Official statement
Other statements from this video 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
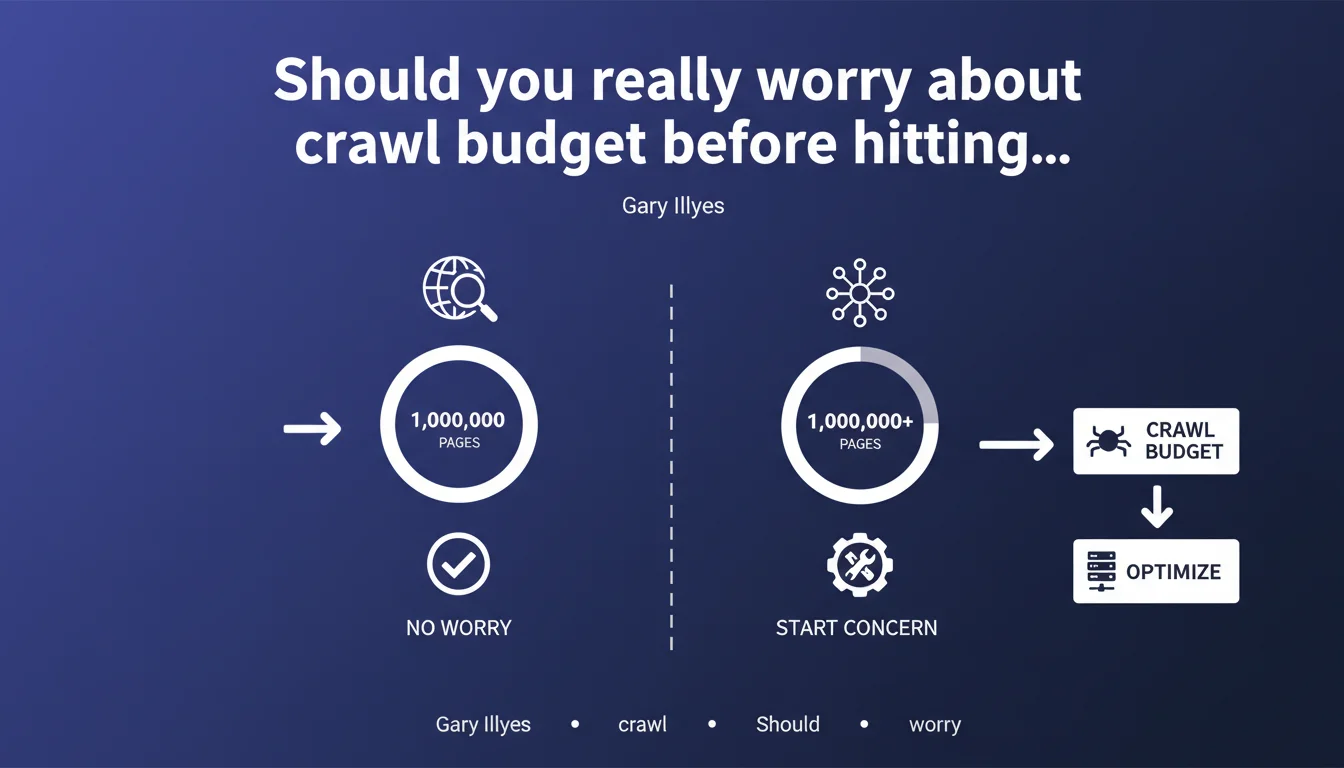
Google sets an indicative threshold of approximately 1 million pages before considering crawl budget as a priority issue for a website. Below this threshold, exploration problems typically stem from other causes — faulty architecture, orphaned links, poor content quality. This threshold is not an absolute rule, but rather a benchmark for prioritizing issues.
What you need to understand
Why does Google set this threshold at 1 million pages?
Googlebot has virtually unlimited resources to explore the web, but it optimizes the allocation of its crawl time based on the popularity and technical health of the site. A well-structured site with 500,000 pages will be crawled without friction, while a poorly designed site with 50,000 pages may encounter bottlenecks.
The 1 million threshold isn't a technical wall — it's a watchfulness zone. Beyond it, the probability that certain strategic pages will be overlooked increases if the architecture isn't optimized. Below it, if your pages aren't being indexed quickly, the problem rarely comes from crawl budget.
