Official statement
Other statements from this video 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Le crawl de Google consomme-t-il vraiment le plus de ressources serveur ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
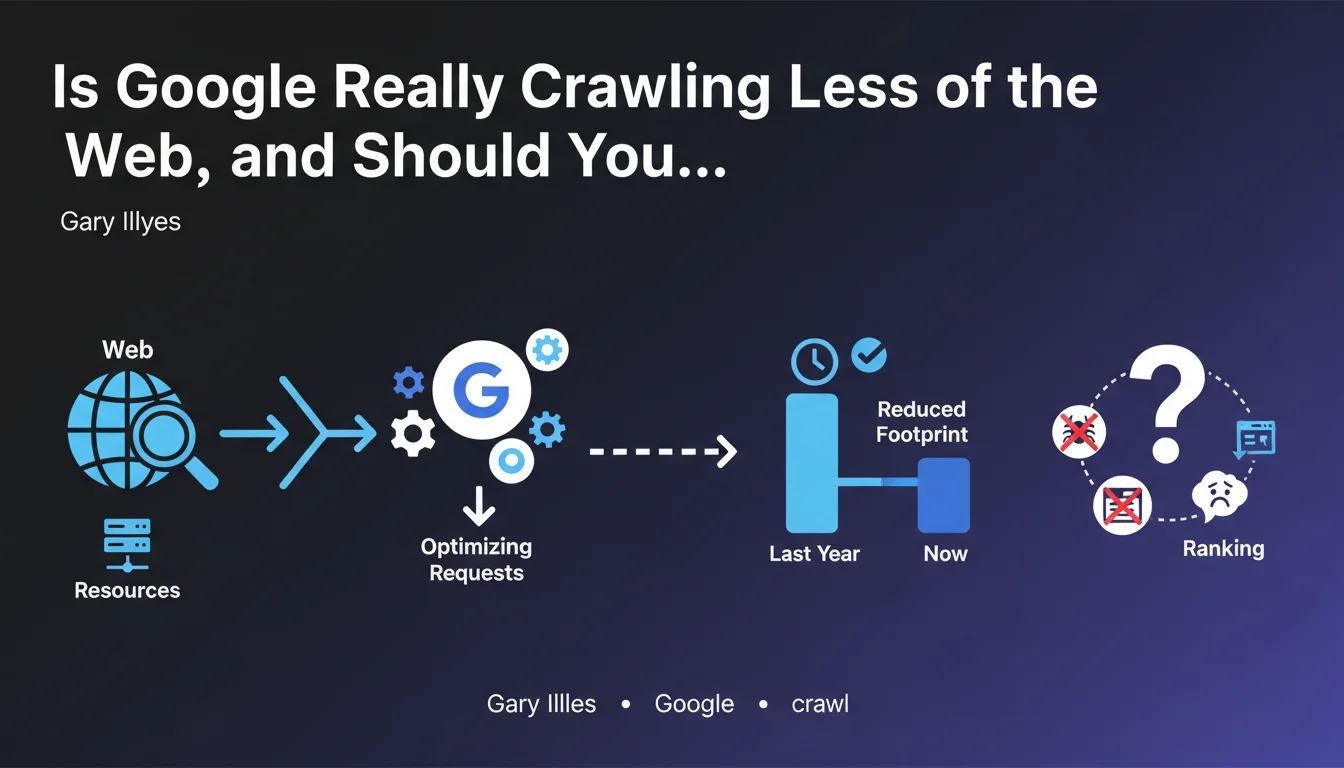
Google has optimized its crawling requests to reduce its footprint on the internet and conserve resources. In practical terms, Googlebot visits fewer pages, which directly impacts sites with limited crawl budgets. This shift raises strategic questions about technical optimization for maintaining visibility in search results.
What you need to understand
What does "reducing crawl footprint" actually mean?
Google has chosen to limit the number of requests its robots make to web servers. The official objective: to conserve resources, likely both on Google's side (infrastructure, energy) and on publishers' side (server load).
This reduction doesn't necessarily mean your site will be crawled less — unless you're among sites with a constrained crawl budget. However, Google is prioritizing even more strictly the pages it chooses to explore.
