Official statement
Other statements from this video 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
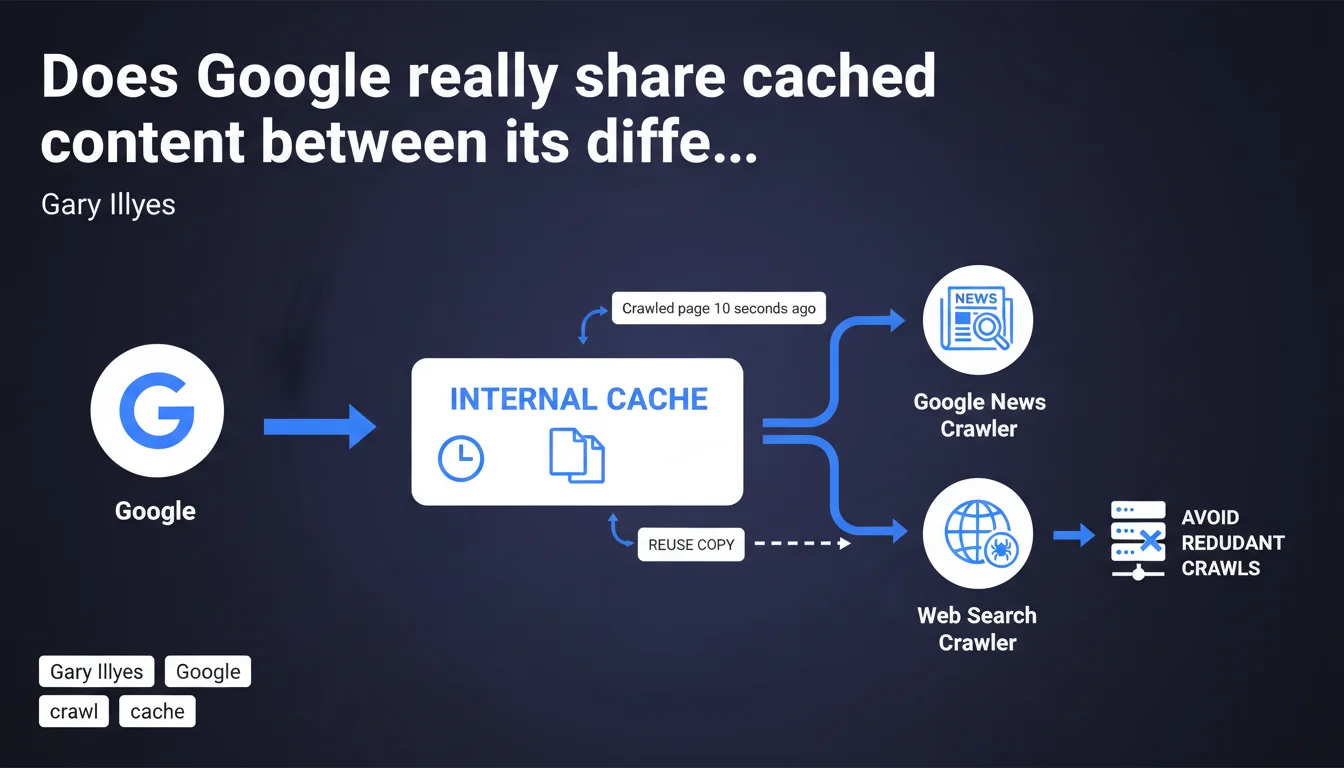
Google uses an aggressive internal cache that allows its different robots (Search, News, etc.) to share crawled versions of the same page. If Google News crawls your page, Googlebot Search can reuse that copy seconds later instead of making another HTTP request. This mechanism completely bypasses standard HTTP directives and directly impacts your crawl budget.
What you need to understand
How does this shared cache between crawlers work?
Google maintains a centralized internal cache that temporarily stores crawled versions of your pages. When Google News visits your article at 10:00 AM, that copy is cached. If Googlebot Search decides to crawl the same URL at 10:00:10, it retrieves the cached version directly instead of requesting your server again.
This system operates independently of standard HTTP headers (Cache-Control, ETag, Last-Modified). You cannot control this cache through your typical server configurations. Google alone decides the retention duration and reuse conditions.
Why did Google implement this mechanism?
