Official statement
Other statements from this video 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
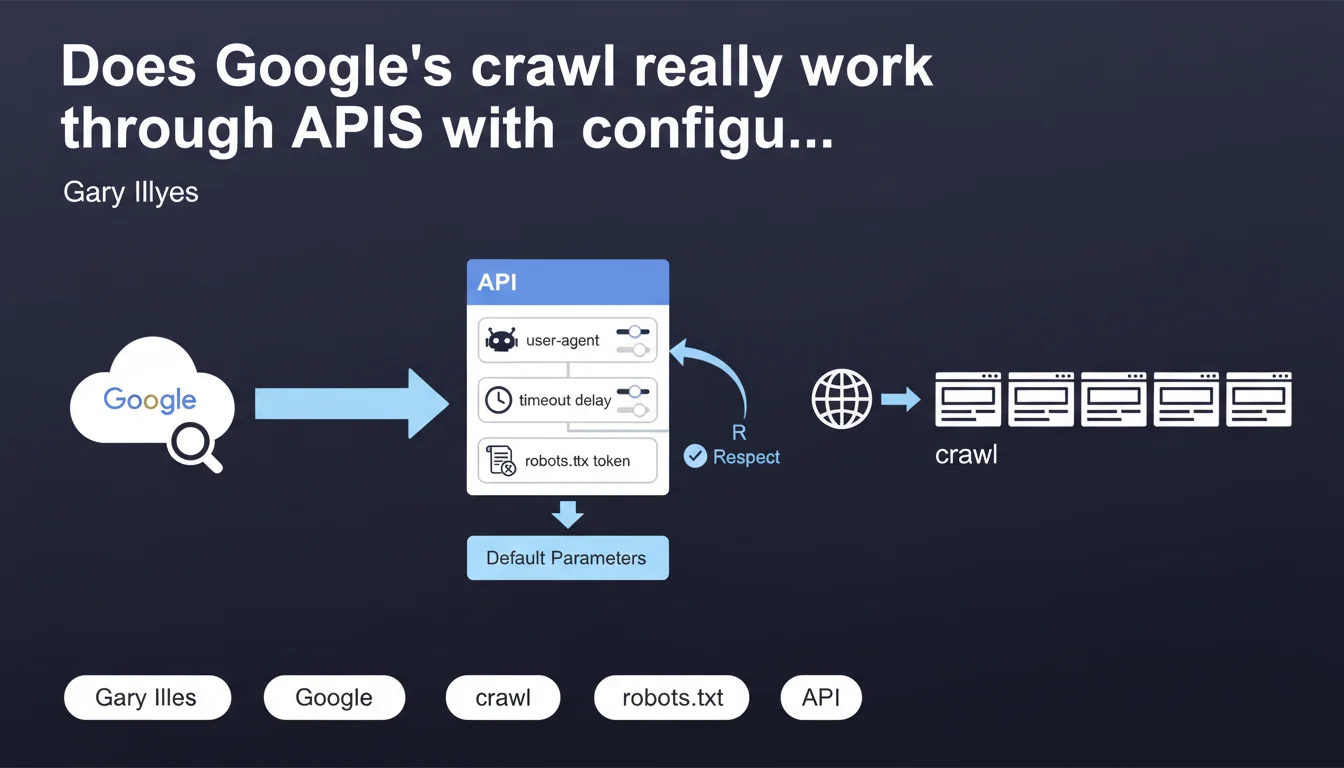
Gary Illyes reveals that Google's crawl infrastructure relies on API endpoints where internal teams configure precise technical parameters: user-agent, timeout delay, robots.txt compliance. This modular architecture explains why different Google bots can adopt distinct behaviors depending on the parameters defined upstream.
What you need to understand
How does this API-based architecture change things for us?
This statement unveils an internal mechanic rarely documented. Google crawl isn't a monolithic process, but a modular infrastructure where each product team can call endpoints with its own parameters.
Concretely: when you see GoogleBot, GoogleBot-Image or GoogleBot-News in your logs, these aren't autonomous entities. They're different configurations of the same API call system, with specific user-agents, timeouts and robots.txt rules.
Why does Google use distinct robots.txt tokens?
