Official statement
Other statements from this video 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
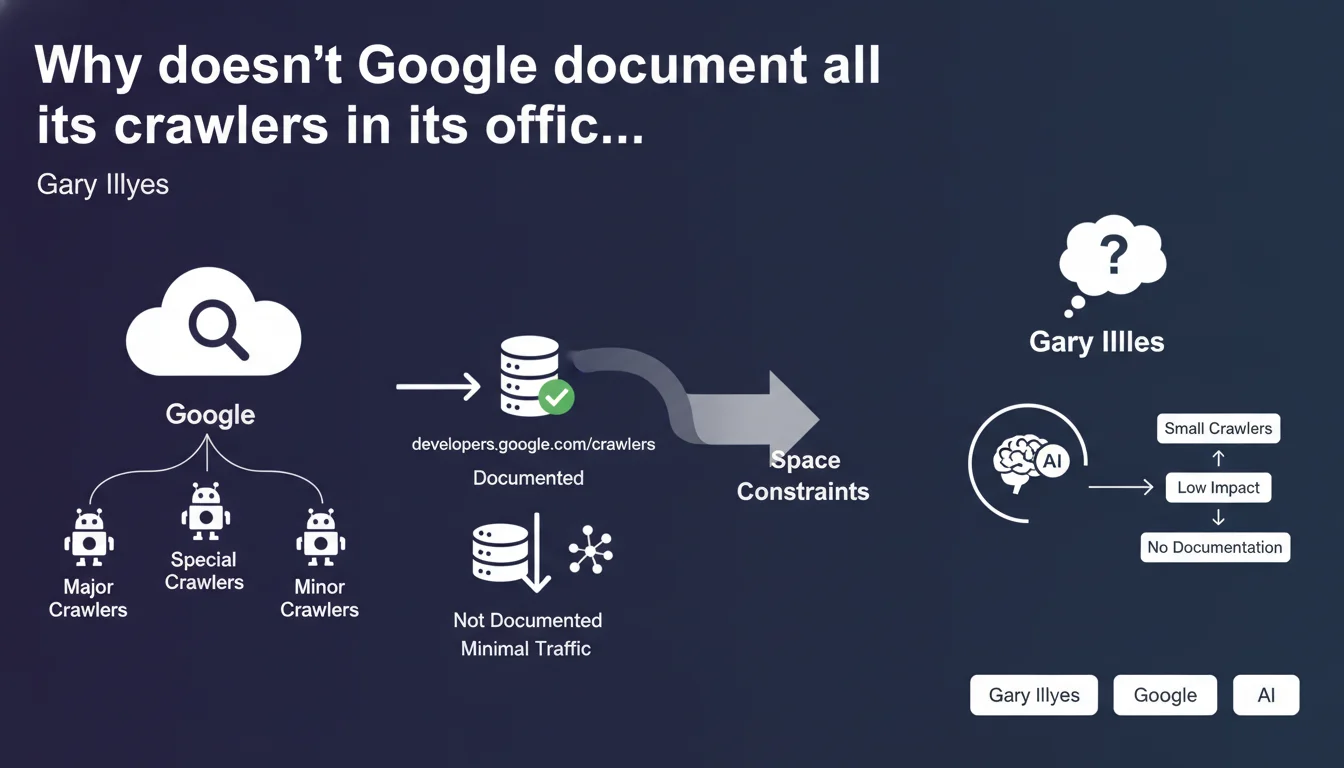
Google admits it doesn't document all of its crawlers on developers.google.com/crawlers. Only major and special crawlers appear in the official list, while smaller robots generating minimal traffic remain intentionally undocumented due to "space constraints." This revelation raises questions about Google's real transparency regarding crawl activity on our websites.
What you need to understand
What does this so-called "space constraint" really mean?
The argument advanced by Gary Illyes seems rather surprising, to say the least. A technical documentation page doesn't really have any physical space limitations — we're not printing a paper manual here.
What Google is admitting between the lines is that part of its crawl infrastructure remains intentionally hidden from view. Non-documented robots generate minimal traffic individually, but their cumulative effect can represent a non-negligible load on certain websites. The choice not to list them is more of an editorial decision than a technical impossibility.
Which crawlers does Google consider "major"?
