Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
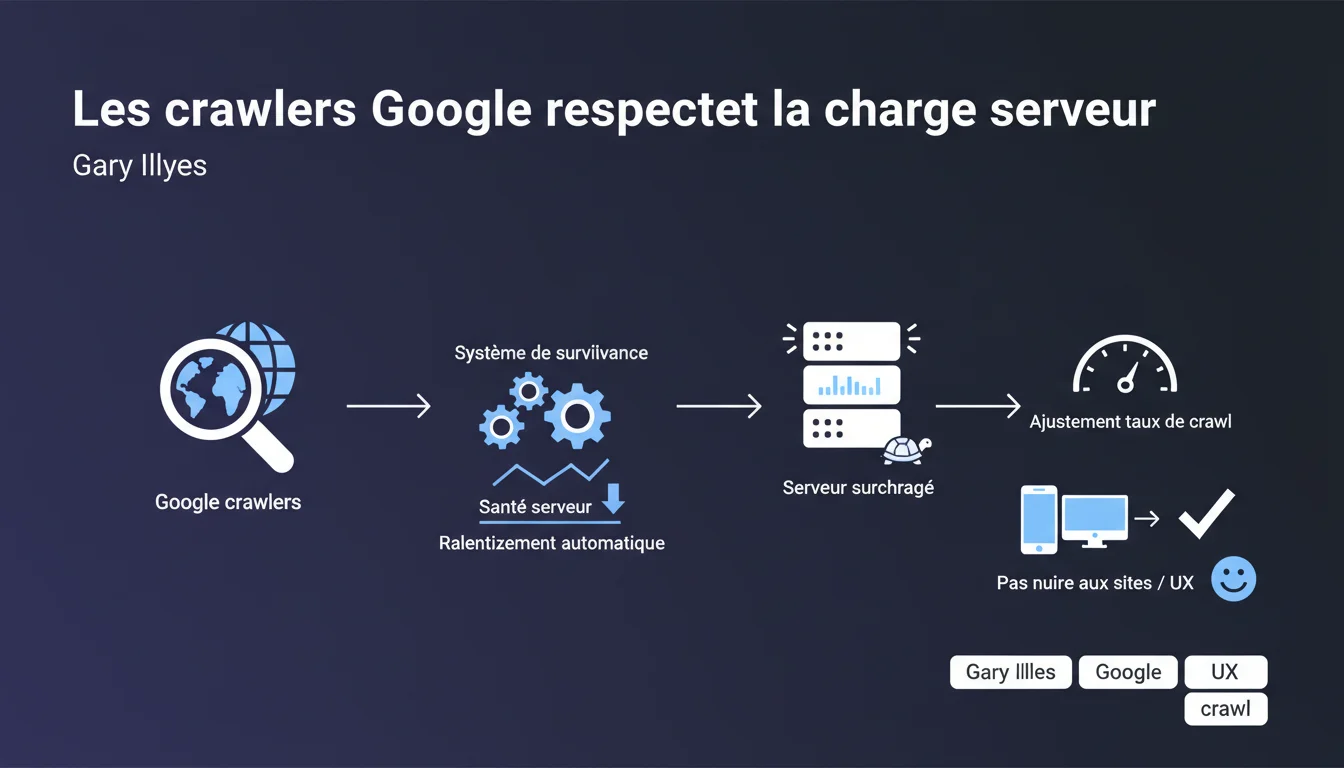
Google affirme disposer d'un système de surveillance qui détecte la charge serveur et ajuste automatiquement le taux de crawl pour éviter toute surcharge. L'objectif affiché : crawler efficacement sans pénaliser les performances des sites. Cette promesse mérite d'être confrontée à la réalité terrain.
Ce qu'il faut comprendre
Que signifie concrètement ce système de surveillance de charge serveur ?
Google utilise des mécanismes qui analysent les temps de réponse et les codes d'erreur HTTP lors du crawl. Lorsque les serveurs mettent plus de temps à répondre ou renvoient des erreurs 5xx, le robot réduit automatiquement son rythme d'exploration.
Ce système vise théoriquement un équilibre : crawler le maximum de pages sans faire crasher le serveur. La modulation se fait page par page, domaine par domaine, selon la capacité détectée en temps réel.
Pourquoi Google a-t-il développé ce mécanisme ?
Historiquement, les crawlers agressifs pouvaient provoquer des surcharges serveur, surtout sur les infrastructures modestes. Un site temporairement indisponible à cause du crawl Google nuisait à l'expérience utilisateur — et donc aux résultats de recherche.
Le moteur a donc intérêt à éviter de tuer ses sources de contenu. C'est autant une question d'efficacité que de relations publiques : personne n'aime qu'un robot mette son site à genoux.
Comment ce système interagit-il avec le paramétrage manuel du crawl ?
Dans la Search Console, les webmasters peuvent demander un ajustement du taux de crawl — mais Google n'accepte que les demandes de réduction. Impossible d'exiger plus de passages : le robot décide seul de sa fréquence maximale selon la santé du serveur et la qualité du contenu.
Le système automatique prend le dessus. Même si vous n'avez rien configuré, Google ralentit si vos temps de réponse explosent. Et si vous demandez une réduction, le robot la respecte — mais ne garantit jamais de remonter spontanément.
- Surveillance en temps réel : Google observe les latences et erreurs serveur pendant le crawl
- Modulation automatique : le taux de crawl diminue si les serveurs peinent à répondre
- Priorité à la stabilité : l'objectif est d'éviter les surcharges et les downtime provoqués par le robot
- Paramétrage limité : on peut demander une réduction manuelle, jamais une accélération
- Pas de garanties formelles : Google ajuste selon ses propres critères de santé serveur
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui et non. Sur les infrastructures solides — serveurs dédiés, CDN performants — le système de modulation automatique fonctionne globalement bien. Les logs montrent effectivement des ralentissements du crawl quand les temps de réponse augmentent.