The term "robots.txt token" deserves closer examination. Each bot can be configured to respect a particular robots.txt directive. You block GoogleBot but allow GoogleBot-Image? The API handles that through separate parameters.
This granularity explains why some sites see inconsistent behavior between bots — they literally aren't the same call configurations. Google's internal teams define their needs, the infrastructure adapts.
What are the default parameters mentioned?
Illyes mentions "default parameters" without detailing them. We can assume these are standard configurations for common use cases: standard timeout, average politeness, general robots.txt compliance.
But here's the catch: we don't know what these defaults are. Or their hierarchy. Or how they apply when a team doesn't explicitly specify a parameter. It's frustrating for anyone trying to optimize their crawl budget.
- Google crawl relies on a modular API infrastructure where each team configures its parameters
- Different GoogleBots are distinct call configurations, not separate entities
- Each bot can have its own robots.txt token, timeout, user-agent
- Default parameters exist but are not publicly documented
- This architecture explains the behavioral variations observed between different Google bots
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes, and it solves several mysteries. SEOs have observed for years that GoogleBot-Mobile and GoogleBot-Desktop don't crawl the same way — same different temporal patterns, same distinct frequencies. With an API architecture, each team (mobile, desktop, news) calls with its own parameters.
It also explains why blocking a bot in robots.txt doesn't always prevent another Google bot from passing. They're not siblings sharing everything — they're independent configurations consuming the same infrastructure.
What crucial information is still missing?
Let's be honest: this revelation raises more questions than it provides actionable answers. What parameters are available in these API calls? What's the hierarchy of defaults? [To verify]
We'd like to know if crawl budget is a parameter configurable by team, or if it remains centrally managed. If timeouts are adjustable by resource type. If certain teams have priority quotas. None of this is specified.
Can we exploit this information to optimize crawl?
Not directly. You can't call these APIs yourself or influence the parameters Google configures internally. But this knowledge refines your defensive strategy: if you want to block a specific bot, verify its exact robots.txt token.
However, this statement confirms that optimizing for "GoogleBot" in general doesn't make much sense. You need to segment your analysis by user-agent and adapt your rules accordingly — some bots deserve more attention than others depending on your activity.
Practical impact and recommendations
What should you concretely do with this information?
First, segment your server logs by Google user-agent. Stop grouping all GoogleBots into a single metric. Analyze separately GoogleBot-Desktop, GoogleBot-Mobile, GoogleBot-Image, GoogleBot-News, etc.
Next, verify that your robots.txt directives target the right tokens. If you want to block image crawling but allow text content, make sure you distinguish GoogleBot-Image in your rules.
- Install a log monitoring tool that distinguishes each Google user-agent
- Create separate dashboards to analyze the behavior of each bot
- Audit your robots.txt to verify that each directive targets the right token
- Measure timeouts and crawl patterns by user-agent, not globally
- Document the differences in behavior between bots to adjust your strategy
- Test the impact of a robots.txt block on each bot individually
What mistakes should you absolutely avoid?
Don't generalize. A behavior observed on GoogleBot-Mobile won't necessarily apply to GoogleBot-Desktop. Each potentially has its own timeout, politeness, priority parameters.
Also avoid blocking too broadly in your robots.txt. If you block "Googlebot" without specifying, you risk affecting all bots — when you maybe only wanted to target one. Be surgical in your directives.
How can you verify your configuration is optimal?
Compare your crawl metrics by user-agent against your business objectives. If GoogleBot-News spends 80% of its time on archives with no news value, you have a prioritization problem — guide it with your internal linking and sitemaps.
Also monitor HTTP status codes by bot. Some may have shorter timeouts and encounter more 5xx errors. If you notice a specific bot generating many server errors, it could signal a mismatch between its parameters and your infrastructure.
❓ Frequently Asked Questions
Peut-on configurer nous-mêmes les paramètres de crawl Google via ces APIs ?
Si je bloque Googlebot dans mon robots.txt, est-ce que tous les bots Google sont bloqués ?
Les paramètres par défaut dont parle Illyes sont-ils documentés quelque part ?
Cette architecture explique-t-elle pourquoi certains bots Google crawlent plus vite que d'autres ?
Dois-je créer des sitemaps séparés pour chaque bot Google ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 12/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.