Official statement
Other statements from this video 10 ▾
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
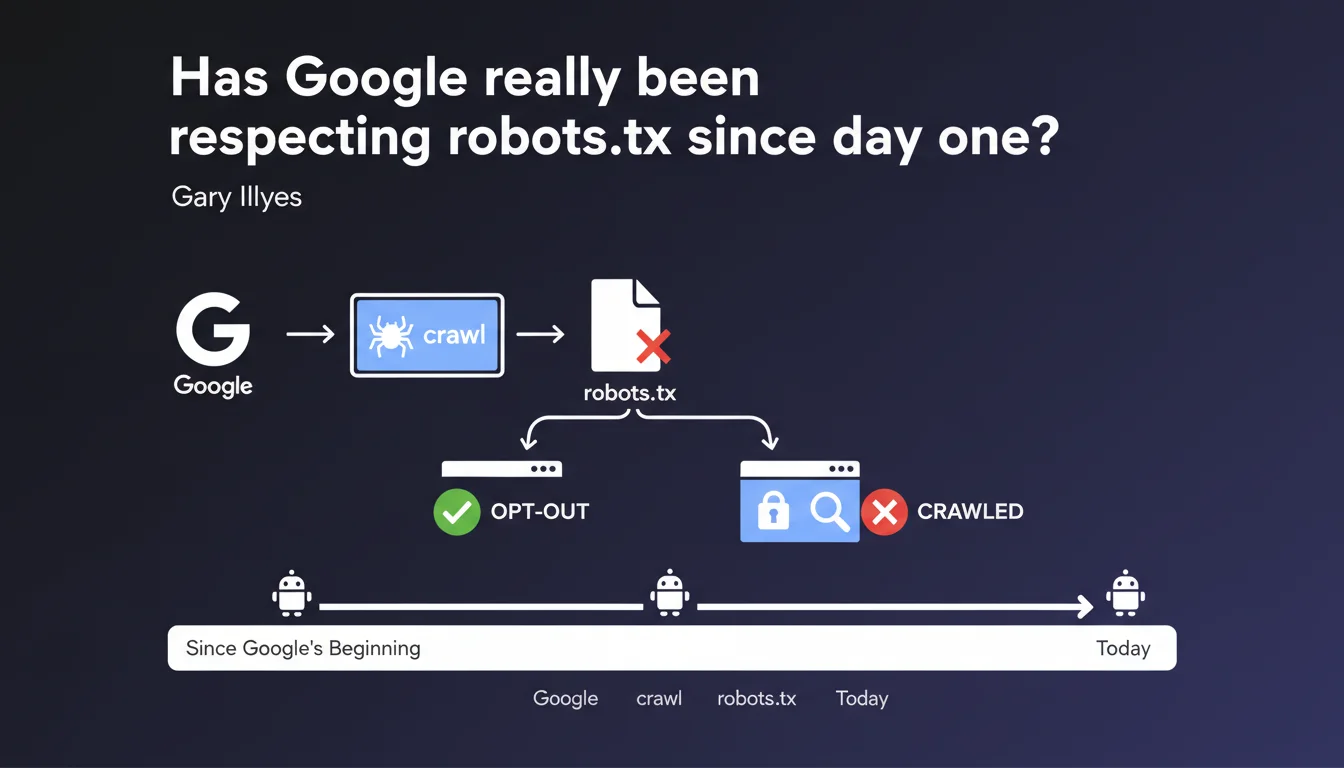
Google claims to have supported the robots.txt protocol from its launch, regardless of the crawling technology used. The Mountain View giant insists: site owners have always been able to block crawling via this file. This statement reinforces a fundamental principle often overlooked — robots.txt remains the reference method for managing crawler access.
What you need to understand
Why is Google reiterating this point today?
This statement comes at a time when some site owners are questioning the actual compliance with robots.txt by modern crawlers. Gary Illyes makes it clear: since Google's very first bot, this protocol has been honored.
The emphasis on "regardless of crawling technology" is not incidental. It aims to reassure those wondering about new AI crawlers or emerging technologies. The message is unmistakable: robots.txt remains the fundamental, non-negotiable directive.
What does "opt-out of crawling" concretely mean?
The term "opt-out" used here deserves attention. It positions robots.txt as a withdrawal mechanism, not as a suggestion. Google thus affirms that it considers this file as a firm instruction, not as a recommendation that its bots could ignore.
