Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Faut-il vraiment optimiser tout le site après une mise à jour algorithmique ?
- □ Search Console intègre les données IA : mais savez-vous vraiment ce que vous mesurez ?
- □ Faut-il vraiment optimiser différemment son site pour les AI Overviews de Google ?
- □ Google Trends est-il vraiment un outil stratégique pour orienter sa ligne éditoriale SEO ?
- □ Comment Search Console peut-il vraiment révéler ce que cherche votre audience ?
- □ Le SEO est-il vraiment mort ou juste en train de muter sous nos yeux ?
- □ Comment la qualité du contenu influence-t-elle directement le taux d'indexation par Google ?
- □ Un sitemap suffit-il vraiment à garantir l'indexation de vos pages ?
- □ Votre CDN ou firewall bloque-t-il Googlebot sans que vous le sachiez ?
- □ Comment Google Trends utilise-t-il réellement le Knowledge Graph pour identifier les topics ?
- □ L'index Google a-t-il vraiment une limite de capacité ?
- □ Le marketing traditionnel est-il devenu indispensable pour ranker sur Google ?
- □ Les données structurées sont-elles vraiment inutiles pour le classement SEO ?
- □ Faut-il vraiment faire vérifier toutes vos traductions automatiques pour le SEO ?
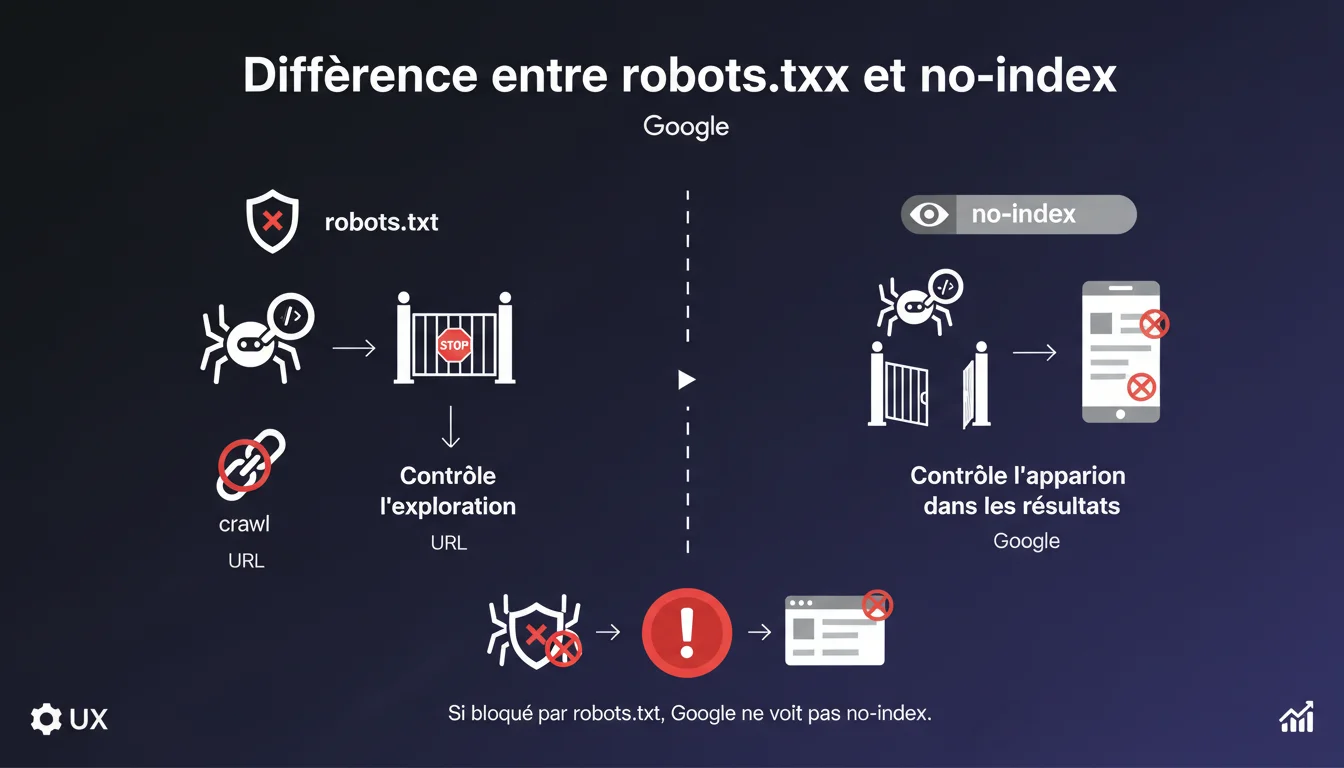
Robots.txt et no-index ne font pas du tout la même chose — l'un bloque l'exploration, l'autre l'indexation. Le piège ? Si vous bloquez une URL via robots.txt, Google ne verra jamais votre balise no-index. Conclusion : robots.txt pour gérer le crawl budget, no-index pour contrôler ce qui apparaît dans les SERP.
Ce qu'il faut comprendre
Quelle est la vraie différence entre robots.txt et no-index ?
Le robots.txt agit comme un panneau "accès interdit" pour les crawlers. Vous lui indiquez quelles URLs il ne doit même pas essayer d'explorer. C'est une instruction en amont, avant même que Googlebot ne touche à votre page.
La balise no-index, elle, intervient après l'exploration. Le crawler visite votre page, lit le contenu, mais reçoit l'ordre de ne pas l'inclure dans l'index de recherche. La page existe, Google la connaît, mais elle ne ressortira jamais dans les résultats.
