Official statement
Other statements from this video 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
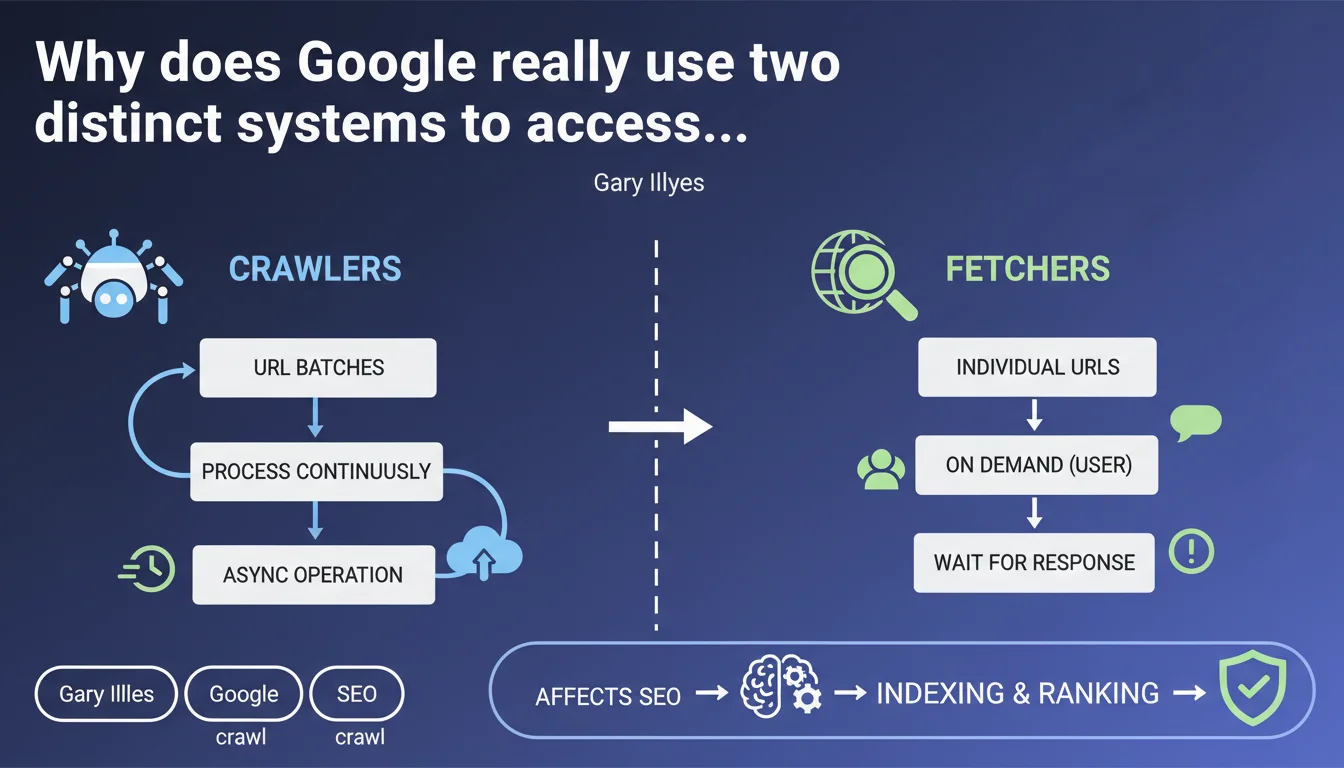
Google clearly distinguishes between its crawlers (asynchronous batch processing) and its fetchers (synchronous individual requests triggered by a user). This technical distinction directly impacts how your pages are explored, indexed, and displayed in webmaster tools. Understanding this difference allows you to correctly interpret server logs and optimize resources allocated to crawling.
What you need to understand
This statement from Gary Illyes lifts the veil on a fundamental technical architecture of Google that many SEO professionals still confuse. Crawlers (classic Googlebot) and fetchers (testing tools, URL Inspection Tool) have neither the same objectives nor the same operational constraints.
What is the concrete difference between a crawler and a fetcher?
A crawler processes URLs in batches, asynchronously. It doesn't wait for a human to view the result—it continuously browses the web according to its own priorities and pace. Googlebot indexing works this way: it visits your site, collects data, and processes it later in the indexing pipeline.
A fetcher responds to an individual request, typically triggered by a user via a tool (Search Console, Mobile-Friendly Test, Rich Results Test). It loads the requested URL, executes rendering if necessary, and returns the result immediately. The fetcher is therefore synchronous: someone waits for the response.
Why is this distinction important for SEO?
Because it explains seemingly inconsistent behaviors you observe in your logs or Search Console. A fetcher may load a critical CSS resource perfectly while the crawler sees it blocked by robots.txt or a server timeout.
