Declaration officielle
Autres déclarations de cette vidéo 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
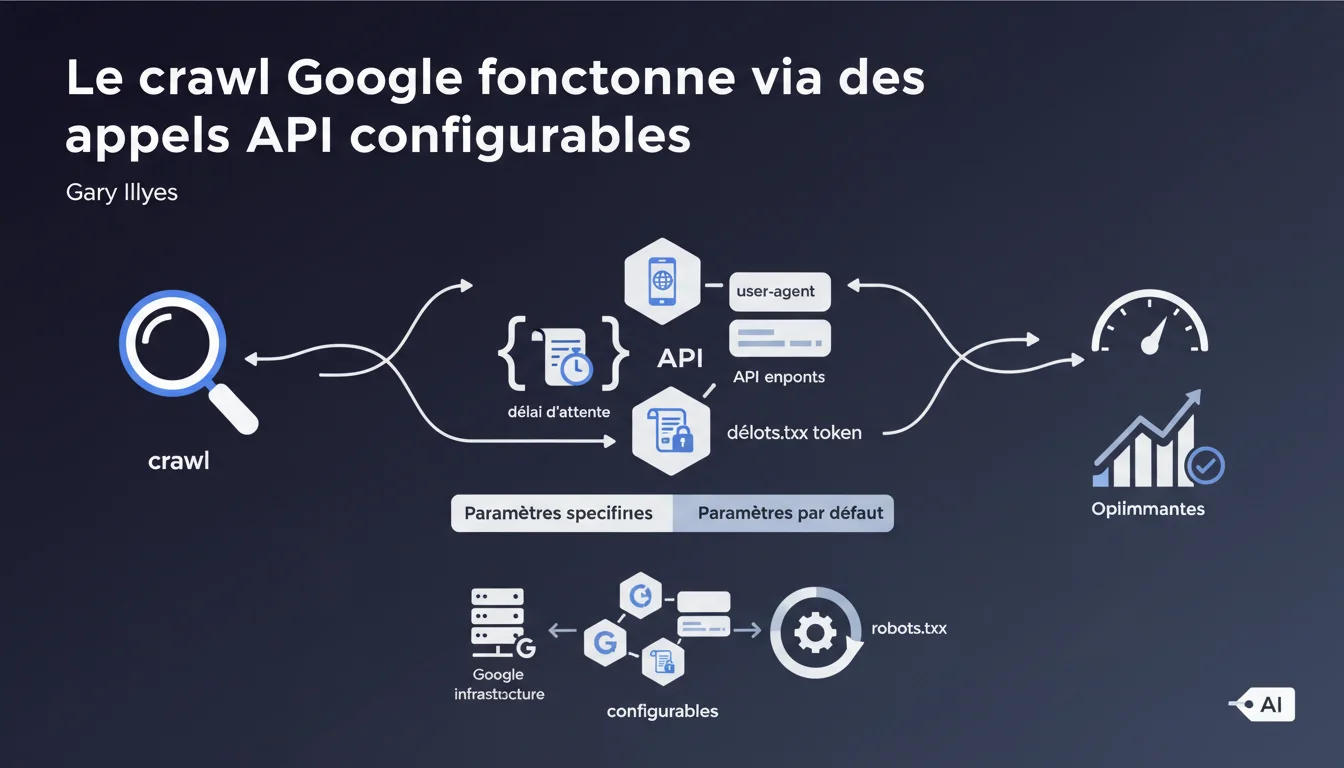
Gary Illyes révèle que l'infrastructure de crawl de Google repose sur des endpoints API où les équipes internes configurent des paramètres techniques précis : user-agent, délai d'attente, respect du robots.txt. Cette architecture modulaire explique pourquoi différents bots Google peuvent adopter des comportements distincts selon les paramètres définis en amont.
Ce qu'il faut comprendre
Qu'est-ce que cette architecture par API change pour nous ?
Cette déclaration lève le voile sur une mécanique interne rarement documentée. Le crawl Google n'est pas un processus monolithique, mais une infrastructure modulaire où chaque équipe produit peut appeler des endpoints avec ses propres paramètres.
Concrètement : quand vous voyez GoogleBot, GoogleBot-Image ou GoogleBot-News dans vos logs, ce ne sont pas des entités autonomes. Ce sont des configurations différentes d'un même système d'appels API, avec des user-agents, des timeouts et des règles robots.txt spécifiques.
Pourquoi Google utilise-t-il des tokens robots.txt distincts ?
Le terme "token robots.txt" mérite qu'on s'y arrête. Chaque bot peut être configuré pour respecter une directive robots.txt particulière. Vous bloquez GoogleBot mais autorisez GoogleBot-Image ? L'API gère ça via des paramètres distincts.
Cette granularité explique pourquoi certains sites voient des comportements incohérents entre bots — ce ne sont littéralement pas les mêmes configurations d'appel. Les équipes internes de Google définissent leurs besoins, l'infrastructure s'adapte.
Quels sont les paramètres par défaut mentionnés ?
Illyes évoque des "paramètres par défaut" sans les détailler. On peut supposer qu'il s'agit de configurations standard pour les cas d'usage courants : timeout standard, politesse moyenne, respect du robots.txt général.
