Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
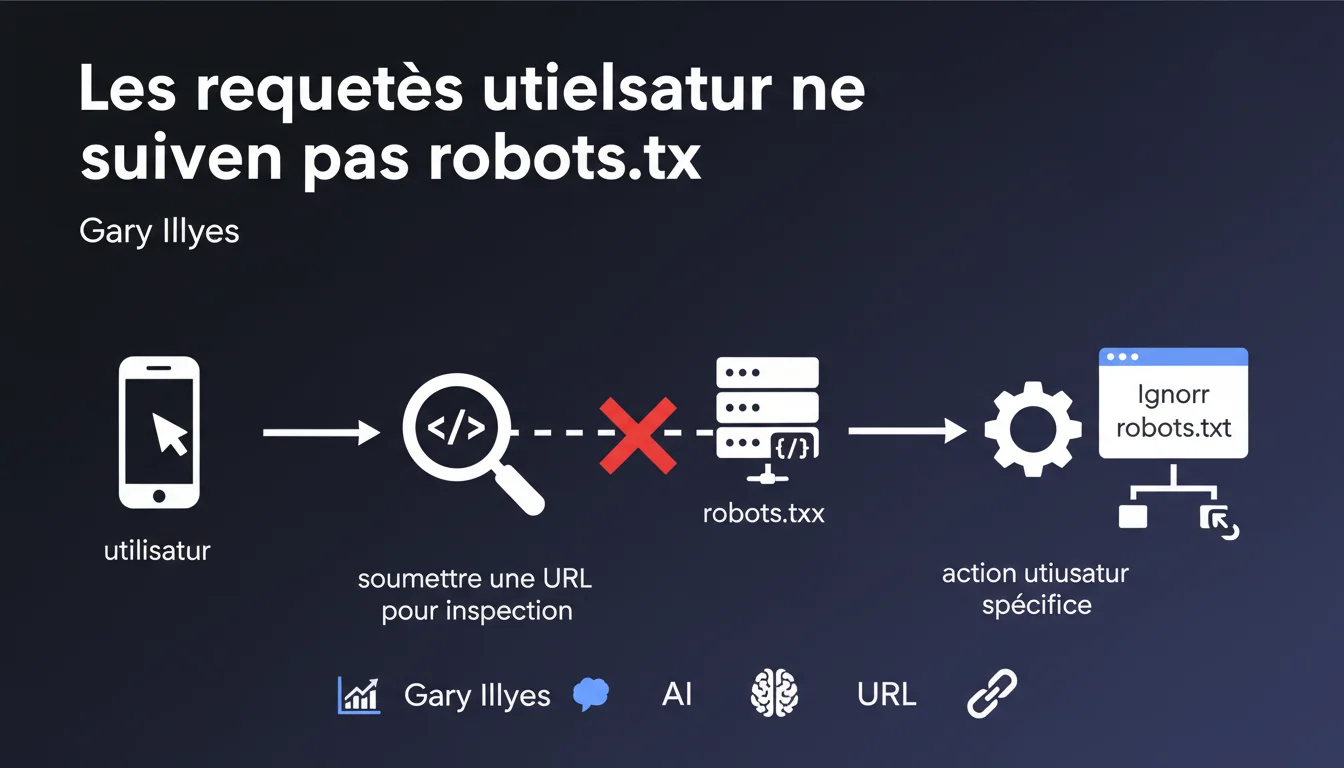
Google distingue clairement les actions initiées par un utilisateur (comme l'inspection d'URL via Search Console) des crawls automatisés. Dans ces cas spécifiques, robots.txt peut être ignoré car il ne s'agit pas d'un robot mais d'une demande explicite d'un humain. Cette nuance a des implications directes sur la façon dont on interprète les blocages robots.txt.
Ce qu'il faut comprendre
Quelle différence Google fait-il entre un crawl et une action utilisateur ?
Quand un SEO soumet manuellement une URL pour inspection dans Search Console, il initie une action volontaire. Google ne considère pas cette requête comme un crawl automatisé soumis aux règles du robots.txt.
Le fichier robots.txt a été conçu pour contrôler les robots autonomes, pas les demandes explicites d'un humain. Cette distinction permet à Google de répondre à vos inspections même si l'URL est techniquement bloquée par robots.txt.
Dans quels cas précis robots.txt est-il ignoré ?
L'exemple le plus évident : l'outil d'inspection d'URL dans Search Console. Vous demandez à voir comment Googlebot rendrait une page — c'est votre initiative directe, pas un crawl programmé.
D'autres outils Google peuvent appliquer cette logique : les tests de données structurées, le test des résultats enrichis, ou encore l'outil de test d'optimisation mobile. Dans tous ces cas, vous déclenchez l'action.
Que se passe-t-il pour le crawl classique ?
