Official statement
Other statements from this video 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
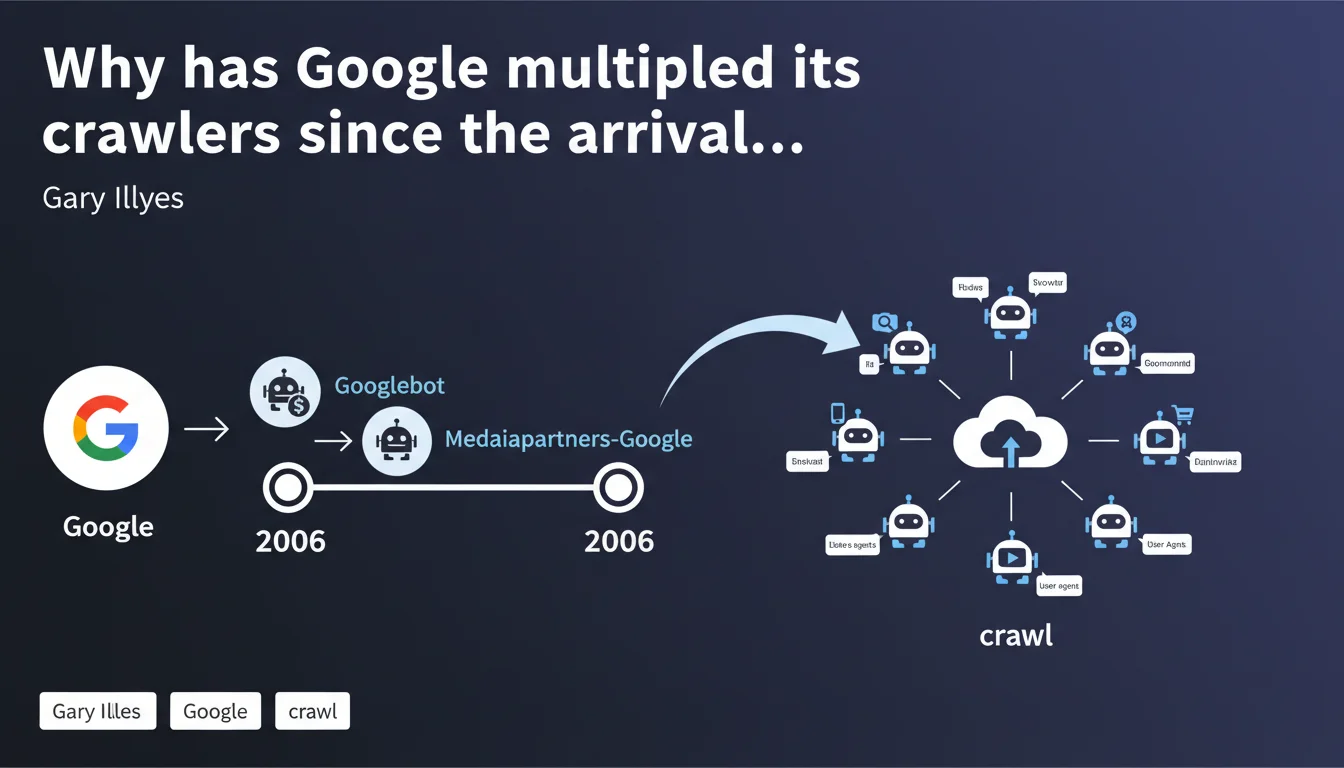
Google AdSense deployed its own distinct user agent separate from Googlebot in 2006, marking the beginning of a strategic fragmentation of crawling. Since then, Google's crawler ecosystem has continued to diversify — each bot having its own role, its rules, and its specific SEO implications. Understanding this multi-crawler architecture becomes essential for accurately diagnosing visibility issues.
What you need to understand
What is Mediapartners-Google and why does its launch mark a turning point?
Mediapartners-Google is the dedicated crawler for AdSense, introduced in 2006 to analyze page content and display relevant contextual advertisements. Unlike Googlebot, it does not directly participate in organic indexing.
Its appearance initiated a logic of functional specialization: rather than a single universal bot, Google gradually segmented its crawlers according to uses — advertising, images, news, mobile, JavaScript rendering, and so on.
How many Google crawlers does Google use today and what are they used for?
Google now has a dozen identifiable crawlers by their distinct user agent: Googlebot Desktop, Googlebot Smartphone, Googlebot Image, Googlebot Video, Googlebot News, Google-InspectionTool, AdsBot-Google, Mediapartners-Google, Google-Read-Aloud, Storebot-Google, GoogleOther.
Each bot has a specific role: Googlebot Smartphone evaluates mobile experience for mobile-first indexing, AdsBot-Google tests the quality of advertising landing pages, GoogleOther performs undocumented internal tests. This fragmentation complicates diagnosis — a partial block can go unnoticed if you only monitor a single user agent.
