Official statement
Other statements from this video 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Googlebot crawle-t-il principalement depuis les États-Unis ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
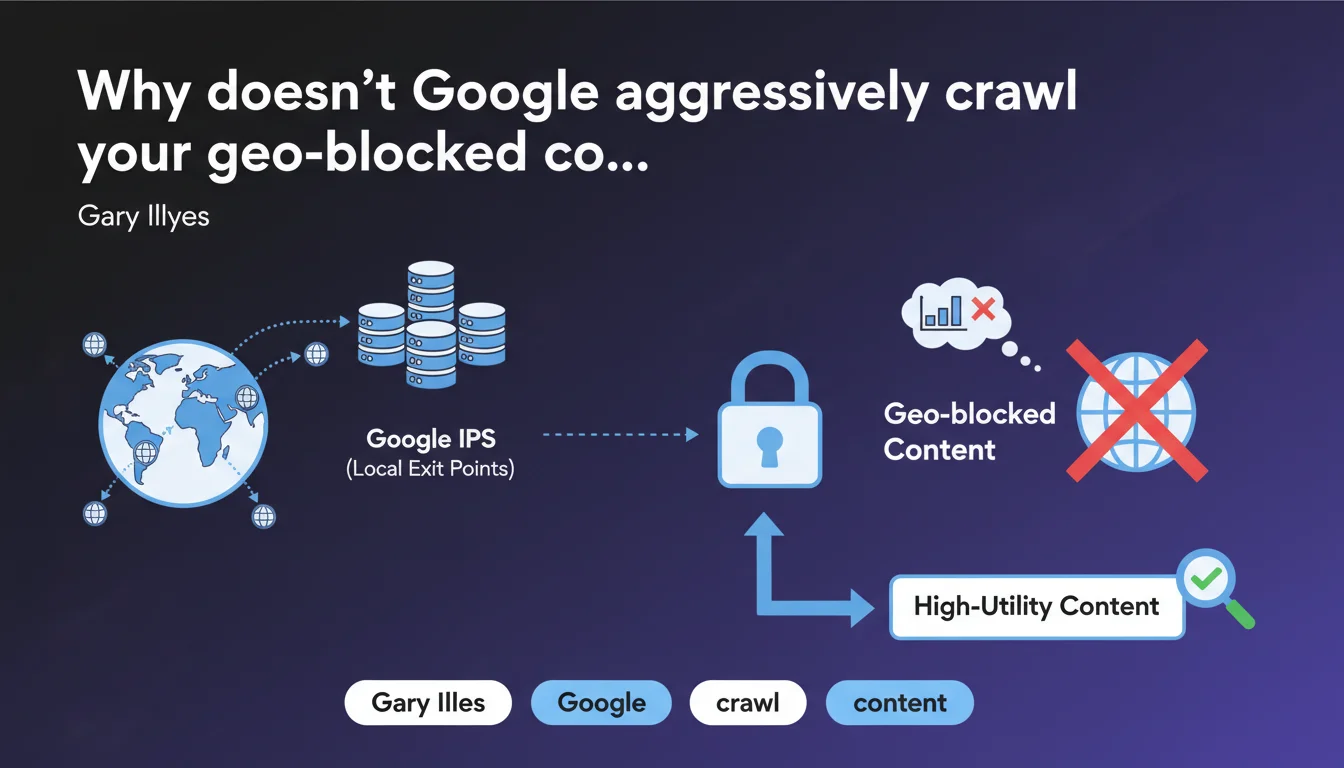
Google has IPs in different countries to access geo-blocked content, but its crawling capacity from these locations is extremely limited. These international exit points are reserved only for content deemed high-utility — in other words, most geo-localized content will never be crawled from these IPs. If your strategy relies on geo-blocking, you're playing with fire.
What you need to understand
What does this concretely mean for Google's crawling?
Google has distributed infrastructure across the world, but not all IPs are equal in terms of crawling capacity. Exit points located in countries other than the United States have only a fraction of the available crawling power.
In practice? If your site blocks access based on IP geolocation, Google won't be able to crawl massively from these international exit points. The allocation of these resources is strictly rationed — reserved for content that Google deems important enough to justify the effort.
How does Google decide which content deserves these limited resources?
