Official statement
Other statements from this video 10 ▾
- □ Le robots.txt a-t-il toujours été respecté par Google depuis sa création ?
- □ Pourquoi tous les crawlers Google utilisent-ils la même infrastructure de crawl ?
- □ Google ralentit-il vraiment son crawl pour protéger vos serveurs ?
- □ Pourquoi Google a-t-il multiplié ses crawlers depuis l'arrivée de Mediapartners-Google ?
- □ Pourquoi Google ignore-t-il robots.txt pour les actions utilisateur ?
- □ L'outil de test en direct de Search Console crawle-t-il vraiment votre site ?
- □ Googlebot supporte-t-il HTTP/3 pour crawler votre site ?
- □ Pourquoi Google réduit-il drastiquement son empreinte de crawl sur le web ?
- □ Faut-il vraiment s'inquiéter du crawl budget avant 1 million de pages ?
- □ Pourquoi la charge serveur de Googlebot varie-t-elle autant selon votre architecture technique ?
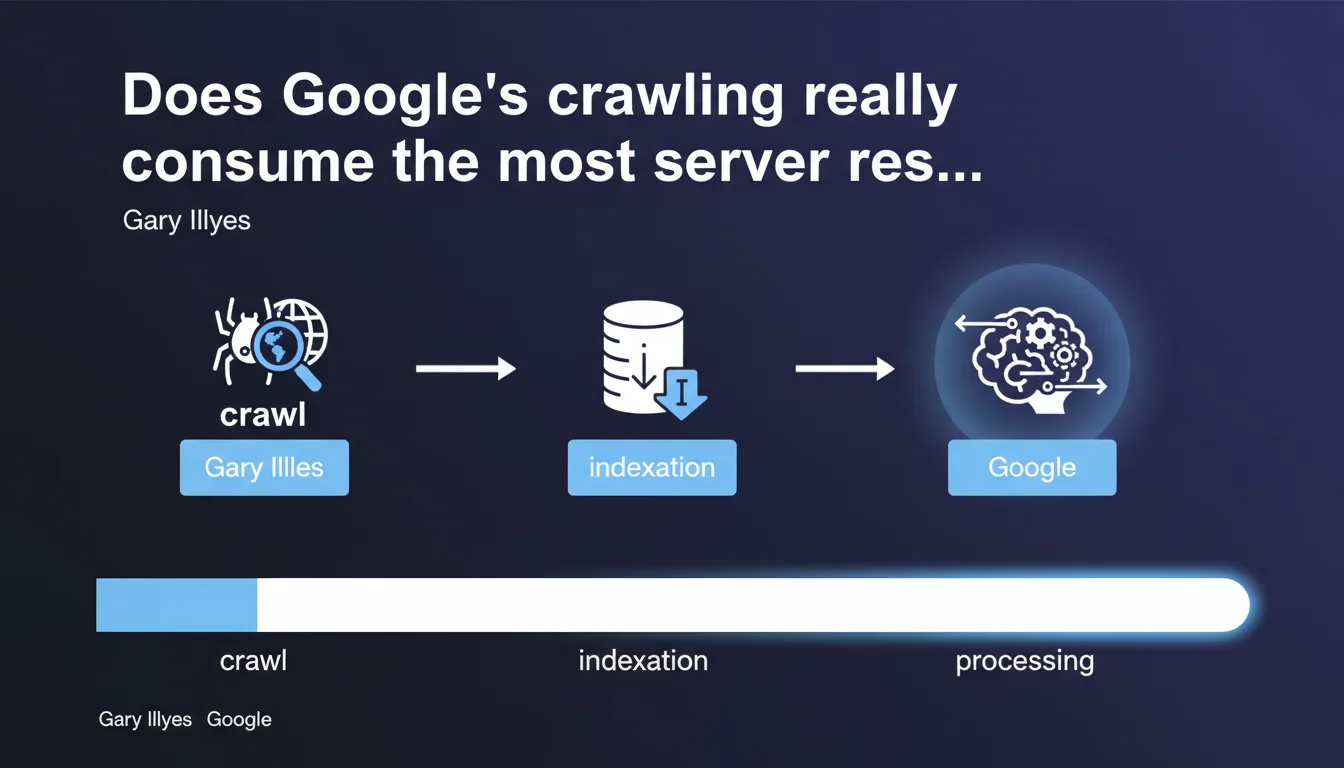
Gary Illyes debunks a common misconception: it's not crawling that consumes Google's resources, but indexation and data processing. A crucial nuance for understanding where the real bottlenecks lie on the search engine side — and why optimizing your crawl budget might not be your absolute priority.
What you need to understand
What actually consumes the most resources on Google's side?
