Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
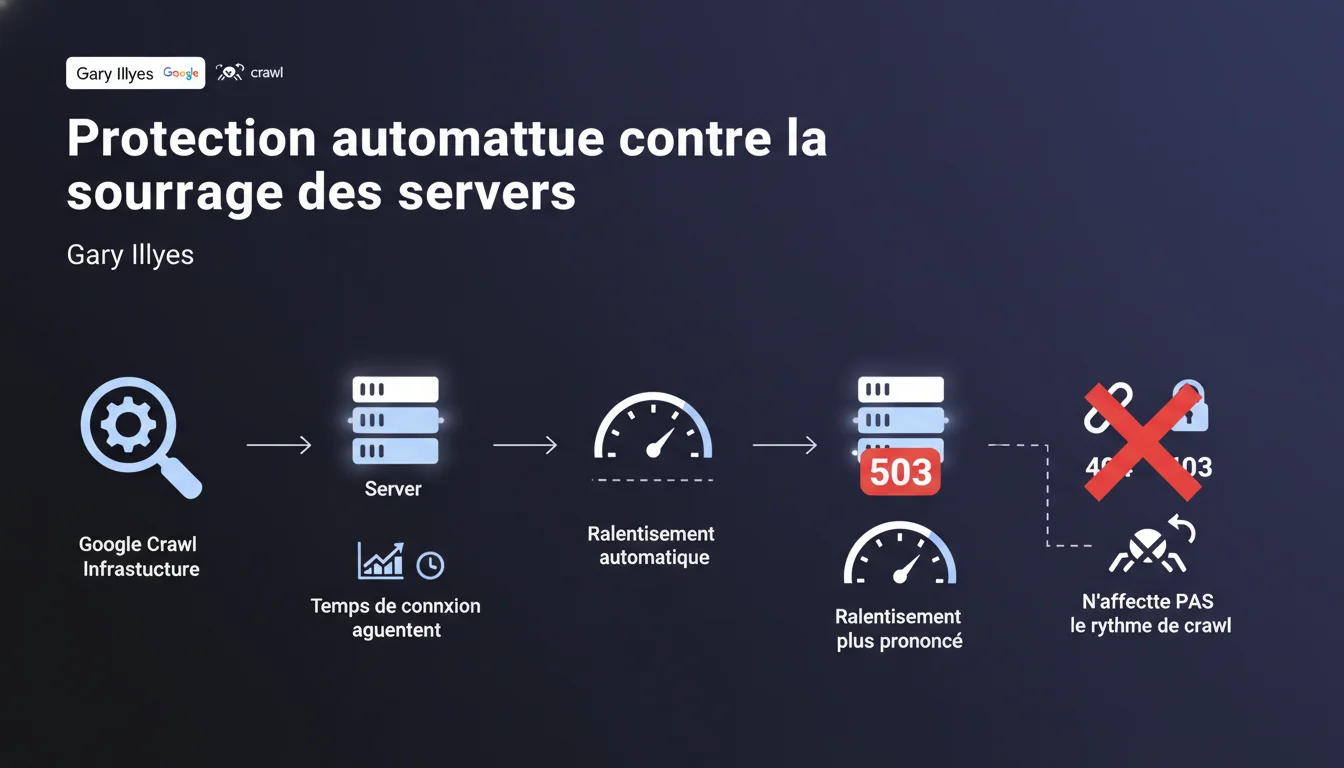
L'infrastructure de crawl Google ralentit automatiquement si les temps de connexion s'allongent de manière répétée. En cas de code HTTP 503 (serveur surchargé), le ralentissement est encore plus marqué. Les erreurs 403 et 404 n'influencent pas le rythme de crawl.
Ce qu'il faut comprendre
Comment Google détecte-t-il une surcharge serveur ?
Google ne se contente pas d'envoyer ses bots sans contrôle. L'infrastructure de crawl analyse en continu les temps de réponse de votre serveur. Si les temps de connexion augmentent de manière répétée, c'est un signal que le serveur peine à traiter les requêtes.
Le code HTTP 503 joue un rôle spécifique. Contrairement aux erreurs 403 ou 404 qui indiquent un problème d'accès ou de contenu, le 503 signale explicitement une indisponibilité temporaire due à une surcharge. Google interprète ce code comme une demande implicite de ralentir.
Pourquoi les erreurs 403 et 404 ne ralentissent-elles pas le crawl ?
Ces codes HTTP ne traduisent pas une difficulté technique du serveur à répondre. Une erreur 403 signifie un refus d'accès volontaire, une 404 indique simplement qu'une ressource n'existe pas. Dans les deux cas, le serveur répond rapidement et sans stress.
Google ne pénalise donc pas le crawl budget pour ces erreurs courantes. Le bot continue son exploration au même rythme, car aucune contrainte technique ne justifie un ralentissement.
Quels sont les déclencheurs précis du ralentissement automatique ?