Mais voilà le hic : on ne sait pas quels sont ces defaults. Ni leur hiérarchie. Ni comment ils s'appliquent quand une équipe ne spécifie pas explicitement un paramètre. C'est frustrant pour quiconque cherche à optimiser son crawl budget.
- Le crawl Google repose sur une infrastructure API modulaire où chaque équipe configure ses paramètres
- Les différents GoogleBots sont des configurations d'appel distinctes, pas des entités séparées
- Chaque bot peut avoir son propre token robots.txt, son timeout, son user-agent
- Des paramètres par défaut existent mais ne sont pas documentés publiquement
- Cette architecture explique les variations de comportement observées entre différents bots Google
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Oui, et ça résout plusieurs mystères. Les SEOs observent depuis des années que GoogleBot-Mobile et GoogleBot-Desktop ne crawlent pas de la même façon — mêmes patterns temporels différents, mêmes fréquences distinctes. Avec une architecture API, chaque équipe (mobile, desktop, actualités) appelle avec ses propres paramètres.
Ça explique aussi pourquoi bloquer un bot dans le robots.txt n'empêche pas toujours un autre bot Google de passer. Ce ne sont pas des siblings qui partagent tout — ce sont des configurations indépendantes qui consomment la même infrastructure.
Quelles informations cruciales manquent encore ?
Soyons honnêtes : cette révélation soulève plus de questions qu'elle n'apporte de réponses actionnables. Quels sont les paramètres disponibles dans ces appels API ? Quelle est la hiérarchie des defaults ? [À vérifier]
On aimerait savoir si le crawl budget est un paramètre configurable par équipe, ou s'il reste géré centralement. Si les timeouts sont ajustables par type de ressource. Si certaines équipes ont des quotas prioritaires. Rien de tout ça n'est précisé.
Peut-on exploiter cette information pour optimiser son crawl ?
Pas directement. Vous ne pouvez pas appeler ces APIs vous-même ni influencer les paramètres que Google configure en interne. Mais cette connaissance affine votre stratégie défensive : si vous voulez bloquer un bot spécifique, vérifiez son token robots.txt exact.
En revanche, cette déclaration confirme qu'optimiser pour "GoogleBot" en général n'a pas beaucoup de sens. Il faut segmenter votre analyse par user-agent et adapter vos règles en conséquence — certains bots méritent plus d'attention que d'autres selon votre activité.
Impact pratique et recommandations
Que faut-il faire concrètement avec cette information ?
D'abord, segmentez vos logs serveur par user-agent Google. Ne regroupez plus tous les GoogleBots dans une seule métrique. Analysez séparément GoogleBot-Desktop, GoogleBot-Mobile, GoogleBot-Image, GoogleBot-News, etc.
Ensuite, vérifiez que vos directives robots.txt ciblent bien les bons tokens. Si vous voulez bloquer l'exploration d'images mais autoriser le contenu textuel, assurez-vous de distinguer GoogleBot-Image dans vos règles.
- Installer un outil de monitoring des logs qui distingue chaque user-agent Google
- Créer des tableaux de bord séparés pour analyser le comportement de chaque bot
- Auditer votre robots.txt pour vérifier que chaque directive cible le bon token
- Mesurer les timeouts et patterns de crawl par user-agent, pas globalement
- Documenter les différences de comportement entre bots pour ajuster votre stratégie
- Tester l'impact d'un blocage robots.txt sur chaque bot individuellement
Quelles erreurs éviter absolument ?
Ne généralisez pas. Un comportement observé sur GoogleBot-Mobile ne s'appliquera pas forcément à GoogleBot-Desktop. Chacun a potentiellement ses propres paramètres de timeout, de politesse, de priorité.
Évitez aussi de bloquer trop largement dans votre robots.txt. Si vous bloquez "Googlebot" sans préciser, vous risquez de toucher tous les bots — alors que vous vouliez peut-être juste en cibler un. Soyez chirurgical dans vos directives.
Comment vérifier que votre configuration est optimale ?
Comparez vos métriques de crawl par user-agent avec vos objectifs business. Si GoogleBot-News passe 80% de son temps sur des archives sans valeur actualité, vous avez un problème de priorisation — guidez-le avec votre maillage interne et vos sitemaps.
Surveillez aussi les codes HTTP par bot. Certains peuvent avoir des timeouts plus courts et rencontrer plus de 5xx. Si vous constatez qu'un bot spécifique génère beaucoup d'erreurs serveur, ça peut signaler un décalage entre ses paramètres et votre infrastructure.
❓ Questions frequentes
Peut-on configurer nous-mêmes les paramètres de crawl Google via ces APIs ?
Si je bloque Googlebot dans mon robots.txt, est-ce que tous les bots Google sont bloqués ?
Les paramètres par défaut dont parle Illyes sont-ils documentés quelque part ?
Cette architecture explique-t-elle pourquoi certains bots Google crawlent plus vite que d'autres ?
Dois-je créer des sitemaps séparés pour chaque bot Google ?
🎥 De la même vidéo 11
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/03/2026
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.