Declaration officielle
Autres déclarations de cette vidéo 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
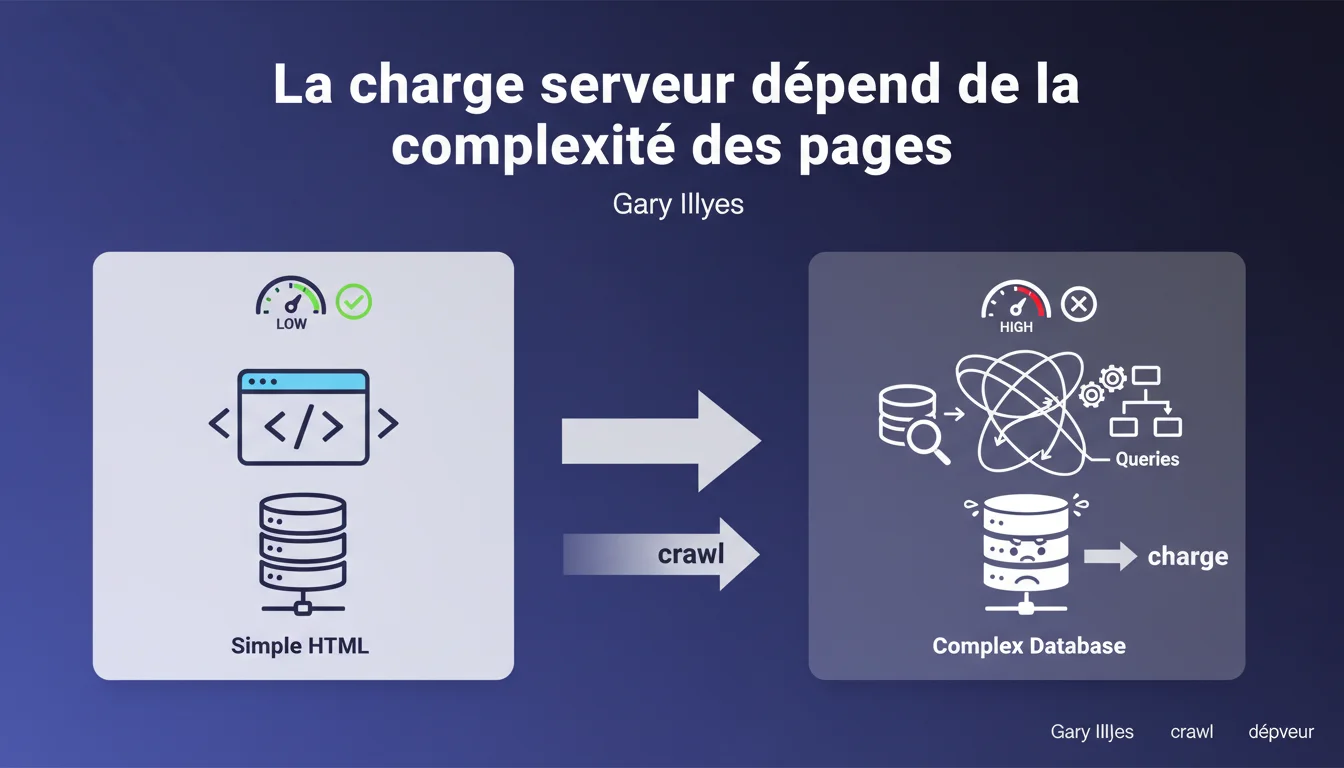
Gary Illyes rappelle que l'impact du crawl sur vos serveurs dépend avant tout de votre stack technique. Des requêtes SQL complexes ou des opérations coûteuses génèrent une charge bien plus importante qu'un site HTML statique, même avec un volume de crawl identique. Le crawl budget n'est pas qu'une histoire de quotas — c'est aussi une question de performance infrastructure.
Ce qu'il faut comprendre
Qu'est-ce que Google entend par « charge serveur » dans ce contexte ?
Quand Googlebot crawle votre site, chaque requête déclenche des opérations côté serveur : génération de pages dynamiques, appels à des bases de données, exécution de scripts, agrégation de contenu. La « charge » mesure les ressources CPU, mémoire et I/O consommées pour servir ces pages au bot.
Un site HTML statique ? Le serveur lit un fichier déjà généré et l'envoie. Une page dynamique complexe ? Le serveur interroge plusieurs tables SQL, compile des templates, exécute du code métier — et ça, ça coûte. Beaucoup plus.
Pourquoi cette distinction est-elle importante pour le SEO ?
Parce qu'un serveur surchargé ralentit, timeout, ou pire : renvoie des erreurs 500/503. Googlebot détecte ces signaux et ajuste son rythme de crawl à la baisse pour éviter de casser votre infra. Résultat : certaines pages sont crawlées moins souvent, voire ignorées.
Si votre site génère une charge importante par page, vous brûlez votre crawl budget plus vite. Moins de pages crawlées par session, moins de fraîcheur dans l'index, impact potentiel sur le classement des pages qui bougent souvent.
Quels sont les points essentiels à retenir ?