Be careful though: respecting robots.txt does not mean Google automatically removes blocked URLs from its index. A page can remain indexed even if it's blocked from crawling — this is a fundamental distinction that many still overlook.
What are the limitations of this statement?
The declaration remains intentionally generic. It does not specify how Google handles conflicts between directives (robots.txt vs meta robots vs X-Robots-Tag), nor the response time after file modification.
Let's be honest: saying "since the beginning" provides no information about protocol support granularity. Are all advanced directives respected equally? The statement doesn't clarify this.
- Google supports robots.txt since its launch — this is a reaffirmed historical commitment
- This support applies to all crawling technologies, old and new
- The file allows blocking crawling, but not necessarily deindexing
- The declaration remains vague on edge cases and directive conflicts
- No clarification on response time after modification
SEO Expert opinion
Is this statement consistent with field observations?
Overall, yes. SEO practitioners observe daily that Google respects the Disallow directives in robots.txt. Server logs confirm that Googlebot does not attempt to crawl blocked sections — at least not with its official crawlers.
The problem is that this statement masks significant gray areas. Some lesser-known Google crawlers (for example those related to image search or certain specialized agents) have sometimes shown less predictable behavior. [To verify]: Do all Google user-agents respect robots.txt with equal rigor?
What nuances should be added to this position?
First crucial point: blocking crawl via robots.txt does not prevent indexation. A URL can appear in search results even if Googlebot cannot access it, especially if it receives backlinks. This is counterintuitive but documented.
Second nuance — and this is where it gets tricky: respecting robots.txt does not guarantee quick deindexing of already-crawled pages. If you suddenly block a section, Google will retain the data already collected until it becomes obsolete in its system. How long? No official data specifies this.
In what contexts does this rule show its limitations?
Heavy JavaScript sites sometimes pose problems. If your robots.txt blocks the CSS/JS resources needed for rendering, Google may interpret this as an attempt at cloaking — even unintentionally. The official recommendation is to stop blocking these resources, but some sites maintain these restrictions.
Another edge case: AI crawlers for model training. Google affirms that robots.txt applies, but we lack transparency on the use of data already legitimately crawled before a site blocks these accesses. The legal and technical debate is far from settled.
Practical impact and recommendations
What should you verify immediately in your robots.txt?
First instinct: audit your robots.txt file with Search Console. The integrated test tool shows you exactly how Googlebot interprets your directives. Don't rely solely on your own reading — syntax matters enormously.
Check that you're not accidentally blocking critical sections for SEO: category pages, strategic product sheets, pillar content. Syntax errors (extra spaces, misplaced wildcards) can have catastrophic consequences.
What critical mistakes must you absolutely avoid?
Never block your CSS, JavaScript, and image resources via robots.txt — Google needs them for rendering and evaluation of your pages. This practice, common a few years ago, is now counterproductive.
Watch out for robots.txt files automatically generated by certain CMS or plugins. They often contain obsolete or overly restrictive rules. Manually examine each directive, especially after a migration or platform change.
Classic mistake: using robots.txt to block duplicate content. Bad strategy. Prefer canonicals, meta noindex tags, or URL parameters in Search Console. robots.txt is not the right tool for managing duplication.
How do you implement a robust robots.txt strategy?
Start by clearly defining what should be crawled and what shouldn't. Document your choices in a reference file — your robots.txt must reflect an intentional strategy, not historical patchwork.
Monitor your server logs regularly. They reveal whether Googlebot attempts to access blocked URLs (which would indicate a syntax problem) or if it crawls excessive amounts of allowed sections. This analysis remains the best way to validate that your directives are actually being respected.
- Test your robots.txt with the Search Console tool after each modification
- Never block CSS, JS, and images — Google needs them for rendering
- Clearly distinguish between crawling and indexation in your strategy
- Use noindex to deindex, not robots.txt alone
- Monitor your logs to confirm actual Googlebot behavior
- Document your blocking choices — they must be intentional
- Review the file after any migration or technical overhaul
❓ Frequently Asked Questions
Le robots.txt empêche-t-il l'indexation d'une page ?
Combien de temps faut-il pour que Google prenne en compte une modification du robots.txt ?
Peut-on bloquer uniquement certains crawlers Google via robots.txt ?
Faut-il bloquer les paramètres d'URL via robots.txt ?
Le respect du robots.txt s'applique-t-il aux crawlers d'IA de Google ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 29/05/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.