Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
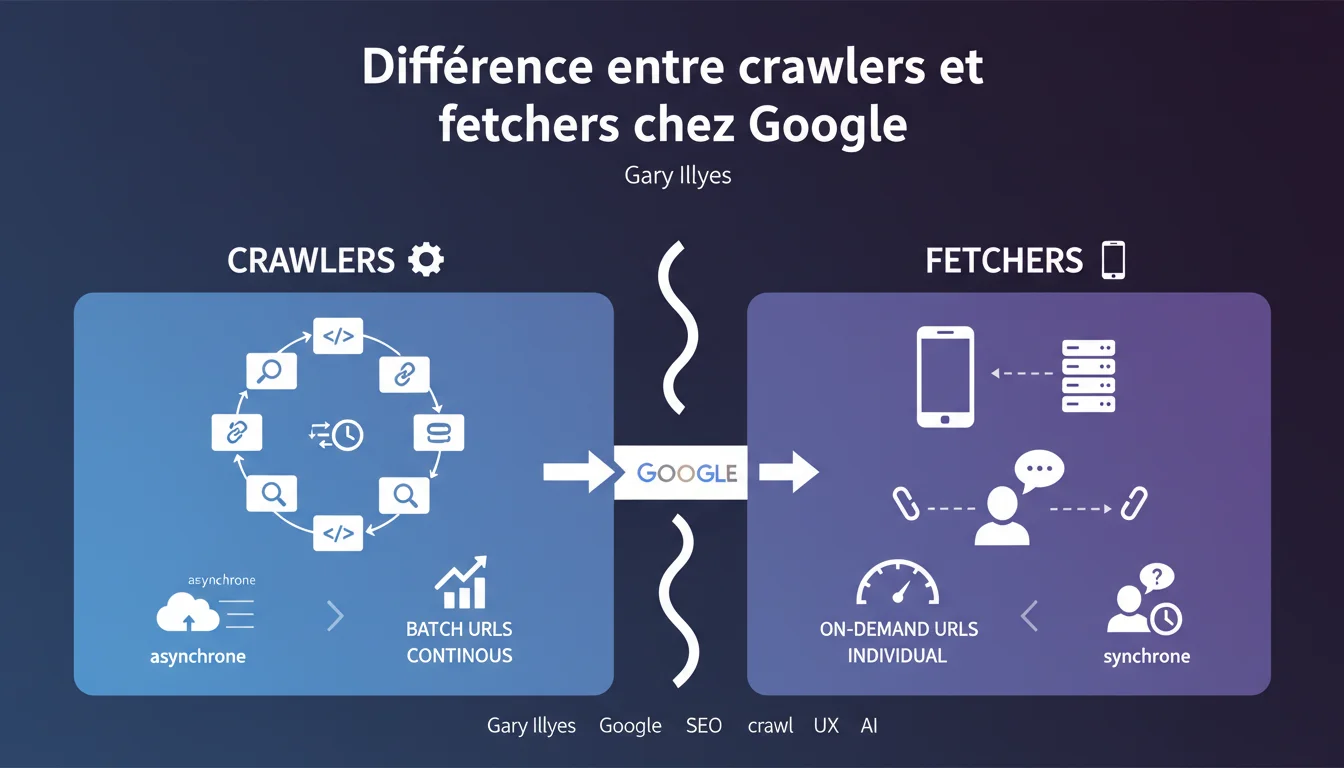
Google distingue clairement ses crawlers (traitement batch asynchrone) de ses fetchers (requêtes individuelles synchrones déclenchées par un utilisateur). Cette distinction technique impacte directement la manière dont vos pages sont explorées, indexées et affichées dans les outils pour webmasters. Comprendre cette différence permet d'interpréter correctement les logs serveur et d'optimiser les ressources allouées au crawl.
Ce qu'il faut comprendre
Cette déclaration de Gary Illyes lève le voile sur une architecture technique fondamentale de Google que beaucoup de SEO confondent encore. Les crawlers (Googlebot classique) et les fetchers (outils de test, URL Inspection Tool) n'ont ni les mêmes objectifs, ni les mêmes contraintes opérationnelles.
Quelle est la différence concrète entre un crawler et un fetcher ?
Un crawler traite des URLs par lots, de manière asynchrone. Il n'attend pas qu'un humain consulte le résultat — il parcourt le web en continu, selon ses propres priorités et son propre rythme. Le Googlebot indexation fonctionne ainsi : il visite votre site, collecte les données, et les traite plus tard dans le pipeline d'indexation.
Un fetcher répond à une demande individuelle, généralement déclenchée par un utilisateur via un outil (Search Console, Mobile-Friendly Test, Rich Results Test). Il charge l'URL demandée, exécute le rendu si nécessaire, et renvoie le résultat immédiatement. Le fetcher est donc synchrone : quelqu'un attend la réponse.
Pourquoi cette distinction est-elle importante pour le SEO ?
Parce qu'elle explique des comportements apparemment incohérents que vous observez dans vos logs ou dans Search Console. Un fetcher peut très bien charger correctement une ressource CSS critique alors que le crawler, lui, se la voit bloquer par le robots.txt ou un timeout serveur.
Les fetchers ont souvent des quotas plus stricts et des comportements légèrement différents en matière de rendu JavaScript, de gestion des redirections ou de respect des en-têtes HTTP. Si vous testez une URL dans l'outil d'inspection et que tout semble parfait, ça ne garantit pas que le crawler indexation verra exactement la même chose.
Quels sont les cas d'usage typiques de chaque système ?
Crawlers : exploration systématique du web, découverte de nouvelles URLs, suivi des mises à jour de contenu, collecte de signaux pour le ranking. Ils opèrent en mode « fire and forget » — ils n'attendent pas de feedback immédiat.