The official documentation lists around twenty crawlers, including Googlebot (desktop and mobile), Google-Extended, GoogleOther, as well as specialized crawlers such as AdsBot and Google-InspectionTool.
These robots have clearly defined roles: web indexing, AMP validation, ad preview, security verification. However, this transparency covers only a fraction of the actual ecosystem. Internal crawlers dedicated to testing, experimentation, or secondary services don't appear anywhere.
What are the concrete implications for server log analysis?
If you analyze your logs rigorously, you've probably already spotted undocumented Google user-agents. Some don't match any official entry, others use generic patterns that are difficult to formally identify.
This opacity complicates crawl budget analysis and anomaly detection. How can you distinguish a legitimate crawler from a malicious bot impersonating a Google user-agent if the reference list is incomplete?
- Google intentionally documents only some of its crawlers
- The "space constraints" argument masks a deliberate editorial decision
- Non-documented crawlers generate minimal individual traffic but can have collective weight
- Log analysis becomes more complex without a comprehensive reference framework
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Absolutely. Any SEO analyst who regularly examines their server logs has already encountered mysterious Google user-agents. Some appear sporadically, others seem linked to experimental projects never announced publicly.
The issue is that Google validates these crawlers via reverse DNS — but without official documentation, it's impossible to know why a particular robot is crawling a specific section of your site. We're navigating blindly. This gray area makes management particularly complicated for high-volume websites or complex infrastructures. [To verify]: Google could at least document the generic patterns of these minor crawlers without necessarily detailing their exact function.
What risks does this opacity create for websites?
First risk: undetected crawl budget overconsumption. If you aggressively block unidentified bots, you risk cutting off a legitimate Google service. If you let everything through, you may waste server resources on low-value crawlers.
Second risk: confusion with malicious bots. Scrapers regularly impersonate Google user-agents. Without an exhaustive list, how can you validate the legitimacy of an unknown crawler? Reverse DNS verification works, but it requires technical expertise that not all webmasters possess.
Should we expect more transparency from Google?
Let's be realistic: Google has no strategic interest in exhaustively documenting all its internal crawlers. Some probably serve A/B testing, others machine learning, and others still are abandoned projects whose infrastructure continues to run.
The real question isn't "why doesn't Google document everything" but "how do we adapt to this reality." Log analysis must incorporate an element of uncertainty. Log analysis tools must maintain their own databases of observed user-agents, beyond the official documentation.
Practical impact and recommendations
How can you identify undocumented Google crawlers in your logs?
The standard method remains reverse DNS verification. Retrieve the crawler's IP address, perform a reverse DNS lookup, then verify that the resulting domain belongs to Google (googlebot.com or google.com). Finally, perform a forward lookup to confirm that the domain points back to the original IP.
This double verification eliminates identity spoofing. Legitimate crawlers, documented or not, will pass this test. Scrapers will fail.
Should you block undocumented Google crawlers?
Not systematically. If a crawler generates minimal traffic and causes no server load issues, leave it alone. Blocking a Google service whose function you don't know could have unpredictable side effects.
However, if you detect an undocumented crawler that massively consumes resources or crawls sensitive sections, you can manage it through robots.txt or specific server rules. Document each intervention so you can reverse it if necessary.
What robots.txt rules should you adopt in the face of this opacity?
Stick to generic and cautious directives. Block by content patterns rather than user-agent: admin sections, dev files, test pages. Avoid blacklisting specific Google user-agents unless you're absolutely certain of their role and absence of impact.
Maintain a whitelist of major crawlers that you want to see on your site. For everything else, adopt an active monitoring approach rather than preventive blocking.
- Implement regular server log analysis focused on Google user-agents
- Document all unofficial Google crawlers you discover along with their activity patterns
- Implement a reverse DNS verification procedure to validate unknown crawlers
- Avoid massive user-agent blocking — prioritize selective blocking by content type
- Monitor your overall crawl budget evolution rather than focusing on an isolated crawler
- Test any robots.txt changes in a staging environment before production deployment
❓ Frequently Asked Questions
Comment vérifier qu'un crawler inconnu appartient bien à Google ?
Est-ce risqué de bloquer un crawler Google non documenté ?
Où trouver la liste officielle des crawlers Google documentés ?
Les crawlers non documentés consomment-ils du crawl budget inutilement ?
Peut-on forcer Google à révéler tous ses crawlers ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 12/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.