Deux critères principaux : la répétition des temps de connexion élevés et la présence de réponses HTTP 503. Un temps de connexion ponctuel ne suffit pas — il faut une tendance détectable sur plusieurs requêtes.
Le ralentissement s'intensifie si le serveur renvoie des 503. Google comprend alors que la situation est critique et réduit drastiquement la fréquence des requêtes pour éviter d'aggraver la surcharge.
- Le crawl ralentit automatiquement si les temps de connexion augmentent de façon répétée
- Les réponses HTTP 503 déclenchent un ralentissement encore plus marqué
- Les erreurs 403 et 404 n'affectent pas le rythme de crawl
- Google protège ainsi votre serveur contre une surcharge induite par ses bots
Avis d'un expert SEO
Cette protection est-elle vraiment fiable en pratique ?
Oui, dans une large mesure. Les observations terrain montrent que Googlebot adapte effectivement son rythme face à des temps de réponse dégradés. Mais la réactivité du système n'est pas instantanée — il faut parfois plusieurs heures avant qu'un ralentissement notable se manifeste.
Le problème : Gary Illyes ne précise ni les seuils déclencheurs ni les délais de réaction. [A vérifier] Quelle augmentation de latence provoque le ralentissement ? Combien de temps avant que le crawl s'ajuste ? Ces zones floues compliquent l'optimisation proactive.
Le code 503 est-il toujours la meilleure réponse en cas de surcharge ?
En théorie oui, en pratique c'est plus nuancé. Renvoyer un 503 signale à Google de lever le pied, mais cela peut aussi retarder l'indexation de contenus importants. Si votre serveur est régulièrement au bord de la surcharge, mieux vaut dimensionner l'infrastructure plutôt que compter sur le 503 comme solution pérenne.
Certains hébergements ou CDN gèrent mal le 503 et le transforment en timeout, ce qui empire la situation. Testez votre configuration avant de compter sur cette mécanique de protection.
Faut-il ignorer les 403/404 dans le monitoring du crawl ?
Non. Même si ces codes n'influencent pas le rythme de crawl, ils impactent l'indexation et l'expérience utilisateur. Une hausse soudaine de 404 peut signaler un problème de maillage interne ou de migration ratée.
Le fait que Google ne ralentisse pas le crawl face aux 403/404 ne veut pas dire qu'il les ignore. Ces erreurs restent visibles dans la Search Console et peuvent affecter le classement si elles concernent des pages stratégiques.
Impact pratique et recommandations
Que faut-il mettre en place pour éviter les ralentissements de crawl ?
Monitorer les temps de réponse serveur en continu est la base. Si vous détectez des latences qui s'allongent, identifiez la cause : requêtes lourdes, pics de trafic, ressources insuffisantes. N'attendez pas que Googlebot ralentisse de lui-même.
Configurez des alertes sur les codes 503 dans vos logs. Une hausse inhabituelle doit déclencher une investigation immédiate. Vérifiez aussi que votre serveur renvoie bien un 503 (et non un timeout) en cas de surcharge.
Comment optimiser la réactivité du serveur face au crawl ?
Priorisez les réponses aux bots sur les contenus statiques ou peu coûteux en ressources. Si votre CMS génère des pages à la volée, mettez en place un cache efficace pour éviter de surcharger la base de données à chaque requête de Googlebot.
Dimensionnez votre infrastructure en fonction du crawl budget constaté. Si Google crawle régulièrement 10 000 pages par jour, votre serveur doit encaisser ce volume sans broncher. Un serveur sous-dimensionné ralentit le crawl, donc l'indexation, donc le trafic.
Faut-il manipuler volontairement le code 503 pour gérer le crawl ?
Non, sauf situation exceptionnelle (migration, maintenance lourde). Utiliser le 503 comme outil de gestion quotidienne du crawl est contre-productif. Cela envoie un signal de faiblesse à Google et risque de réduire durablement votre crawl budget.
Préférez une approche via le fichier robots.txt (directives Crawl-delay sur certains bots non-Google) ou via les paramètres de fréquence de crawl dans la Search Console — même si Google a retiré le contrôle manuel, le système s'adapte aux capacités du serveur.
- Surveiller les temps de réponse serveur et configurer des alertes sur les augmentations répétées
- Vérifier que votre serveur renvoie bien un 503 (et non un timeout) en cas de surcharge
- Dimensionner l'infrastructure en fonction du crawl budget constaté dans les logs
- Implémenter un cache efficace pour réduire la charge sur les pages fréquemment crawlées
- Ne pas utiliser le 503 comme outil de gestion quotidienne du crawl
- Analyser les logs pour identifier les patterns de crawl et ajuster les ressources en conséquence
❓ Questions frequentes
Un serveur lent ralentit-il automatiquement le crawl Google ?
Faut-il renvoyer un code 503 si mon serveur est temporairement surchargé ?
Les erreurs 404 réduisent-elles le crawl budget ?
Comment savoir si Google a ralenti le crawl de mon site ?
Peut-on forcer Google à augmenter le crawl malgré un serveur lent ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.