Gary Illyes asserts that crawling is not the most expensive operation in Google's processing pipeline. It's indexation and data processing that mobilize the most computing power.
Concretely? Fetching the HTML of a page is relatively lightweight. However, analyzing that content, extracting entities, calculating relevance scores, managing internal and external links, applying quality filters — that's a whole different ballgame.
Why does this distinction change how we view crawl budget?
For years, SEO has focused on crawl budget as a major concern. The idea: Google has limited resources to crawl your site, so you'd better optimize so it doesn't waste time on useless pages.
Except if crawling isn't the real bottleneck, this obsession might be misplaced. It's not that optimizing crawl is useless — but it might not be where your indexation battle is fought if you have a medium-sized site.
What does this mean for large websites?
For massive sites (millions of pages), crawling remains a concern — Google will never crawl everything, even if it's technically lightweight. But the real constraint is indexation: how many pages can Google actually process and store in its index?
This statement suggests that even if Google crawls your page, nothing guarantees it will be indexed correctly or quickly. Post-crawl processing can take time, especially if your content requires complex analysis or if your site generates conflicting signals.
- Crawling is relatively inexpensive for Google
- Indexation and data processing are the real resource-intensive operations
- Optimizing crawl remains relevant, but it's not the only lever to improve indexation
- For large sites, the real challenge is the quality of content to index, not just its availability for crawling
SEO Expert opinion
Does this statement contradict what we observe in the field?
Not really. We've long known that Google doesn't crawl everything it indexes (think aggregated social feeds) and doesn't index everything it crawls. But this statement reorients priorities.
In practice, we observe that heavily crawled sites can have indexation issues — and conversely, sites with minimal crawling can have excellent indexation rates if the content is relevant and well-structured. Crawling is just one step, and Gary Illyes reminds us it's not the most critical one from a resource perspective.
What nuances should we add to this statement?
Even if crawling consumes few resources on Google's end, it can consume a lot on yours. An aggressive bot can saturate your server, especially if your infrastructure is fragile or if you generate costly dynamic content.
So yes, optimizing crawl remains relevant — but to protect your own resources, not Google's. [To verify]: Gary Illyes doesn't specify how Google arbitrates between sites when its indexation capacity is saturated — quality criteria, freshness, authority?
When doesn't this rule apply?
If your site generates massively duplicated content or very low-quality content, Google can limit crawling before even reaching the indexation phase. In that case, crawling becomes a bottleneck — but it's a consequence, not the root cause.
Practical impact and recommendations
What should you do concretely to optimize indexation?
First step: facilitate post-crawl processing. This means clean HTML structure, consistent structured data, clear internal linking. The easier your content is to analyze, the fewer resources Google spends on it.
Second approach: reduce noise. If you send Google 10,000 pages where 8,000 are near-duplicates or thin content, you saturate its indexation pipeline for nothing. Better to have 2,000 solid pages than 10,000 mediocre ones.
What mistakes should you avoid given this reality?
Stop believing that artificially increasing crawl will mechanically boost your indexation. If Google crawls your pages but doesn't index them, the problem is elsewhere: content quality, duplication, cannibalization, conflicting signals.
Another classic mistake: neglecting server-side processing speed under the pretext that Google doesn't care. Wrong. A slow server slows down crawling, thus delays indexation — even if crawling itself isn't resource-intensive for Google.
How do you verify your site is optimized for indexation?
Analyze your actual indexation rate via Search Console: how many pages crawled vs pages indexed? A significant gap signals a quality or processing problem, not necessarily a crawl issue.
Also check crawl depth and average server response time. If Google takes 2 seconds to fetch a page, even if crawling is lightweight for it, it slows down the whole process.
- Structure your HTML cleanly and use structured data to facilitate processing
- Eliminate low-quality or duplicate pages to avoid saturating the indexation pipeline
- Monitor your indexation rate in Search Console, not just crawl stats
- Optimize server response time to speed up crawling (even if Google isn't limited by it)
- Focus on content quality rather than the quantity of crawlable pages
❓ Frequently Asked Questions
Le crawl budget est-il toujours un concept pertinent si le crawl consomme peu de ressources ?
Si l'indexation est plus coûteuse, Google peut-il refuser d'indexer certaines pages pour économiser des ressources ?
Faut-il privilégier l'optimisation du crawl ou celle de l'indexation ?
Cette déclaration change-t-elle la façon dont on doit gérer un site de plusieurs millions de pages ?
Google communique-t-il clairement sur les critères qui rendent l'indexation coûteuse ?
🎥 From the same video 10
Other SEO insights extracted from this same Google Search Central video · published on 29/05/2025
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.