Which sites are most affected by this restriction?
Large sites with thousands of pages (e-commerce, media outlets, directories) are on the front line. If you regularly publish content or auto-generate pages, this optimization could slow down the indexing of your new URLs.
Small sites (with just dozens of pages) will likely see no impact. Their crawl budget was never a structural problem to begin with.
Does Google Share Specific Numbers About This Reduction?
No. And that's where the problem lies. The announcement remains deliberately vague: no data on the extent of the reduction, no shared metrics, no detailed timeline.
We don't know if crawl decreased by 5% or 40%. It's impossible to quantify the real impact without monitoring your own server logs.
- Google prioritizes more strictly which pages to crawl
- Large sites with limited crawl budgets are the first to be affected
- No official quantified data has been shared
- Monitoring your logs becomes even more strategic
SEO Expert opinion
Is This Announcement Consistent With What SEOs Are Seeing in the Real World?
Yes, very much so. For several months now, many SEO professionals have reported a decline in crawl rates on large e-commerce sites. New pages take longer to be discovered, and deep pages are visited less frequently.
What's interesting is that Google frames this as a virtuous optimization — resource conservation, digital sustainability. Let's be honest: it's also a way to manage the explosion of web content while keeping infrastructure costs under control.
What Nuances Should We Add to This Announcement?
[To be verified] Google talks about "optimizing requests," but doesn't detail the prioritization criteria. Does the perceived quality of a site play a larger role? Content freshness? User engagement?
The lack of transparency makes strategic adjustment difficult. We assume that classic signals (links, authority, performance) weigh even more heavily, but nothing is confirmed.
Another unclear point: does this reduction apply uniformly across all content types, or do certain verticals (news, for example) remain privileged? No indication whatsoever.
In Which Cases Does This Restriction Not Apply?
If your site is small, well-structured, and technically clean, you'll likely notice nothing. Crawl budget was never your bottleneck.
On the other hand, if you have hundreds of thousands of pages, infinite facets, uncontrolled duplications, or a chaotic information architecture, this optimization will amplify your existing problems. Google won't make the effort to compensate for your technical weaknesses anymore.
Practical impact and recommendations
What Should You Do Concretely to Adapt?
First step: monitor your server logs. Without precise data on your crawl evolution, you're flying blind. Use tools like Oncrawl, Botify, or custom solutions to track Googlebot activity.
Next, prioritize ruthlessly. Identify your strategic pages (those that generate traffic, conversions, revenue) and make sure they remain accessible within 1-2 clicks from the homepage. Internal linking becomes even more critical.
What Mistakes Should You Avoid at All Costs?
Don't let Google crawl worthless pages: useless facets, redundant URL parameters, infinite pagination, duplicate content. Every request wasted on low-quality content reduces the chances that your real pages get explored.
Also avoid blocking critical resources (CSS, JS) if they influence rendering. Google crawls less, but it still wants to understand your pages. Don't make it harder for the bot.
How Can You Verify Your Site Remains Performant Despite This Restriction?
Compare the indexation rate of your new pages before and after this optimization. If a published page now takes 10 days to be indexed instead of 2, that's a red flag.
Also check the crawl depth: does Googlebot still explore your deep pages, or does it stop sooner in your information architecture?
- Install a server log analysis tool to track Googlebot activity
- Audit your architecture and eliminate pages with no SEO value
- Strengthen internal linking to strategic pages
- Optimize server response times to maximize every crawl
- Monitor the indexation delay of newly published pages
- Clean up redundant facets and URL parameters
- Submit priority URLs via the Indexing API (if eligible)
❓ Frequently Asked Questions
Mon petit site de 50 pages est-il concerné par cette réduction du crawl ?
Comment savoir si mon site est moins crawlé qu'avant ?
Google a-t-il communiqué les critères de priorisation du crawl ?
Faut-il bloquer certaines pages dans le robots.txt pour économiser le crawl budget ?
L'API Indexing peut-elle compenser cette réduction du crawl ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 29/05/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.