Gary Illyes speaks of "high-utility content," but he doesn't specify the criteria. It's reasonable to assume this refers to pages with strong user demand, significant backlinks, or established organic traffic from other regions.
The problem: if your geo-blocked content hasn't yet demonstrated its value, it risks remaining invisible. It's a vicious cycle — no crawling, no indexation, no traffic, and therefore no utility signals.
What are the implications for sites with regional versions?
Sites with country-specific versions (e.g., .fr accessible only from France) face major risk. Most of Google's crawling happens from the United States, and if your content is blocked for these IPs, you drastically limit your visibility.
Even with properly configured hreflang, Google must be able to access the content to validate the signals. If the bot hits a geographic wall, hreflang tags are useless.
- Google's non-US IPs have significantly reduced crawling capacity
- Only content deemed "high-utility" benefits from these limited resources
- Strict geo-blocking prevents proper indexation, even with hreflang
- No crawling = no utility signals = vicious cycle
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Absolutely. For years, we've seen that sites with strict geo-blocking encounter recurring indexation problems. Undiscovered pages, ignored regional versions, hreflang not being taken into account — all of this can be explained by this capacity limitation.
What's interesting is that Gary Illyes finally admits it openly. Before, Google remained vague on the subject, leading people to believe the bot could crawl "from anywhere." The reality is less rosy: most crawling remains concentrated on US IPs, and the rest is occasional troubleshooting.
What gray areas remain in this statement?
Gary Illyes doesn't precisely define what constitutes "high-utility content." Is it based on Search Console? Inbound links? Direct traffic? Brand popularity? [To verify] — no clear metrics are provided.
Another area of confusion: what exactly is this "limited capacity"? Are we talking about a ratio of 1 to 10? 1 to 100? Without numbers, it's difficult to assess the real risk. What we know from experience: if your site isn't major, don't count on these international IPs.
In what cases could this rule be bypassed?
There are cases where Google can obtain content without relying on classical crawling. For example, if your content is distributed via third-party APIs, widely shared RSS feeds, or if CDNs expose your data without geographic restrictions.
But let's be honest: these cases are rare. Most sites with geo-blocking find themselves in a dead end — no crawling, no indexation. And even if Google occasionally accesses the content, nothing guarantees complete or regular indexation.
Practical impact and recommendations
What should you concretely do if your site uses geo-blocking?
First rule: never block Google bots, regardless of their IP origin. Use the robots.txt file or X-Robots-Tag headers to control indexation, but always allow access to the content.
If you absolutely must restrict access geographically (legal compliance, distribution rights), configure an exception for the Googlebot user-agent. This allows the bot to crawl from any IP while maintaining your restrictions for human users.
How do you verify that your site isn't a victim of this problem?
Use Search Console to monitor crawl errors related to regional versions. If important pages aren't indexed or if hreflang tags aren't detected, it's often linked to geo-blocking.
Also test with the URL inspection tool: submit your regional URLs and verify that Google can access the content properly. If you notice blockages, adjust your geo-location rules immediately.
What mistakes should you absolutely avoid?
Don't rely on hreflang tags to compensate for strict geo-blocking — they only work if Google can access the content. Many sites think that indicating an alternative version is enough, but if that version is blocked, hreflang is useless.
Another common mistake: blocking suspicious IPs "as a precaution." If you use a WAF or CDN with automatic geo-filtering, verify that Google's IP ranges aren't blacklisted by mistake. This happens more often than you'd think.
- Explicitly allow all Googlebot user-agents, regardless of IP origin
- Regularly check Search Console to detect regional crawl errors
- Test content access via the URL inspection tool for each language/regional version
- Audit WAF/CDN geo-filtering rules to avoid accidentally blocking Google
- Don't rely solely on hreflang — content must be accessible first
- Document geographic exceptions for Googlebot in server configuration
❓ Frequently Asked Questions
Google crawle-t-il mon contenu géobloqué depuis des IPs locales ?
Puis-je bloquer les IPs américaines de Google si mon audience est uniquement européenne ?
Les balises hreflang fonctionnent-elles si mon contenu est géobloqué ?
Comment autoriser Googlebot tout en maintenant un géoblocage pour les utilisateurs ?
Comment savoir si mon site est affecté par cette limitation de crawl ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 12/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.