Les crawls automatisés — ceux qui constituent 99% de l'activité de Googlebot — respectent strictement le robots.txt. Si vous bloquez /admin/ dans votre fichier, Googlebot ne le visitera pas de lui-même.
Mais si vous inspectez manuellement une URL de /admin/ via Search Console, Google vous montrera ce qu'il verrait s'il y avait accès. Cette asymétrie est volontaire et assumée par Google.
- Les crawls automatisés respectent robots.txt sans exception
- Les inspections manuelles (Search Console, outils de test) peuvent ignorer robots.txt
- Cette distinction repose sur la notion d'intention utilisateur explicite
- Le blocage robots.txt reste efficace pour contrôler le crawl budget et l'indexation automatique
Avis d'un expert SEO
Cette logique est-elle cohérente avec les observations terrain ?
Oui, complètement. N'importe quel praticien SEO a déjà constaté qu'il peut inspecter une URL bloquée par robots.txt dans Search Console. Google affiche même un avertissement indiquant que la page est bloquée, tout en la rendant quand même.
La nuance importante : cette inspection ne déclenche pas d'indexation. Vous obtenez un aperçu technique, mais la page reste hors index si robots.txt la bloque effectivement.
Quelles confusions cette déclaration peut-elle créer ?
Certains SEO juniors pourraient en déduire à tort que robots.txt ne sert à rien puisque Google « peut l'ignorer ». C'est une interprétation dangereuse.
Soyons clairs : robots.txt reste l'outil principal de contrôle du crawl. Ce que Gary Illyes décrit ici est une exception étroite, limitée aux actions volontaires d'un utilisateur authentifié. Le crawl organique, lui, reste totalement soumis aux règles.
[À vérifier] Google ne précise pas si d'autres « actions utilisateur » — comme les rapports automatisés ou les alertes Search Console — entrent dans cette catégorie. La frontière exacte entre « action utilisateur » et « processus automatisé » reste floue.
Faut-il modifier sa stratégie robots.txt suite à cette déclaration ?
Non. Absolument rien ne change dans la façon dont vous devez utiliser robots.txt au quotidien.
Continuez de bloquer les sections sensibles, de gérer votre crawl budget, et de contrôler l'indexation via robots.txt + noindex selon vos besoins. Cette déclaration est surtout une clarification technique pour expliquer pourquoi Search Console fonctionne comme il fonctionne.
Impact pratique et recommandations
Que faut-il retenir pour la gestion quotidienne du robots.txt ?
Rien ne change dans votre approche du fichier robots.txt. Continuez de l'utiliser pour bloquer les zones sensibles, gérer le crawl budget, et empêcher l'indexation de contenu dupliqué ou sans valeur.
Si vous utilisez l'outil d'inspection d'URL dans Search Console pour diagnostiquer des problèmes, vous comprenez maintenant pourquoi vous pouvez voir des pages bloquées. C'est voulu, pas un bug.
Quelles erreurs d'interprétation éviter absolument ?
Ne confondez pas « Google peut ignorer robots.txt dans certains cas » avec « robots.txt ne fonctionne pas ». Le premier est vrai pour les actions utilisateur explicites. Le second est totalement faux pour le crawl automatisé.
Autre piège : penser que cette exception permet de forcer l'indexation d'une page bloquée. Non. L'inspection manuelle ne déclenche pas d'indexation. Le blocage robots.txt reste actif pour tous les processus automatiques.
- Maintenez votre robots.txt à jour et testez-le régulièrement via Search Console
- Utilisez l'outil d'inspection d'URL pour diagnostiquer des pages bloquées sans crainte — c'est l'usage prévu
- Ne comptez pas sur robots.txt seul pour masquer du contenu sensible — utilisez aussi l'authentification serveur
- Documentez vos règles robots.txt pour éviter les blocages accidentels lors de refonte
- Surveillez les rapports de couverture d'index pour détecter les pages bloquées involontairement
Comment auditer son robots.txt efficacement ?
Passez régulièrement en revue votre fichier robots.txt pour vérifier qu'aucune règle obsolète ne bloque du contenu stratégique. Les refontes, migrations, et ajouts de sections créent souvent des blocages non intentionnels.
Utilisez l'outil de test robots.txt dans Search Console pour valider chaque règle. Croisez avec les données de crawl pour identifier les URLs bloquées qui reçoivent pourtant du trafic référent — signe d'un problème potentiel.
❓ Questions frequentes
Est-ce que l'inspection manuelle d'une URL bloquée par robots.txt peut déclencher son indexation ?
Quels autres outils Google ignorent robots.txt comme l'outil d'inspection d'URL ?
Si robots.txt peut être ignoré, comment protéger réellement du contenu sensible ?
Cette exception s'applique-t-elle aux autres moteurs de recherche comme Bing ?
Faut-il bloquer Search Console avec robots.txt pour éviter ces inspections ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/05/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.