Fetchers often have stricter quotas and slightly different behaviors regarding JavaScript rendering, redirect handling, or HTTP header compliance. If you test a URL in the inspection tool and everything looks perfect, that doesn't guarantee the indexing crawler will see exactly the same thing.
What are the typical use cases for each system?
Crawlers: systematic web exploration, discovery of new URLs, tracking content updates, collection of ranking signals. They operate in "fire and forget" mode—they don't wait for immediate feedback.
Fetchers: one-time URL validation, mobile compatibility testing, structured data extraction for display in webmaster tools, on-demand inspection. They operate in "request-response" mode with a short timeout.
- Crawlers process millions of URLs daily in an automated and prioritized manner.
- Fetchers respond to individual user requests with real-time constraints.
- A fetcher can fail while the crawler succeeds, and vice versa—particularly in cases of variable server load.
- Server logs often show both types of bots with slightly different user-agents or distinct request patterns.
- This distinction directly impacts crawl budget allocation: fetchers generally don't consume it.
SEO Expert opinion
Is this distinction truly new or just a clarification?
Let's be honest: this separation has existed in Google's infrastructure for years. What's changing is that Google is explicitly verbalizing it. Before, we deduced this difference by analyzing logs and inconsistent behaviors between the URL Inspection Tool and actual indexing.
Gary Illyes formalizes here what technical SEO professionals have observed for a long time. The problem? Many practitioners still use the inspection tool as an oracle of absolute truth for indexing, when it actually relies on a fetcher—not the crawler that really indexes your pages.
In which cases does this distinction cause problems in practice?
The classic scenario: your server is under load. The fetcher arrives, requests a URL, receives a fast response because it's an isolated request. You validate in Search Console, everything is green. Two hours later, the crawler arrives with 50 simultaneous requests, your server saturates, timeouts skyrocket.
Result: partial indexing, blocked resources, incomplete JavaScript rendering. But the inspection tool tells you everything is fine. [To verify]: Google has never specified whether fetchers follow the exact same rate limiting rules as crawlers—my field observations suggest they don't.
Another problematic case: temporary redirects. A fetcher may interpret a 302 differently from a batch crawler seeing the same 302 repeated over multiple visits. The fetcher tests punctually, the crawler aggregates signals over time.
Should you adapt your testing and monitoring strategies?
Absolutely. If you rely solely on Google testing tools (which use fetchers), you miss problems that only server logs reveal. A fetcher will never tell you that your server struggles to handle the allocated crawl budget.
Concretely: test with Google tools, but validate with your logs. Analyze the actual behavior of Googlebot crawler, its request patterns, its 5xx errors, its timeouts. That's where you'll see if your infrastructure handles intensive crawling.
Practical impact and recommendations
How to identify in your logs whether a request comes from a crawler or a fetcher?
Analyze the user-agents: Google sometimes uses subtle variants (GoogleOther for certain fetchers, standard Googlebot for crawlers). But the most reliable signal remains the request pattern.
A fetcher requests a single URL, waits for the response, disappears. A crawler arrives in bursts, traverses dozens of URLs within minutes, returns regularly. Fetchers generate isolated peaks, crawlers sustained waves.
What errors should you avoid when optimizing crawling?
Don't size your infrastructure based solely on testing with the URL Inspection Tool. This fetcher does not simulate the actual load that batch crawling imposes on your server. Test under realistic conditions: simulate intensive crawls, measure response times under load, verify your server doesn't saturate.
Another common mistake: blocking certain crawlers in robots.txt thinking you'll save crawl budget, then wondering why testing tools (fetchers) continue to work. Fetchers don't always follow the same rules—they may ignore certain directives to provide a result to the waiting user.
What specifically should you monitor to anticipate problems?
- Analyze your server logs to differentiate fetchers from crawlers based on request patterns.
- Measure average response times during crawl peaks, not just on isolated requests.
- Verify your server handles simultaneous requests correctly without timeouts or 5xx errors.
- Test JavaScript rendering under load—a fetcher may succeed in executing your JS, batch crawler may fail if the server is struggling.
- Compare URL Inspection Tool results with actually indexed URLs—any divergence signals a problem.
- Document the distinct user-agents you observe and their respective behaviors.
- Configure alerts for 5xx errors and timeouts during identified crawl peaks in your logs.
❓ Frequently Asked Questions
Les fetchers consomment-ils du crawl budget au même titre que les crawlers ?
Pourquoi l'URL Inspection Tool affiche parfois un résultat différent de l'indexation réelle ?
Un fetcher respecte-t-il le robots.txt de la même manière qu'un crawler ?
Comment savoir si mes problèmes d'indexation viennent du crawler ou du fetcher ?
Les fetchers exécutent-ils le JavaScript de la même manière que les crawlers ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 12/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.