Official statement
Other statements from this video 11 ▾
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
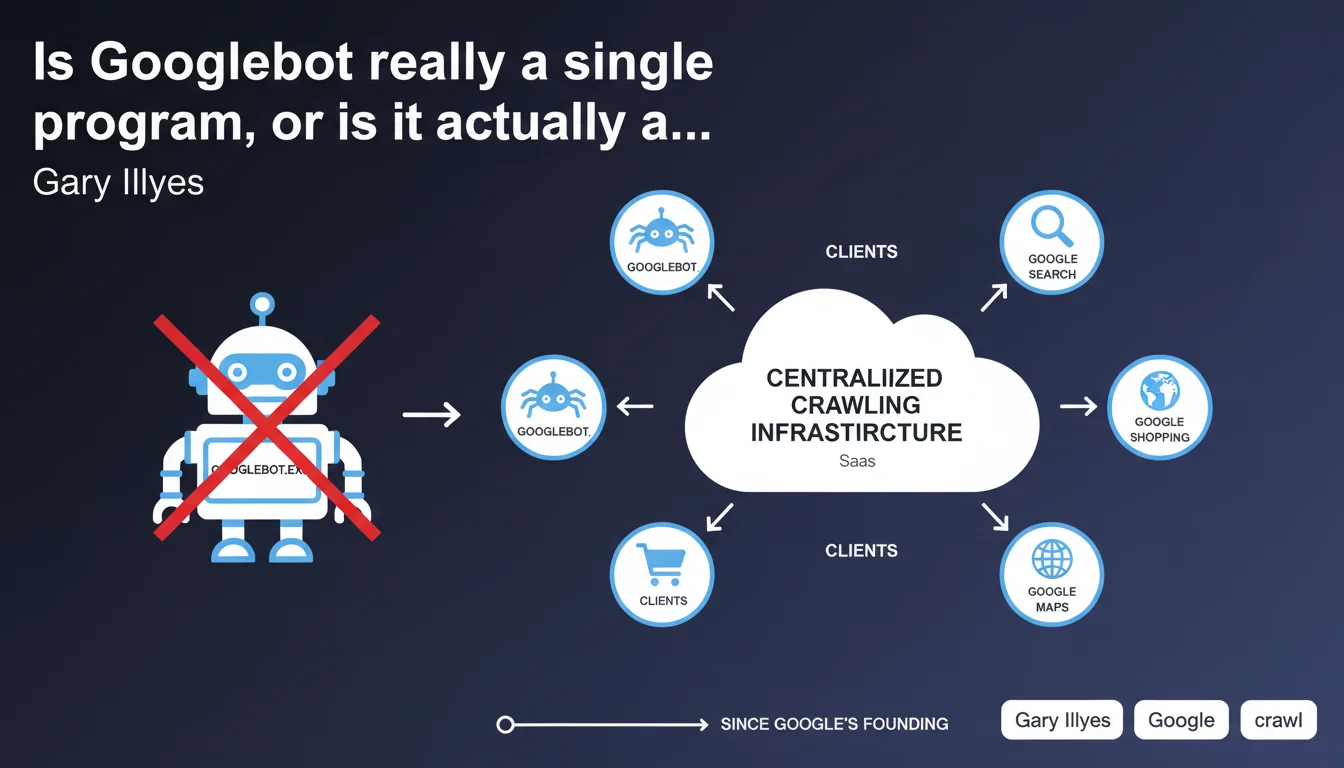
Googlebot is not a single executable file but rather one client among others of a centralized crawling infrastructure that Google has used since its inception. This infrastructure functions as an internal service (SaaS) shared by multiple Google products. This distinction is crucial for understanding why crawling behavior can vary depending on the context.
What you need to understand
Why does this technical distinction change how we understand crawling?
Gary Illyes reminds us that Googlebot is not autonomous software but rather an access point to a shared crawling platform. In practical terms, this means the same technical system is used to explore the web for Search, but also for other Google products (Google News, Google Images, AdsBot, etc.).
This architecture explains why user-agents vary while the infrastructure remains identical. The behavior observed depends on the context of use: a crawl for standard search won't have exactly the same priorities as a crawl for Google News.
What does this mean for managing crawl budget?
