? Quels critères déterminent qu'une page doit être recrawlée plutôt que réutilisée ? Tous les robots Google participent-ils à ce cache, ou seulement certains ?
Autre point : cette déclaration ne précise pas comment ce mécanisme interagit avec les mises à jour urgentes. Si vous corrigez une erreur factuelle grave, pouvez-vous forcer une invalidation du cache ? Rien n'indique que les outils comme l'inspection d'URL contournent ce système. [A vérifier]
Dans quels cas ce mécanisme pose-t-il problème ?
Pour les sites d'actualité qui publient des breaking news ou des mises à jour fréquentes, ce cache peut créer des décalages embarrassants. Vous corrigez un titre trompeur, mais Google continue de servir l'ancienne version pendant plusieurs secondes — voire minutes — à certains utilisateurs via différents points d'entrée.
Même problème pour les sites e-commerce gérant des stocks en temps réel. Si Google News crawle une fiche produit "en stock", puis que Googlebot Search réutilise cette copie alors que le produit est épuisé, les utilisateurs atterrissent sur une page incohérente.
Impact pratique et recommandations
Que faut-il faire concrètement pour s'adapter ?
Première action : ne comptez plus uniquement sur les headers HTTP pour gérer la fraîcheur de vos contenus critiques. Cache-Control et ETag restent utiles pour les navigateurs et CDN, mais ils ne garantissent plus que Google recrawlera immédiatement chaque bot.
Pour les contenus urgents (breaking news, corrections factuelles), utilisez systématiquement l'outil d'inspection d'URL dans la Search Console et demandez une réindexation. Même si Gary Illyes ne le confirme pas explicitement, c'est votre seul levier pour court-circuiter potentiellement ce cache.
Adaptez vos workflows de publication. Si vous publiez simultanément sur plusieurs canaux (site web, AMP, app), synchronisez les mises à jour au plus près pour éviter que Google ne cache une version intermédiaire incohérente entre services.
Quelles erreurs éviter absolument ?
Ne présumez jamais qu'une modification sera instantanément visible partout dans l'écosystème Google. Un changement de title visible dans la SERP Search ne signifie pas que Google News, Discover ou la version AMP affichent la même version.
Évitez de déclencher des crawls massifs simultanés via plusieurs canaux (sitemap News + sitemap classique + IndexNow + inspection manuelle). Vous risquez de créer des incohérences si différents bots crawlent à des moments décalés et que le cache propage une version intermédiaire.
Comment vérifier l'impact sur votre site ?
Surveillez les décalages de fraîcheur entre les différents services Google. Comparez régulièrement ce que montrent la Search Console, Google News, Discover et la recherche classique pour une même URL après une modification.
Analysez vos logs serveur pour identifier les patterns de crawl. Si vous constatez que Googlebot-News visite systématiquement avant Googlebot, puis que ce dernier ne recrawle pas immédiatement, vous observez probablement ce cache en action.
- Utilisez l'inspection d'URL pour forcer la réindexation des contenus critiques après modification
- Synchronisez vos publications multi-canaux pour éviter les versions intermédiaires incohérentes
- Surveillez les décalages de fraîcheur entre Search, News et Discover via la Search Console
- Analysez vos logs pour repérer les patterns de crawl partagé entre bots Google
- Ne présumez jamais qu'un changement est instantanément propagé partout
- Documentez les délais observés entre modification et affichage dans chaque service Google
❓ Questions frequentes
Puis-je désactiver ce cache partagé pour mon site ?
L'outil d'inspection d'URL contourne-t-il ce cache ?
Quelle est la durée maximale de rétention du cache ?
Tous les robots Google partagent-ils ce cache ?
Ce cache impacte-t-il le crawl budget de mon site ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.