Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
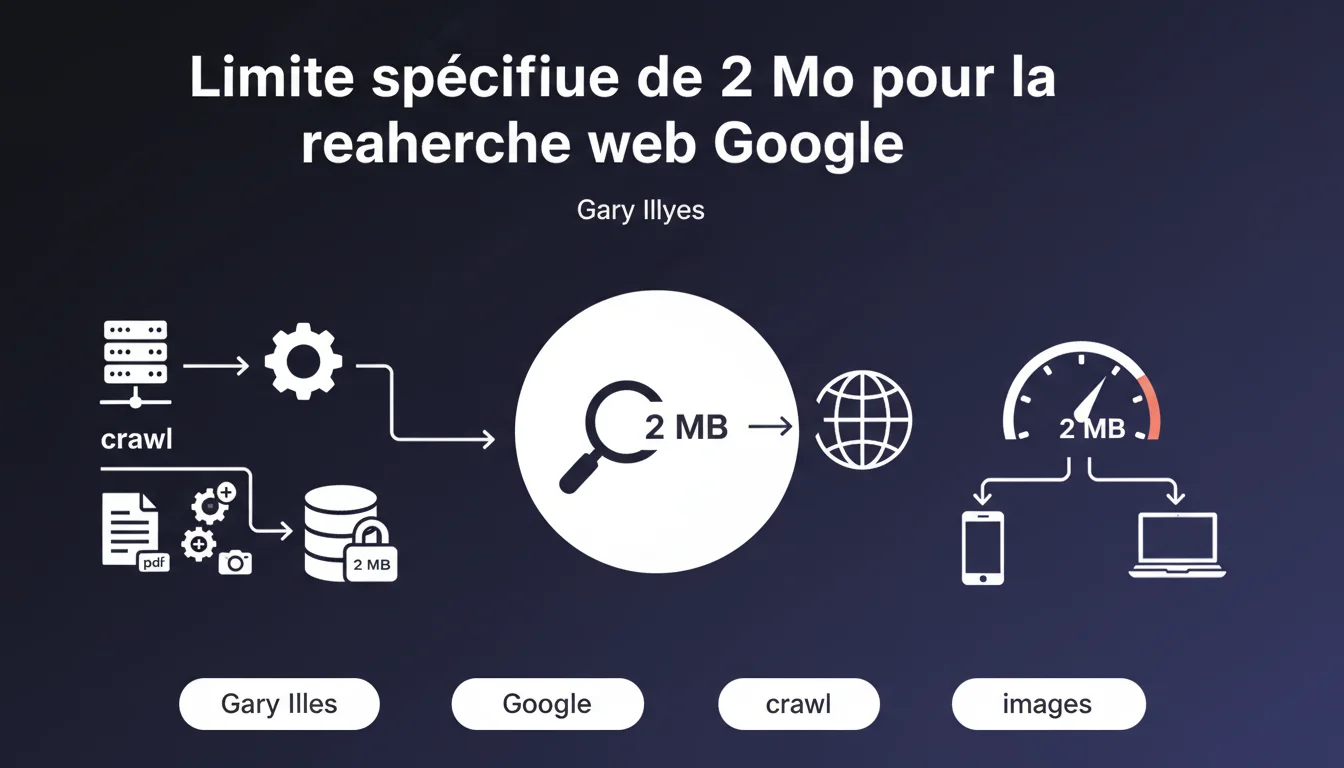
Google limite le crawl de la plupart des contenus web à 2 Mo maximum. Cette contrainte technique impacte directement l'indexation des pages lourdes, notamment celles utilisant du JavaScript excessif ou des frameworks gourmands. Concrètement : si votre HTML pèse plus de 2 Mo, Google tronque le contenu et indexe partiellement — ou pas du tout.
Ce qu'il faut comprendre
Cette limite de 2 Mo s'applique-t-elle vraiment à tous les types de contenus ?
Non. Gary Illyes précise que cette limite concerne "la plupart des contenus" pour la recherche web classique. Les PDFs et images bénéficient d'ajustements spécifiques selon leur nature.
Cette nuance compte : un PDF de 5 Mo peut être crawlé et indexé, tandis qu'une page HTML de 2,5 Mo sera tronquée. Google adapte ses règles selon le format pour optimiser ses ressources de traitement.
Qu'est-ce qui compte exactement dans ces 2 Mo ?
La limite porte sur le HTML brut renvoyé par le serveur, avant tout traitement JavaScript. Cela inclut le code source initial, les balises, les scripts inline — bref, ce que Googlebot reçoit en première requête HTTP.
Les ressources externes (CSS, JS, images chargées séparément) ne comptent pas dans ce calcul. Mais attention : si vous injectez massivement du contenu via JavaScript après le chargement initial, ce contenu risque de ne jamais être vu par Google si le rendu dépasse la limite.
Pourquoi Google impose-t-il cette contrainte technique maintenant ?
Parce que les sites modernes sont devenus obèses. Entre les frameworks JavaScript mal optimisés, les builders de pages qui génèrent du HTML redondant et les CMS mal configurés, certaines pages atteignent des tailles absurdes.
