Official statement
Other statements from this video 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
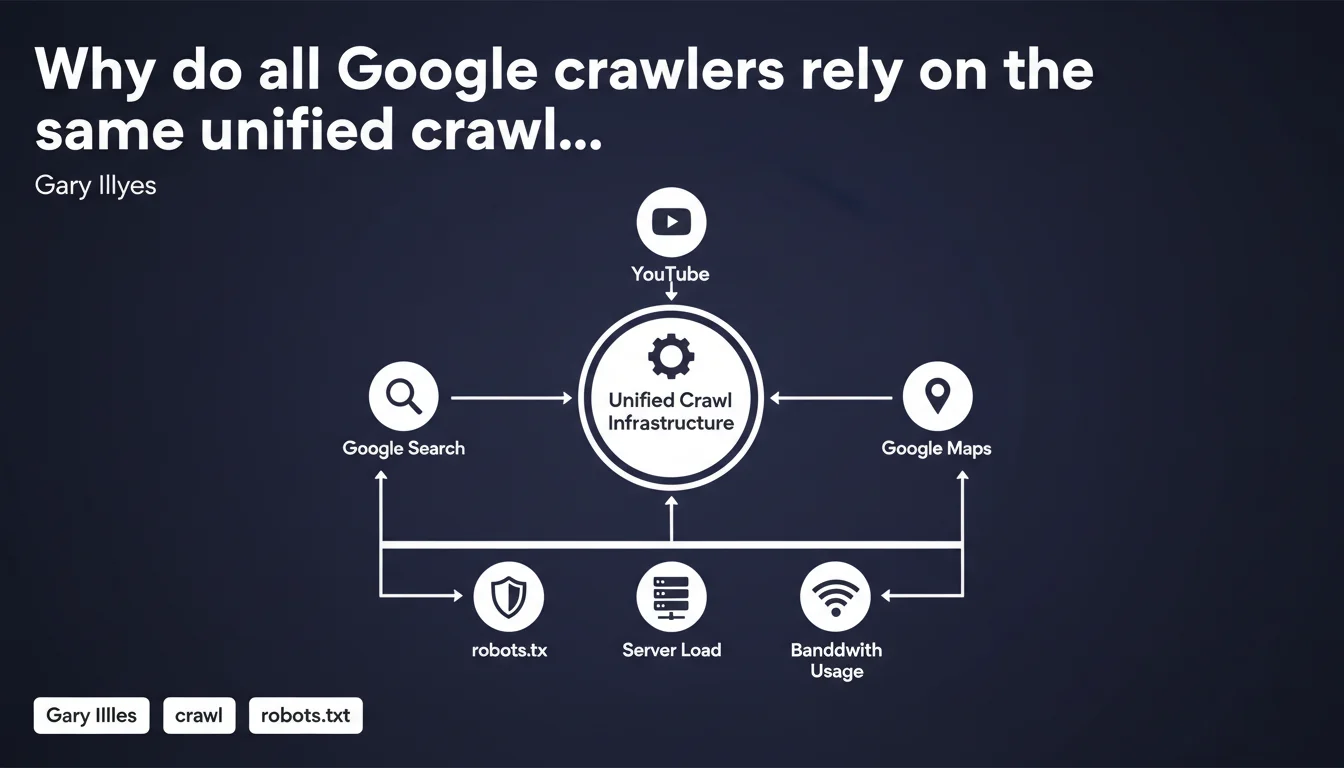
Google uses a single, unified crawl infrastructure for all its products — Googlebot Search, Googlebot Images, Googlebot News, and more. All crawlers share the same codebase and apply identical rules regarding robots.txt, server load, and bandwidth management. Direct consequence: blocking one crawler can potentially block multiple others.
What you need to understand
What does "unified crawl infrastructure" actually mean in practice?
Google has consolidated all its specialized crawlers under a single technical foundation. Whether it's Googlebot for standard search, Googlebot Images, or Googlebot News, they all now rely on the same crawling engine.
This technical consolidation means that behavior rules are identical across the board: respecting robots.txt, being courteous regarding server load, managing bandwidth efficiently. One codebase, one crawling logic.
Why did Google choose this direction?
Unification simplifies maintenance and guarantees consistent behavior. No need to manage dozens of crawlers with divergent policies anymore — which was a source of bugs and inconsistencies.
