Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
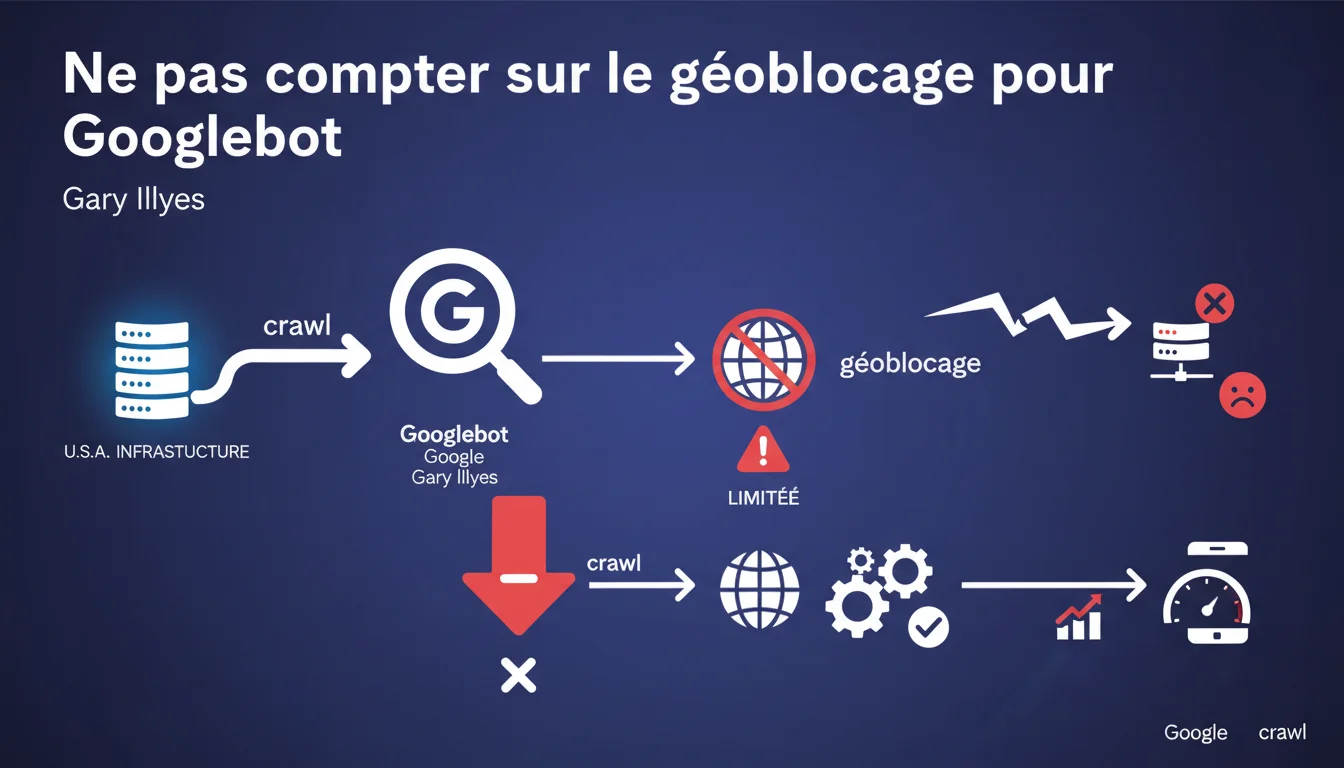
Google déconseille formellement de bloquer Googlebot en fonction de sa géolocalisation. L'infrastructure de crawl principale est basée aux États-Unis, et les capacités alternatives de Google pour crawler depuis d'autres zones géographiques restent très limitées. Si votre site géobloque les IPs américaines, vous risquez tout simplement de ne pas être crawlé correctement.
Ce qu'il faut comprendre
Qu'est-ce que le géoblocage et pourquoi certains sites l'utilisent-ils ?
Le géoblocage consiste à restreindre l'accès à un site web en fonction de la localisation géographique de l'utilisateur. Cette pratique s'appuie sur l'adresse IP du visiteur pour déterminer son pays d'origine et décider si l'accès doit être autorisé ou refusé.
Plusieurs raisons poussent certaines entreprises à géobloquer leur site. Des contraintes légales d'abord — RGPD, réglementations sectorielles, droits de diffusion. Certains contenus ne peuvent légalement être accessibles que depuis certains territoires. Ensuite, il y a des motivations commerciales : éviter les comparaisons de prix entre marchés, protéger des accords de distribution exclusifs, ou tout simplement ne pas proposer de service dans une zone géographique donnée.
Où se trouve concrètement l'infrastructure de crawl de Google ?
Gary Illyes est explicite : l'infrastructure principale de crawl opère depuis les États-Unis. Googlebot envoie donc la majorité de ses requêtes depuis des adresses IP américaines.
Google dispose certes de capacités alternatives pour crawler depuis d'autres régions, mais Illyes précise que ces capacités sont « très limitées ». Concrètement ? Si vous comptez sur un crawl depuis l'Europe ou l'Asie parce que votre site bloque les IPs US, vous jouez à la roulette russe avec votre indexation.
Quels sont les risques concrets pour votre référencement ?
Le risque numéro un, c'est simple : ne pas être crawlé du tout. Ou du moins, être crawlé de manière si sporadique que vos nouvelles pages mettent des semaines à être découvertes, que vos mises à jour ne soient pas prises en compte, que votre crawl budget soit dramatiquement réduit.