The stated objective is to optimize overall crawl budget and reduce server load. By avoiding redundant crawls across services, Google saves resources and limits impact on your infrastructure.
But let's be honest: this system also serves Google's interests. Fewer HTTP requests = less bandwidth consumed by Googlebot, resulting in faster and cheaper crawling for them.
What is the retention period for this cache?
Gary Illyes mentions 10 seconds in his example, but no precise data is provided on the maximum duration. Is it 10 seconds, 1 minute, 5 minutes? Impossible to say officially.
This ambiguity is problematic. Without a clear temporal window, it's difficult to anticipate when your modifications will actually be recrawled by all relevant robots.
- Google shares crawled versions between its different bots (Search, News, Discover, etc.)
- This cache operates independently of standard HTTP mechanisms you control
- Retention duration remains unclear — at least several seconds, probably longer
- Stated objective: reduce redundant crawls and preserve your crawl budget
- Implication: a page can be indexed with a version crawled by another Google service
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, completely consistent. We regularly observe delays between when a page is modified and when all Google services reflect the change. For example, you update a title at 2 PM, Google News displays it at 2:02 PM, but Search Console still shows the old title 10 minutes later.
This shared cache also explains why certain pages appear in Google Discover with a snippet crawled by Googlebot-News, even if the "primary" indexed version differs slightly. Inconsistencies we attributed to synchronization bugs find here a structural explanation.
What are the limitations of this transparency?
Gary Illyes remains vague on critical details. What is the maximum duration of this cache? What criteria determine whether a page should be recrawled rather than reused? Do all Google robots participate in this cache, or only certain ones?
Another point: this statement doesn't specify how this mechanism interacts with urgent updates. If you fix a serious factual error, can you force cache invalidation? Nothing indicates that tools like URL inspection bypass this system. [To verify]
In which cases does this mechanism cause problems?
For news sites publishing breaking news or frequent updates, this cache can create embarrassing delays. You correct a misleading title, but Google continues serving the old version for several seconds — or even minutes — to some users across different entry points.
Same issue for e-commerce sites managing real-time inventory. If Google News crawls a product page "in stock," then Googlebot Search reuses that copy while the product is actually out of stock, users land on an inconsistent page.
Practical impact and recommendations
What should you do concretely to adapt?
First action: stop relying solely on HTTP headers to manage freshness of your critical content. Cache-Control and ETag remain useful for browsers and CDNs, but they no longer guarantee Google will immediately recrawl each bot.
For urgent content (breaking news, factual corrections), systematically use the URL inspection tool in Search Console and request reindexing. Even if Gary Illyes doesn't confirm it explicitly, it's your only potential lever to bypass this cache.
Adapt your publishing workflows. If you publish simultaneously across multiple channels (website, AMP, app), synchronize updates as closely as possible to avoid Google caching an intermediate version that's incoherent between services.
What mistakes should you absolutely avoid?
Never assume a modification will be instantly visible everywhere in the Google ecosystem. A title change visible in the Search SERP doesn't mean Google News, Discover, or the AMP version display the same version.
Avoid triggering massive simultaneous crawls across multiple channels (News sitemap + standard sitemap + IndexNow + manual inspection). You risk creating inconsistencies if different bots crawl at staggered times and the cache propagates an intermediate version.
How can you verify the impact on your site?
Monitor freshness gaps between different Google services. Regularly compare what Search Console, Google News, Discover, and classic search show for the same URL after a modification.
Analyze your server logs to identify crawl patterns. If you notice Googlebot-News systematically visits before Googlebot, then the latter doesn't immediately recrawl, you're probably observing this cache in action.
- Use URL inspection to force reindexing of critical content after modification
- Synchronize your multi-channel publications to avoid incoherent intermediate versions
- Monitor freshness gaps between Search, News, and Discover via Search Console
- Analyze your logs to spot shared crawl patterns between Google bots
- Never assume a change is instantly propagated everywhere
- Document observed delays between modification and display in each Google service
❓ Frequently Asked Questions
Puis-je désactiver ce cache partagé pour mon site ?
L'outil d'inspection d'URL contourne-t-il ce cache ?
Quelle est la durée maximale de rétention du cache ?
Tous les robots Google partagent-ils ce cache ?
Ce cache impacte-t-il le crawl budget de mon site ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 12/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.