- La charge serveur ne dépend pas du nombre de pages, mais de la complexité technique de chaque page générée
- Des opérations coûteuses (requêtes SQL lentes, appels API synchrones, agrégations complexes) multiplient l'impact du crawl
- Un site HTML statique supporte un volume de crawl bien plus élevé qu'un CMS mal optimisé
- Googlebot ajuste son taux de crawl en fonction de la capacité de réponse du serveur — pas seulement des quotas théoriques
- Optimiser la performance backend devient un levier SEO direct, pas juste une question de confort utilisateur
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement. On voit régulièrement des sites WordPress ou Magento avec des temps de génération de page catastrophiques — 2-3 secondes backend — se faire throttler par Googlebot alors qu'ils ont « seulement » 50 000 pages. À l'inverse, des sites Next.js ou Hugo en statique pur avec 500 000 URLs se font crawler sans broncher.
Le problème, c'est que beaucoup de SEO pensent encore que le crawl budget ne concerne que les gros sites. Faux. Si votre architecture est lourde, vous êtes impacté même avec 10 000 pages.
Quelles nuances faut-il apporter à cette affirmation ?
Google ne dit pas « évitez le dynamique ». Il dit : maîtrisez votre complexité technique. Une page dynamique bien optimisée (cache Redis, queries indexées, génération asynchrone) peut être aussi rapide qu'un fichier HTML. Le vrai souci, c'est le code legacy non optimisé, les CMS mal configurés, les plugins en cascade.
Autre point — et Gary ne le mentionne pas ici : la charge serveur ne concerne pas que le crawl. Elle impacte aussi le rendering JavaScript si Googlebot doit exécuter du code lourd côté client. Là, c'est votre JS qui devient le goulot, pas votre backend.
Dans quels cas cette règle ne s'applique-t-elle pas strictement ?
Si vous utilisez un CDN avec edge caching intelligent (Cloudflare, Fastly, etc.), Googlebot peut taper dans le cache plutôt que solliciter directement votre serveur. La charge perçue diminue drastiquement, même avec du dynamique derrière.
Pareil pour les sites qui génèrent leurs pages à la build (JAMstack, SSG) : une fois déployé, tout est statique. Zéro charge backend, zéro requête DB pendant le crawl. Le constat de Gary ne s'applique alors plus — votre architecture a déjà absorbé le coût.
Impact pratique et recommandations
Que faut-il faire concrètement pour réduire la charge serveur au crawl ?
Primo : auditez vos temps de génération backend. Installez un APM (New Relic, Datadog, Blackfire) et identifiez les pages qui mettent 1+ seconde à se générer. Ce sont vos cibles prioritaires. Regardez les slow queries SQL, les appels API synchrones, les boucles métier inutiles.
Secundo : mettez en place du cache serveur agressif. Varnish, Redis, opcache PHP — ce qui colle à votre stack. L'idée : servir du pré-généré à Googlebot, pas recalculer la page à chaque hit. Un cache bien configuré divise la charge par 10, facilement.
Tertio : passez en statique ce qui peut l'être. Les pages catégories, les fiches produits stables, les contenus éditoriaux — tout ça peut être pré-rendu et servi comme fichiers plats. Les frameworks modernes (Next.js ISR, Gatsby, Eleventy) permettent un mix dynamique/statique intelligent.
Quelles erreurs éviter absolument ?
Ne laissez jamais Googlebot taper directement sur des endpoints API ou des pages admin non cachées. On voit encore des sites avec des URLs de recherche interne, des filtres à facettes non optimisés, des pages de listing qui font 15 requêtes SQL imbriquées — et tout ça indexable.
Évitez aussi de sous-estimer l'impact du rendering JavaScript côté serveur. Si vous faites du SSR React/Vue sans cache, chaque crawl déclenche une exécution complète du framework. Coûteux. Très coûteux.
Comment vérifier que votre site est conforme aux attentes de Google ?
- Analysez vos logs serveur : temps de réponse moyen par URL crawlée, pics de charge pendant les sessions Googlebot
- Consultez le rapport Statistiques d'exploration dans Search Console : si le temps de réponse dépasse 500ms en moyenne, vous avez un problème
- Installez un monitoring APM pour traquer les requêtes SQL lentes et les goulots d'étranglement backend
- Testez vos pages stratégiques avec curl + time en simulant le user-agent Googlebot : le Time to First Byte (TTFB) doit rester sous 200-300ms
- Vérifiez votre config de cache : Redis/Varnish actif, taux de hit supérieur à 80% pour les pages crawlées
- Évaluez l'intérêt d'un passage partiel ou total en génération statique pour les contenus stables
❓ Questions frequentes
Est-ce qu'un site statique HTML est toujours mieux crawlé qu'un site dynamique ?
Comment savoir si Googlebot ralentit à cause de ma charge serveur ?
Le cache CDN réduit-il la charge serveur perçue par Googlebot ?
Dois-je privilégier une architecture JAMstack pour améliorer mon crawl budget ?
Les requêtes SQL lentes impactent-elles vraiment le crawl Google ?
🎥 De la même vidéo 10
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 29/05/2025
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.