For website publishers, this also means that blocking one crawler in robots.txt can have collateral effects on other Google services. If you block Googlebot-Image to save bandwidth, you risk impacting image indexation in Google Images as well.
What are the implications for crawl budget?
The unified infrastructure applies the same politeness limits to all crawlers. Concretely, Google won't multiply requests just because it uses different user-agents.
Crawl budget is managed globally, with internal allocation between different content types (HTML, images, CSS, JS). Blocking one resource type doesn't necessarily free up budget for another — it depends on how Google prioritizes your content.
- All Google crawlers share the same codebase
- They respect the same robots.txt directives
- Server load management is unified
- Blocking one crawler can impact indexation across multiple Google products
- Crawl budget is managed globally, not per crawler
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, largely. We do observe that different Googlebots respect the same robots.txt directives and exhibit similar behavior in terms of politeness. Server logs show that Google doesn't spam with dozens of distinct crawlers running in parallel.
But — and this is an important point — this unification doesn't mean all crawlers explore in exactly the same way. Crawling priorities differ depending on content type. Googlebot News crawls news sites more frequently than standard Googlebot Search. [To be verified] whether this frequency difference stems from the same infrastructure or from higher-level prioritization layers.
What nuances should we add to this statement?
The infrastructure is unified, but user-agents remain distinct. Google continues to identify its crawlers with different names in logs — Googlebot, Googlebot-Image, Googlebot-News, etc. This isn't purely cosmetic: it allows selective blocking of certain content types.
Except — and here's where it gets tricky — blocking a specific crawler in robots.txt can have side effects. If you block Googlebot-Image, your images risk not appearing in Google Images, but also may no longer be indexed in standard search results where they can boost relevance.
Should we reconsider our robots.txt blocking strategies?
Probably, yes. Many sites still block certain Google crawlers reflexively or out of habit, without measuring the real impact. With unified infrastructure, these blocks can backfire.
Best practice: block only what absolutely must be blocked (duplicate content, test pages, unnecessary resources). For everything else, let Google do its job — the unified infrastructure is designed to be respectful of your server resources.
Practical impact and recommendations
What should you concretely do with your robots.txt file?
First step: audit your robots.txt to identify specific Google crawler blocks. Look for lines like "User-agent: Googlebot-Image" or "User-agent: Googlebot-News" with associated Disallow directives.
Then, ask yourself: is this block still justified? If the goal was to save bandwidth, know that the unified infrastructure already handles this intelligently. If it was to prevent indexing of sensitive images, prefer an X-Robots-Tag: noindex at the HTTP level instead.
How can you verify that Google is crawling your site correctly?
Analyze your server logs to see which user-agents Google actually uses. You should observe a diversity of crawlers (Googlebot, Googlebot-Image, etc.) with frequencies consistent with your content size and freshness.
In Google Search Console, check crawl statistics: number of pages crawled per day, download time, server responses. Unusual spikes or recurring errors may indicate a robots.txt configuration problem or server performance issue.
What mistakes should you absolutely avoid?
- Don't block Googlebot-Image if you want your images to appear in search results
- Don't block CSS and JS resources — Google needs them for rendering
- Don't use generic blocks like "User-agent: *" that would apply to all crawlers
- Don't rely on robots.txt to protect sensitive content — use authentication or noindex instead
- Don't block Google crawlers to "save crawl budget" — it's counterproductive
Google's unified infrastructure simplifies crawl management, but requires a review of blocking strategies. Prioritize transparency and let Google crawl what should be crawled — with a minimal robots.txt and targeted noindex directives for content to exclude.
These technical optimizations may seem simple in theory, but correct implementation requires detailed log analysis, understanding of indexation priorities, and regular monitoring. If you lack time or internal resources, consulting a specialized SEO agency can help you avoid costly mistakes and accelerate your visibility.
❓ Frequently Asked Questions
Bloquer Googlebot-Image empêche-t-il mes images d'apparaître dans Google Images ?
Tous les crawlers Google respectent-ils vraiment les mêmes limites de politesse ?
Peut-on encore bloquer sélectivement certains types de contenus avec robots.txt ?
L'infrastructure unifiée change-t-elle quelque chose au crawl budget ?
Faut-il modifier son robots.txt après cette annonce de Google ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 29/05/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.