Fetchers : validation ponctuelle d'une URL, tests de compatibilité mobile, extraction de structured data pour affichage dans les outils webmaster, inspection à la demande. Ils opèrent en mode « requête-réponse » avec un timeout court.
- Les crawlers traitent des millions d'URLs quotidiennement, de manière automatisée et priorisée.
- Les fetchers répondent à des demandes ponctuelles d'utilisateurs, avec des contraintes de temps réel.
- Un fetcher peut échouer alors que le crawler réussit, et inversement — notamment en cas de charge serveur variable.
- Les logs serveur montrent souvent les deux types de bots avec des user-agents légèrement différents ou des patterns de requêtes distincts.
- Cette distinction impacte directement l'allocation de crawl budget : les fetchers n'en consomment généralement pas.
Avis d'un expert SEO
Cette distinction est-elle vraiment nouvelle ou juste une clarification ?
Soyons honnêtes : cette séparation existe depuis des années dans l'infrastructure Google. Ce qui change, c'est que Google la verbalise explicitement. Avant, on déduisait cette différence en analysant les logs et les comportements incohérents entre l'URL Inspection Tool et l'indexation réelle.
Gary Illyes formalise ici ce que les SEO techniques observent depuis longtemps. Le problème ? Beaucoup de praticiens utilisent encore l'outil d'inspection comme oracle de vérité absolue pour l'indexation, alors qu'il s'appuie sur un fetcher — pas sur le crawler qui indexe vraiment vos pages.
Dans quels cas cette distinction pose-t-elle problème en pratique ?
Le cas classique : votre serveur est sous charge. Le fetcher arrive, demande une URL, reçoit une réponse rapide parce que c'est une requête isolée. Vous validez dans Search Console, tout est vert. Deux heures plus tard, le crawler débarque avec 50 requêtes simultanées, votre serveur sature, les timeouts explosent.
Résultat : indexation partielle, ressources bloquées, rendu JavaScript incomplet. Mais l'outil d'inspection vous dit que tout va bien. [A verifier] : Google n'a jamais précisé si les fetchers respectent exactement les mêmes règles de rate limiting que les crawlers — mes observations terrain suggèrent que non.
Autre cas problématique : les redirections temporaires. Un fetcher peut interpréter une 302 différemment d'un crawler batch qui voit la même 302 répétée sur plusieurs passages. Le fetcher teste ponctuellement, le crawler agrège des signaux dans le temps.
Faut-il adapter ses stratégies de test et de monitoring ?
Absolument. Si vous vous fiez uniquement aux outils de test Google (qui utilisent des fetchers), vous passez à côté de problèmes que seuls les logs serveur révèlent. Un fetcher ne vous dira jamais que votre serveur peine à gérer le crawl budget alloué.
Concrètement : testez avec les outils Google, mais validez avec vos logs. Analysez le comportement réel du Googlebot crawler, ses patterns de requêtes, ses erreurs 5xx, ses timeouts. C'est là que vous verrez si votre infra tient la route face à un crawl intensif.
Impact pratique et recommandations
Comment identifier dans vos logs si une requête provient d'un crawler ou d'un fetcher ?
Analysez les user-agents : Google utilise parfois des variantes subtiles (GoogleOther pour certains fetchers, Googlebot standard pour les crawlers). Mais le signal le plus fiable reste le pattern de requêtes.
Un fetcher demande une URL unique, attend la réponse, disparaît. Un crawler arrive en rafale, parcourt plusieurs dizaines d'URLs en quelques minutes, revient régulièrement. Les fetchers génèrent des pics isolés, les crawlers des vagues soutenues.
Quelles erreurs éviter lors de l'optimisation du crawl ?
Ne dimensionnez pas votre infrastructure uniquement en testant avec l'URL Inspection Tool. Ce fetcher ne simule pas la charge réelle qu'un crawler batch impose à votre serveur. Testez en conditions réalistes : simulez des crawls intensifs, mesurez les temps de réponse sous charge, vérifiez que votre serveur ne sature pas.
Autre erreur classique : bloquer certains crawlers dans le robots.txt en pensant économiser du crawl budget, puis s'étonner que les outils de test (fetchers) continuent de fonctionner. Les fetchers ne respectent pas toujours les mêmes règles — ils peuvent ignorer certaines directives pour fournir un résultat à l'utilisateur qui attend.
Que faut-il monitorer concrètement pour anticiper les problèmes ?
- Analysez vos logs serveur pour différencier les fetchers des crawlers selon les patterns de requêtes.
- Mesurez les temps de réponse moyens lors des pics de crawl, pas seulement sur des requêtes isolées.
- Vérifiez que votre serveur gère correctement les requêtes simultanées sans timeouts ni erreurs 5xx.
- Testez le rendu JavaScript sous charge — un fetcher peut réussir à exécuter votre JS, le crawler batch peut échouer si le serveur rame.
- Comparez les résultats de l'URL Inspection Tool avec les URLs effectivement indexées — toute divergence signale un problème.
- Documentez les user-agents distincts que vous observez et leurs comportements respectifs.
- Configurez des alertes sur les erreurs 5xx et timeouts pendant les pics de crawl identifiés dans vos logs.
❓ Questions frequentes
Les fetchers consomment-ils du crawl budget au même titre que les crawlers ?
Pourquoi l'URL Inspection Tool affiche parfois un résultat différent de l'indexation réelle ?
Un fetcher respecte-t-il le robots.txt de la même manière qu'un crawler ?
Comment savoir si mes problèmes d'indexation viennent du crawler ou du fetcher ?
Les fetchers exécutent-ils le JavaScript de la même manière que les crawlers ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.