If Googlebot is a client of a centralized infrastructure, then the crawl prioritization rules are probably common to all products that use it. Authority signals, freshness, and popularity influence all types of crawls.
However, each product can add its own filters and weightings. A news site will be crawled more frequently by News-oriented bots, even though the underlying infrastructure is shared.
How does this architecture impact User-Agent detection?
The classic mistake is to block or allow a single User-Agent thinking you're controlling Googlebot as a whole. But since the infrastructure is shared, different clients can present themselves with slightly different signatures.
Google recommends verifying the reverse IP lookup rather than relying solely on the User-Agent string. This approach is more reliable when dealing with a distributed infrastructure.
- Googlebot is not an autonomous program but a client of a centralized crawling infrastructure.
- This infrastructure has existed since Google's founding and serves multiple products simultaneously.
- The variations in observed behavior come from specific configurations of each product using the service.
- Verification via reverse DNS lookup remains the most reliable method for authenticating a Google bot.
- Crawl prioritization rules are likely common to all clients of this infrastructure.
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes, absolutely. SEO professionals have long known that Googlebot behaves differently depending on context. An e-commerce site will see distinct crawl patterns between the main bot, the mobile bot, and the bot exploring product images.
This official confirmation validates what we knew empirically: there isn't one Googlebot but multiple Googlebots, even though technically they share the same infrastructure. To be honest, this distinction may seem anecdotal but it has practical implications for how we optimize crawling.
What nuances should we add to this statement?
Gary Illyes tells us this infrastructure has existed "since Google's founding". [To verify] — it's likely the architecture has evolved considerably since 1998. Speaking of identical infrastructure over 25+ years is a marketing oversimplification.
The real question remains that of specific algorithmic priorities for each client. Google doesn't tell us how these priorities are defined or how they interact. A site can be crawled intensively by one bot and ignored by another — and this statement provides no key for controlling that.
What risks does this architecture present for webmasters?
The main pitfall: believing that a single optimization will satisfy all Google bots. If you optimize your crawl budget for standard Search, you're not automatically managing the crawl for Google News or Google Discover.
Another point: server logs sometimes show massive crawls attributed to Googlebot with no visible impact on indexing. If the infrastructure is shared, some crawls may serve other Google products — which explains why your sitemap is explored without your pages gaining visibility.
Practical impact and recommendations
What should you do concretely with this information?
First, adjust your bot detection strategy. If you're using robots.txt rules or server configurations based solely on User-Agent, supplement them with IP verification via reverse DNS lookup. This is the method recommended by Google and becomes essential when dealing with a distributed infrastructure.
Next, analyze your server logs by segmenting different Google User-Agents. Don't just look at "Googlebot" as a whole, but distinguish between Googlebot Desktop, Googlebot Mobile, Googlebot Image, AdsBot, etc. Each has its own patterns and needs.
What mistakes should you absolutely avoid?
Don't block a User-Agent without measuring overall impact. If you block GoogleBot-News because you don't target Google News, verify that it doesn't affect your general crawl — since the infrastructure is shared, the effects can be counterintuitive.
Also avoid over-optimizing for a single type of crawl. A site that exclusively optimizes for mobile can penalize its desktop crawl, even though both go through the same technical infrastructure.
How do you verify that your site is configured correctly?
Implement server log monitoring that clearly distinguishes different Google bots. Regularly verify that each type of content (HTML pages, images, CSS/JS) is properly crawled by the appropriate bot.
Use Search Console to cross-reference this data: if you see significant gaps between reported crawls and your log analysis, it's likely that some crawls are serving other Google products.
- Implement verification via reverse DNS lookup in addition to User-Agent
- Segment server log analysis by type of Google User-Agent
- Monitor gaps between observed crawl and actual indexing
- Test the impact of any robots.txt rule on all Google bots
- Optimize internal linking to facilitate all types of crawls, not just standard Search
- Verify that critical resources (CSS, JS, images) are accessible to all bots
❓ Frequently Asked Questions
Googlebot est-il donc plusieurs programmes différents ?
Comment vérifier qu'un crawl provient réellement de Google ?
Pourquoi certains crawls Googlebot n'aboutissent-ils pas à une indexation ?
Bloquer un User-Agent Google spécifique peut-il affecter les autres ?
Cette architecture explique-t-elle les variations de crawl budget observées ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 12/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.