Deuxième risque : une indexation partielle et incohérente. Certaines sections de votre site pourraient être accessibles lors de rares passages d'une IP alternative, d'autres jamais. Résultat : une visibilité erratique, des pages orphelines dans l'index, une impossibilité de prédire ce qui sera effectivement référencé.
- Le crawl depuis les États-Unis représente l'essentiel du trafic Googlebot
- Les capacités de crawl depuis d'autres régions sont très limitées
- Bloquer les IPs américaines = risquer un crawl défaillant
- L'indexation devient imprévisible et partielle
- Le crawl budget chute drastiquement si Googlebot est géobloqué
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Totalement. Les analyses de logs montrent systématiquement une prédominance écrasante des IPs américaines dans le trafic Googlebot. Les crawls depuis d'autres régions existent, mais représentent une fraction minuscule — souvent moins de 5% du volume total.
Ce que Gary Illyes ne dit pas explicitement, c'est que ces crawls alternatifs semblent principalement dédiés à des cas d'usage spécifiques : vérifications ponctuelles pour les résultats localisés, tests de performances géographiques, peut-être des crawls de validation. Mais compter dessus pour un crawl systématique de votre site ? Illusion pure.
Dans quels cas le géoblocage est-il malgré tout inévitable ?
Soyons réalistes : certains sites n'ont pas le choix. Des contraintes légales strictes — diffusion de contenus soumis à licences territoriales, services financiers régulés, secteurs de la santé avec des autorisations pays par pays. Dans ces cas, le géoblocage n'est pas une option mais une obligation.
La vraie question devient alors : comment minimiser l'impact SEO ? Et c'est là que Google reste étonnamment vague. Illyes déconseille le géoblocage mais n'offre aucune solution alternative concrète pour les sites qui y sont contraints. [A vérifier] : existe-t-il réellement des mécanismes permettant à Googlebot de s'identifier de manière fiable pour être exempté du géoblocage, au-delà de la simple vérification DNS inverse ?
Quelles sont les zones grises de cette recommandation ?
Premier point flou : Google ne précise pas si cette infrastructure américaine concerne tous les types de crawl. Googlebot Desktop, Mobile, Image, News — tous depuis les US ? Ou certains bots spécialisés opèrent-ils depuis d'autres régions ? Silence radio.
Deuxième zone grise : les « capacités alternatives très limitées ». Limitées comment ? En volume de requêtes ? En fréquence ? En couverture géographique ? Cette formulation reste désespérément évasive. Pour un praticien qui doit prendre des décisions, c'est frustrant.
Impact pratique et recommandations
Comment vérifier si votre site géobloque Googlebot ?
Première étape : analysez vos logs serveur. Cherchez les requêtes Googlebot et cartographiez leurs IPs d'origine. Si vous ne voyez quasiment que des IPs américaines et que votre trafic Googlebot a chuté après la mise en place d'un géoblocage, le diagnostic est posé.
Utilisez Google Search Console. Consultez les statistiques d'exploration : une baisse brutale du nombre de pages crawlées, une augmentation des erreurs serveur (403, 451), des temps de réponse incohérents — autant de signaux d'alerte.
Testez manuellement avec un VPN américain. Si votre site est accessible depuis les US mais bloqué depuis l'Europe, et que vous constatez simultanément des problèmes d'indexation, la corrélation est évidente.
Quelles solutions techniques existent pour concilier géoblocage et SEO ?
Solution classique : whitelister les IPs de Googlebot. Google publie les plages d'adresses IP de ses bots. Configurez votre pare-feu ou votre CDN pour autoriser ces IPs spécifiquement, même si elles proviennent d'une zone géographique normalement bloquée.
Problème ? Ces listes d'IPs évoluent. Vous devez mettre en place un système de mise à jour automatique, idéalement en interrogeant régulièrement les DNS inverses de Google pour valider l'authenticité des bots. C'est faisable mais ça demande une infrastructure technique solide.
Alternative : utiliser le user-agent plutôt que la géolocalisation IP pour autoriser Googlebot. Attention cependant — cette méthode ouvre des failles de sécurité potentielles si elle n'est pas couplée à une vérification DNS inverse. N'importe qui peut usurper un user-agent.
Que faire si le géoblocage est une obligation légale ?
Documentez précisément les raisons légales qui imposent ce géoblocage. Implémentez ensuite une exception technique spécifique pour Googlebot, en vous assurant que cette exception ne viole pas les contraintes réglementaires — ce qui est généralement le cas puisque Googlebot n'est pas un utilisateur final.
Communiquez avec les équipes juridiques et techniques. Le géoblocage pour raisons légales cible les utilisateurs humains dans certaines juridictions, pas les moteurs de recherche qui indexent le contenu. Juridiquement, autoriser Googlebot ne pose généralement aucun problème.
- Auditez vos logs pour identifier la provenance des requêtes Googlebot
- Vérifiez dans Search Console si votre taux de crawl a chuté
- Whitelistez les plages IP officielles de Googlebot dans votre pare-feu
- Mettez en place une vérification DNS inverse pour authentifier Googlebot
- Automatisez la mise à jour des listes d'IPs autorisées
- Testez régulièrement l'accessibilité de votre site depuis différentes IPs Googlebot
- Documentez vos exceptions de géoblocage pour les audits de sécurité
❓ Questions frequentes
Google peut-il crawler mon site depuis l'Europe si je bloque les IPs américaines ?
Comment autoriser Googlebot sans désactiver complètement mon géoblocage ?
Le géoblocage affecte-t-il tous les types de Googlebot (Desktop, Mobile, Image) ?
Mon site est légalement obligé de géobloquer certains pays, que faire ?
Comment savoir si mon site bloque actuellement Googlebot ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.