What is the direct implication for technical SEO?
The multiplication of crawlers requires granular management of robots.txt and crawl directives. Blocking Mediapartners-Google does not impact organic indexing, but disables AdSense. Blocking GoogleOther can disrupt Google tests with no immediate visible consequence.
The crawl budget is now distributed among these different agents. A site can be properly crawled on desktop but under-explored on mobile, or vice versa. Server logs become essential to identify which crawler actually accesses which sections.
- Mediapartners-Google: AdSense crawler, no direct organic SEO impact
- Progressive fragmentation since 2006: each Google product gradually obtained its own bot
- Diagnosis complexified: an indexing problem may stem from a targeted block on a single user agent
- Server logs essential to precisely map the activity of each crawler
- Robots.txt and meta robots must be tested against each relevant bot for your activity
SEO Expert opinion
Does this statement resolve historical blind spots?
Yes, but only partially. Gary Illyes officially anchors the start of the multi-crawler strategy in 2006, which clarifies the timeline. Before this confirmation, some considered Mediapartners-Google as merely a sub-program of Googlebot.
However, Google remains vague about GoogleOther, the catch-all bot used for unspecified internal tasks. No precise documentation exists on its crawling criteria, its frequency, or its exact role. [To verify]: the actual impact of GoogleOther on SEO performance remains largely speculative.
Do field observations confirm this fragmentation?
Absolutely. Analysis of server logs across thousands of sites reveals that Googlebot Smartphone and Googlebot Desktop do not have the same crawl priorities. Entire sections can be explored intensively by one and ignored by the other.
A frequent case: e-commerce sites with complex facets. Googlebot Desktop can massively crawl parameterized URLs, while Googlebot Smartphone focuses on main pages. Result: inconsistencies in mobile-first indexing that SEOs wrongly attribute to performance issues, when it is actually a crawl prioritization problem.
Should you treat each crawler differently in your SEO strategy?
Yes, but with discernment. Blocking Mediapartners-Google if you don't use AdSense makes sense — it frees up crawl budget. However, blocking AdsBot-Google when you run Google Ads can degrade your advertising Quality Score.
For GoogleOther, caution is warranted. Some SEOs block it to save crawl budget, others let it through to avoid interfering with potential Google tests. No reliable public data settles the debate. My approach: keep it active on strategic sites, block it on platforms with critical crawl budget.
Practical impact and recommendations
How do you precisely audit the activity of each crawler on my site?
Raw server log analysis remains the reference method. Segment requests by user agent and identify which bots access which sections, how often, and with what error rates.
Cross-reference this data with Search Console reports: if Googlebot Smartphone visits few of your strategic pages while mobile traffic is predominant, you have a prioritization problem. Tools like Screaming Frog Log Analyzer or OnCrawl facilitate this segmentation.
What robots.txt rules should you apply to optimize multi-crawler crawl budget?
Be selective and documented. Explicitly block crawlers not relevant to your business model: Mediapartners-Google if no AdSense, AdsBot-Google if no display campaigns, Google-Read-Aloud if you have no audio ambitions.
Always allow Googlebot, Googlebot-Image, Googlebot-Video and the mobile crawler prioritized for mobile-first indexing. Test each directive with the Search Console robots.txt testing tool — and verify that blocks do not unintentionally impact other bots as a side effect.
What should you do if a specific crawler seems to ignore certain critical pages?
First identify the cause: restrictive robots.txt, accidental meta noindex, redirect chains, excessive link depth. Use the URL inspection tool to simulate the crawl of the bot in question.
If the problem persists despite correct technical configuration, increase the internal visibility of these pages: add links from the homepage or thematic hubs, submit a dedicated XML sitemap, reduce directory depth. For complex sites with thousands of URLs, a sitemap segmented by content type improves prioritization.
- Analyze your server logs by segmenting by user agent (Googlebot Desktop, Smartphone, Image, etc.)
- Test your robots.txt against each relevant crawler via the Search Console
- Block only non-essential bots to your strategy (Mediapartners if no AdSense, for example)
- Monitor coverage reports to detect divergences between mobile and desktop crawlers
- Optimize link depth and internal structure for under-crawled strategic pages
- Document each robots.txt directive to avoid oversights during migrations or redesigns
❓ Frequently Asked Questions
Mediapartners-Google impacte-t-il le référencement naturel de mon site ?
Puis-je bloquer Mediapartners-Google sans risque si je n'utilise pas AdSense ?
GoogleOther est-il important pour le SEO ?
Comment savoir quel crawler Google visite mes pages stratégiques ?
Le mobile-first indexing utilise-t-il exclusivement Googlebot Smartphone ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 29/05/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.