Google doit traiter des milliards de pages. Cette limite protège son infrastructure contre les abus et force les développeurs à optimiser. C'est aussi un signal : si votre page fait 3 Mo, vous avez un problème de conception, pas juste un problème d'indexation.
- La limite s'applique au HTML brut initial, pas aux ressources externes
- Les PDFs et images ont des seuils ajustés selon leur nature
- Un dépassement entraîne une troncature du contenu, pas nécessairement un refus total d'indexation
- Cette règle existait déjà officieusement — Google la formalise pour clarifier les attentes
Avis d'un expert SEO
Cette limite était-elle vraiment inconnue avant cette déclaration ?
Non. Les SEO avertis connaissent cette contrainte depuis des années, même si Google ne l'avait jamais officialisée aussi clairement. Les tests terrain montraient déjà que les pages volumineuses posaient problème.
Ce qui change, c'est la formalisation publique. Gary Illyes met un chiffre précis là où on naviguait dans le flou. Mais honnêtement ? Si votre HTML approche 2 Mo, le problème ne date pas d'hier.
Tous les sites sont-ils réellement concernés par ce plafond ?
La majorité des sites classiques ne frôlent jamais cette limite. Un article de blog optimisé pèse 50-200 Ko. Une fiche produit e-commerce bien codée tourne autour de 100-300 Ko.
Par contre — et c'est là que ça coince — certains sites construits avec des page builders (Elementor en mode bourrin, Divi mal paramétré) ou des SPAs (Single Page Applications) mal architecturées explosent facilement le compteur. Les plateformes qui chargent tout le catalogue produit en JSON inline pour des filtres côté client ? Pareil.
Google est-il cohérent entre cette limite et son discours sur le JavaScript ?
Là, ça devient intéressant. Google pousse le rendu JavaScript depuis des années, encourageant les frameworks modernes. Mais ces frameworks génèrent souvent du HTML gonflé — React, Vue, Angular produisent du code verbeux.
[À vérifier] : comment Google gère-t-il exactement le cas d'une SPA qui charge 500 Ko d'HTML initial puis injecte 2 Mo de contenu via JS ? Officiellement, il devrait indexer le contenu rendu. Dans les faits, si le rendu final post-JavaScript dépasse 2 Mo, quelle partie est tronquée ? Google reste flou sur ce point précis.
Mon avis ? Cette limite sert surtout de garde-fou contre les dérives architecturales. Si vous atteignez 2 Mo, votre problème n'est pas SEO — c'est un problème de conception web fondamental.
Impact pratique et recommandations
Comment vérifier si vos pages dépassent cette limite ?
Utilisez curl en ligne de commande pour récupérer le Content-Length exact de vos pages critiques. La commande curl -I https://votresite.com/page vous donne la taille en octets du HTML brut.
Pour une analyse à grande échelle, paramétrez un crawl avec Screaming Frog ou Oncrawl en activant le suivi des tailles de réponse HTTP. Filtrez ensuite les URLs dont le HTML dépasse 1,5 Mo — elles méritent un audit immédiat.
- Auditez systématiquement les pages générant plus de 500 Ko de HTML
- Identifiez les frameworks ou plugins qui injectent du code redondant
- Nettoyez le HTML inline inutile : JSON-LD surdimensionné, CSS/JS non externalisés, commentaires de debug
- Pour les SPAs, vérifiez que le contenu critique apparaît dans le HTML initial, pas seulement après hydratation JavaScript
- Testez vos pages avec l'outil d'inspection d'URL de la Search Console pour voir ce que Google indexe réellement
Quelles actions concrètes appliquer dès maintenant ?
Commencez par les pages stratégiques : homepage, catégories principales, fiches produits best-sellers. Si l'une d'elles approche ou dépasse 1 Mo, c'est une urgence — pas une optimisation de confort.
Externalisez tout ce qui peut l'être. Les schémas JSON-LD volumineux ? Dans un fichier séparé ou minifiés. Les styles critiques ? Inline minimal, le reste en CSS externe. Les données produit pour les filtres ? En lazy loading via API, pas en dump JSON de 800 Ko dans le DOM initial.
Faut-il repenser l'architecture technique de certains sites ?
Si vous gérez un site e-commerce avec des milliers de références affichées sur une page catalogue, oui. Les architectures qui chargent 500 produits d'un coup pour permettre le filtrage côté client sont mortes — ou du moins incompatibles avec une indexation optimale.
Privilégiez le server-side rendering avec pagination classique ou infinite scroll géré côté serveur. Chaque URL doit renvoyer un HTML autonome, léger, avec seulement le contenu visible immédiatement.
❓ Questions frequentes
Que se passe-t-il exactement si ma page dépasse 2 Mo ?
Cette limite s'applique-t-elle aussi aux fichiers CSS et JavaScript externes ?
Les PDFs sont-ils concernés par la même limite de 2 Mo ?
Comment savoir si Google tronque mes pages en pratique ?
Cette limite concerne-t-elle uniquement Googlebot ou aussi l'indexation mobile-first ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.