Pourquoi bloquer avec robots.txt empêche le no-index de fonctionner ?
Si vous interdisez l'accès à une URL via robots.txt, Googlebot n'ira jamais la consulter. Il ne lira donc jamais le HTML, ni les balises meta qu'il contient — y compris votre précieux no-index.
Résultat ? L'URL peut rester indexée indéfiniment. Google n'a aucun moyen de savoir que vous ne voulez plus qu'elle apparaisse dans les résultats. C'est un cas classique d'erreur en cascade — vous pensez avoir sécurisé quelque chose, alors qu'en réalité vous avez créé une impasse technique.
Dans quels cas utiliser l'un plutôt que l'autre ?
Utilisez robots.txt quand vous voulez économiser du crawl budget ou empêcher l'exploration de zones techniques (admin, filtres à facettes, paramètres redondants). C'est un outil de gestion du trafic bot, pas de désindexation.
Utilisez no-index quand vous voulez qu'une page soit explorée (pour transmettre du jus via ses liens internes, par exemple) mais qu'elle ne pollue pas l'index. Typiquement : pages à faible valeur ajoutée, contenus dupliqués stratégiques, landing pages temporaires.
- Robots.txt : contrôle l'exploration, agit avant la visite du crawler
- No-index : contrôle l'indexation, nécessite que la page soit explorée
- Bloquer avec robots.txt rend le no-index invisible et donc inopérant
- Ne jamais combiner les deux sur une même URL si l'objectif est de désindexer
- Robots.txt = gestion du crawl budget ; no-index = gestion de la visibilité SERP
Avis d'un expert SEO
Cette distinction est-elle vraiment respectée sur le terrain ?
Soyons honnêtes : oui et non. Google suit bien cette logique dans 95% des cas, mais il existe des situations où une URL bloquée en robots.txt disparaît quand même de l'index — sans avoir jamais été explorée.
Ça arrive notamment quand Google détecte des signaux externes suffisamment forts (backlinks, mentions, anciennes versions en cache). Dans ce cas, il peut afficher l'URL avec un snippet générique du type "aucune information disponible". Mais cette désindexation reste partielle, peu fiable et lente. Ce n'est pas une stratégie — c'est un accident.
Faut-il vraiment s'interdire de combiner robots.txt et no-index ?
La règle officielle est claire, mais elle masque une nuance : si vous avez déjà une URL indexée et que vous voulez la supprimer définitivement, la séquence correcte est d'abord de laisser Google explorer la page avec le no-index, attendre la désindexation complète, puis seulement après bloquer en robots.txt si vous voulez économiser du crawl.
Inverser cet ordre — ou bloquer d'entrée — piège l'URL dans un état zombie. Elle reste connue de Google, mais inaccessible. Et vous n'avez plus aucun levier pour la faire disparaître proprement.
Quels sont les cas limites où cette règle devient floue ?
Premier cas : les pages 404 bloquées en robots.txt. Google ne peut pas voir le code 404, donc l'URL peut persister dans l'index avec un statut ambigu. Mieux vaut laisser le 404 accessible pour que Google enregistre bien la suppression.
Deuxième cas : les redirections 301 bloquées en robots.txt. Le crawler ne suit jamais la redirection, donc le jus SEO ne se transmet pas. Si votre objectif était de consolider l'autorité, vous avez tout cassé. Là encore, il faut laisser la redirection explorée.
Impact pratique et recommandations
Comment auditer son site pour repérer ces conflits ?
Première étape : extraire toutes les URLs bloquées en robots.txt et les croiser avec votre index Google (via Search Console ou un scraper custom). Si vous trouvez des URLs bloquées qui apparaissent encore dans les SERP, c'est un signal d'alerte.
Deuxième étape : identifier les pages avec balise no-index ET directive Disallow dans le robots.txt. C'est souvent le signe d'une confusion dans la stratégie. Soit vous voulez désindexer proprement (alors virez le Disallow), soit vous voulez bloquer le crawl (alors virez le no-index, il ne sert à rien).
Quelles erreurs éviter absolument en production ?
Ne jamais bloquer en robots.txt une section entière en pensant que ça suffit à la désindexer. Si ces pages étaient déjà explorées, elles resteront visibles dans Google — parfois pendant des mois.
Ne jamais ajouter un no-index sur une page stratégique que vous auriez bloquée par erreur en robots.txt. Google ne le verra jamais. Il faut d'abord débloquer, laisser le crawler passer, puis ajouter le no-index si nécessaire.
Évitez aussi de jongler entre les deux méthodes sur des URLs en constante évolution (facettes, filtres dynamiques). Définissez une règle unique : soit vous bloquez tout en robots.txt, soit vous laissez explorer avec no-index. Pas de mix aléatoire.
Que faut-il mettre en place concrètement ?
- Auditer le robots.txt tous les trimestres et vérifier qu'aucune URL stratégique n'est bloquée par erreur
- Croiser la liste des Disallow avec l'index Google réel pour détecter les pages zombies
- Sur les pages à désindexer : d'abord no-index, attendre la désindexation complète, puis éventuellement bloquer en robots.txt
- Documenter la logique derrière chaque règle robots.txt et chaque no-index pour éviter les incohérences lors des mises à jour
- Utiliser les logs serveur pour mesurer l'impact réel des modifications sur le comportement de Googlebot
- Former les équipes techniques à cette distinction pour éviter les configs contradictoires lors des déploiements
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/12/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.