Mais sur les hébergements partagés low-cost ou les CMS mal optimisés, la réalité est plus nuancée. Google peut ralentir… mais après avoir déjà provoqué une surcharge. Le robot détecte le problème quand c'est déjà en cours, pas forcément avant. [A vérifier] : l'efficacité prédictive de ce système reste floue — Google ne dit pas s'il anticipe les surcharges ou s'il réagit seulement a posteriori.
Quelles nuances faut-il apporter à cette promesse d'ajustement automatique ?
Premier point : Google ne précise pas le délai de réaction. Combien de temps entre la détection d'une surcharge et la réduction effective du crawl ? Quelques secondes ? Plusieurs minutes ? Sur un serveur sous tension, ça peut faire toute la différence.
Deuxième point : ce mécanisme ne protège que contre le crawl de Googlebot. Les autres robots — Bingbot, crawlers SEO tiers, scrapers malveillants — ne sont pas régulés par ce système. Un serveur peut donc rester en surcharge malgré le ralentissement de Google.
Troisième point, et il est crucial : ce système ne compense pas une architecture technique défaillante. Si votre CMS génère des pages en 3 secondes parce que la base de données n'est pas indexée, Google ralentira… mais le vrai problème reste entier. La modulation du crawl est un pansement, pas une solution structurelle.
Dans quels cas ce mécanisme ne suffit-il pas ?
Sur les sites avec des facettes infinies (e-commerce mal paramétré, calendriers sans limite temporelle), Google peut crawler des milliers de variations inutiles avant de ralentir. Le robot détecte une surcharge, pas forcément un gaspillage de crawl budget.
Autre cas problématique : les migrations ou refonte massives. Quand des centaines de milliers de redirections 301 sont déployées d'un coup, le crawl peut exploser temporairement. Google ralentit, certes — mais le pic initial peut quand même faire mal si le serveur n'est pas dimensionné pour l'encaisser.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser ce système de modulation ?
Première étape : monitorer les temps de réponse serveur spécifiquement pour Googlebot. Utilisez les logs serveur (analysez les user-agents) ou la Search Console (section "Statistiques d'exploration"). Si les latences explosent, le robot ralentira — mais vous perdrez en fréquence de crawl.
Deuxième action : optimiser la vitesse de génération des pages. Cache serveur, CDN, optimisation base de données, lazy loading des ressources lourdes. Plus vos pages répondent vite, plus Google peut crawler sans risquer de vous surcharger. C'est gagnant-gagnant.
Troisième levier : utiliser le fichier robots.txt et les directives crawl-delay (bien que Google ne respecte pas officiellement crawl-delay, certains autres robots oui). Bloquez les sections inutiles — facettes, paramètres d'URL redondants, contenus paginés à l'infini — pour concentrer le crawl sur les pages stratégiques.
Quelles erreurs éviter absolument ?
Ne jamais ignorer les erreurs 5xx dans les logs. Si Googlebot provoque régulièrement des erreurs serveur, c'est que votre infrastructure ne suit pas. Le robot ralentira, mais votre indexation risque de stagner. Mieux vaut corriger la cause que subir la modulation.
Évitez aussi de demander une réduction manuelle du crawl sans raison solide. Google ne remonte pas spontanément le taux une fois réduit. Vous risquez de vous retrouver sous-crawlé pendant des mois, avec des contenus frais qui mettent une éternité à être indexés.
Dernier piège : croire que ce système remplace une stratégie de crawl budget. Google peut ralentir pour préserver votre serveur tout en gaspillant du budget sur des pages sans valeur. Optimiser l'un ne dispense pas d'optimiser l'autre.
Comment vérifier que votre site gère correctement le crawl Google ?
- Analysez les statistiques d'exploration dans la Search Console : temps de réponse, codes HTTP, volumétrie crawlée par jour
- Surveillez les logs serveur pour Googlebot : fréquence, user-agent, pages visitées, latences
- Comparez le taux de crawl avec le taux d'indexation : si Google crawle beaucoup mais indexe peu, problème de qualité ou de duplication
- Vérifiez les erreurs 5xx ou timeout : signal direct que le serveur ne suit pas la charge
- Testez la vitesse de génération des pages en conditions réelles (pas seulement PageSpeed qui teste le front-end)
- Évaluez l'impact du cache serveur : Googlebot bénéficie-t-il du cache ou tape-t-il à chaque fois en base ?
- Désactivez temporairement les plugins ou scripts lourds pour mesurer leur impact sur les temps de réponse
Le système de modulation automatique du crawl Google est une sécurité, pas une solution miracle. Il réagit aux surcharges mais ne les anticipe pas nécessairement. La vraie stratégie consiste à optimiser l'infrastructure, contrôler les pages crawlées et monitorer les signaux serveur en continu.
Ces optimisations touchent à la fois au code, à l'architecture serveur et à la stratégie SEO. Les croiser efficacement demande une expertise technique pointue et une vision d'ensemble — difficile à réunir en interne sans ressources dédiées. Si ces sujets dépassent vos compétences actuelles ou que vous manquez de temps pour les piloter, un accompagnement par une agence SEO spécialisée peut vous faire gagner des mois sur la montée en performance et éviter des erreurs coûteuses.
❓ Questions frequentes
Google peut-il vraiment protéger mon serveur contre une surcharge liée au crawl ?
Puis-je demander à Google de crawler plus rapidement mon site ?
Comment savoir si Google ralentit le crawl à cause de mon serveur ?
Ce système fonctionne-t-il pour tous les robots de Google ?
Dois-je quand même optimiser mon crawl budget si Google ajuste automatiquement ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/05/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.