What really determines a website's crawl budget?
Two main factors: crawl demand (popularity, content freshness, domain authority) and crawl limit (server health, response time, HTTP errors). Google dynamically adjusts its exploration based on these variables.
A highly popular site with frequently updated content will benefit from generous crawl budget, even with 5 million pages. Conversely, a poorly ranked site with 100,000 static pages will see Googlebot spacing out its visits. The raw size of the site is just one indicator among many.
When does this threshold really become relevant?
On e-commerce platforms with automatic product variant generation, news websites with voluminous archives, or directories with millions of listings. In these contexts, crawl budget optimization becomes strategic again: blocking low-value pages, prioritizing profitable URLs.
- The 1 million page threshold is an indicative benchmark, not an absolute rule
- Below it, indexing problems rarely stem from crawl budget
- Architectural quality and popularity weigh more than raw volume
- Beyond the million mark, technical audits become essential to prevent crawl waste
SEO Expert opinion
Is this statement consistent with field observations?
Yes, broadly speaking. Audits of sites between 100,000 and 800,000 pages rarely reveal crawl deficit as the root cause of indexing problems. The real culprits: duplicate content, poorly managed pagination, failing internal links, catastrophic server response times.
However, once you surpass the million mark — particularly on platforms with uncontrolled page volume growth — the risk of having entire sections under-crawled increases mechanically. [To verify]: Google doesn't specify whether this threshold applies uniformly to all industries or varies depending on site type.
What nuances should be added to this claim?
The threshold is indicative, not normative. A very popular news site with 2 million articles may never encounter friction, while an obscure B2B directory with 300,000 listings will see Googlebot losing interest in deep pages quickly. Content freshness and domain authority matter more than raw volume.
Another bias: Gary Illyes speaks of an "individual website." What about multi-domain architectures, subdomains, geolocation-based subdirectories? This statement leaves too many gray areas for complex cases — typically media groups or international SaaS platforms.
In what cases doesn't this rule apply?
On sites with massive URL regeneration (poorly canonicalized dynamic parameters, product filters, user sessions), crawl budget can be exhausted well before reaching 1 million indexable pages. Googlebot wastes time on URLs with no SEO value, at the expense of strategic pages.
Practical impact and recommendations
What should you concretely do if your site exceeds 1 million pages?
Start with a comparative crawl audit: how many pages are actually crawled over a 30-day period via Search Console? Compare this figure to your strategic page count. If the gap is significant, identify neglected sections and causes (excessive depth, orphaned links, response time).
Next, prioritize ruthlessly: block low-value pages via robots.txt or noindex tag (old archives, redundant filters, thank-you pages). Invest in internal linking to surface strategic pages. Optimize server speed to maximize the number of pages Googlebot can crawl per session.
What mistakes should you avoid if your site is under 1 million pages?
Don't justify mediocre indexing by invoking a supposed "crawl budget shortage." Below the million mark, it's almost always a convenient excuse masking structural failures: weak content, cannibalization, missing internal links, misconfigured meta robots tags.
Also avoid obsessing over crawl budget as a vanity metric. What matters is the indexation rate of strategic pages, not raw crawl volume. A 10,000-page site that's perfectly indexed outperforms a 500,000-page site where 80% are ignored.
How do you verify your site is efficiently using its crawl budget?
In Google Search Console, under "Crawl statistics": observe the trend in pages crawled per day, server errors, average download time. If crawl volume stagnates or decreases without external cause (migration, penalty), dig into server logs to identify bottlenecks.
- Audit crawled page volume vs strategic pages in Search Console
- Block low SEO-value sections via robots.txt (filters, old archives)
- Optimize internal linking to surface priority pages
- Monitor server response time and reduce 5xx errors
- Implement a hierarchical XML sitemap by business priority
- Prevent uncontrolled dynamic URL generation (parameters, sessions)
❓ Frequently Asked Questions
Le crawl budget s'applique-t-il uniquement aux très gros sites ?
Comment savoir si mon site souffre d'un problème de crawl budget ?
Faut-il bloquer des pages pour économiser du crawl budget ?
Un sitemap XML peut-il augmenter le crawl budget ?
Les sous-domaines consomment-ils un crawl budget séparé ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 29/05/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.