Declaration officielle
Ce qu'il faut comprendre
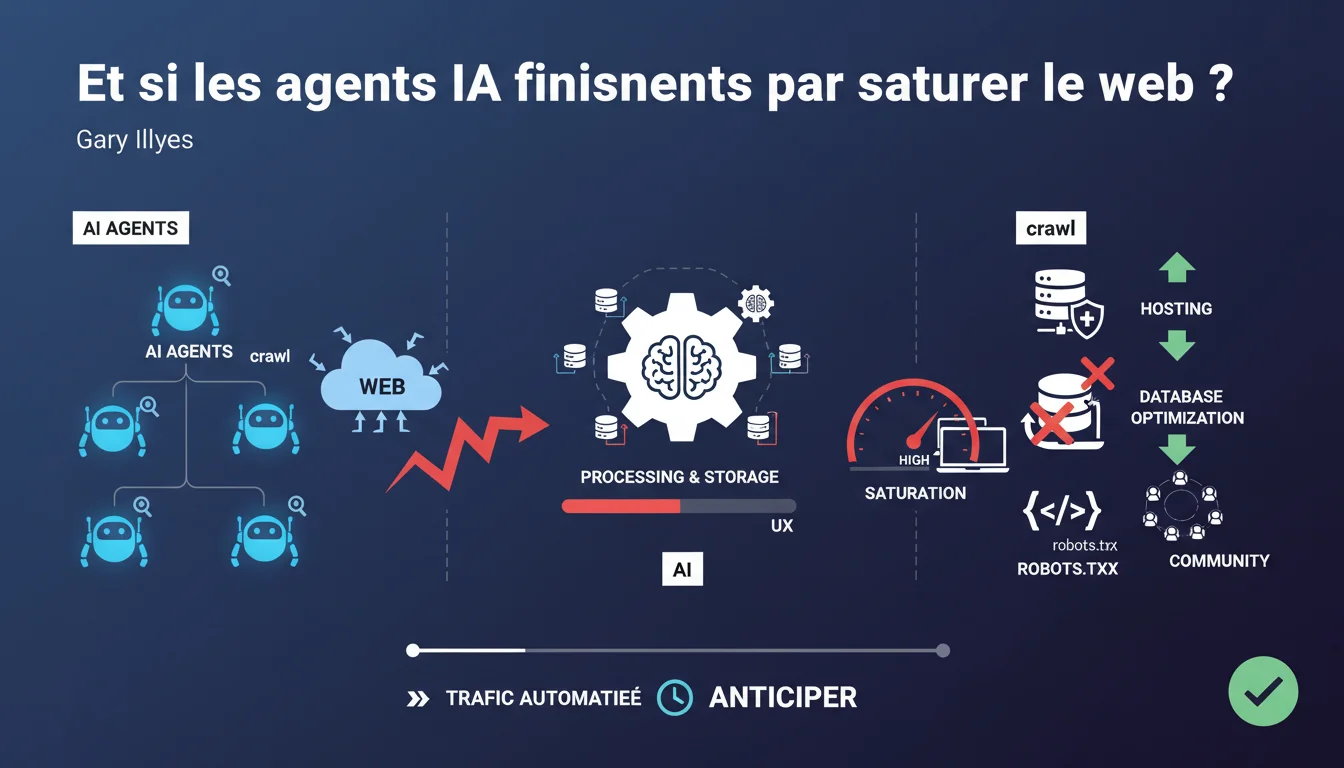
Google alerte sur un phénomène émergent : l'explosion du trafic des bots pilotés par l'IA. Ces agents automatisés ne se contentent plus de crawler occasionnellement, ils explorent massivement le web pour alimenter les modèles d'intelligence artificielle.
Contrairement aux idées reçues, ce n'est pas tant le crawl lui-même qui pose problème, mais le traitement et le stockage des données qu'il génère. Ces opérations sollicitent intensément les ressources serveur et peuvent rapidement submerger les infrastructures non préparées.
Cette vague de trafic automatisé nécessite une anticipation technique de la part des propriétaires de sites. Sans adaptation, les sites risquent des ralentissements, des temps de réponse dégradés, voire des interruptions de service.
- Le crawl IA diffère du crawl traditionnel par son intensité et sa fréquence
- Les ressources critiques sont le traitement et le stockage, pas la bande passante
- Le fichier robots.txt devient un outil stratégique de régulation
- L'infrastructure d'hébergement doit être réévaluée à la hausse
- Des solutions collectives comme Common Crawl peuvent mutualiser la charge
Avis d'un expert SEO
Cette alerte est parfaitement cohérente avec les observations terrain. Depuis 2023, les logs serveur montrent une multiplication par 5 à 10 du trafic provenant d'agents IA (GPTBot, Claude-Bot, Perplexity, etc.). Les sites avec des bases de données mal optimisées connaissent déjà des dégradations de performance.
Une nuance importante : tous les sites ne sont pas égaux face à ce risque. Les sites riches en contenu textuel (blogs, médias, documentation) sont particulièrement ciblés. En revanche, les sites applicatifs ou les e-commerces avec peu de contenu exploitable sont moins exposés.
La recommandation sur Common Crawl est particulièrement pertinente : permettre un crawl mutualisé plutôt que de subir des dizaines de bots indépendants réduit mécaniquement la charge. C'est une approche gagnant-gagnant encore sous-exploitée.
Impact pratique et recommandations
- Auditez vos logs serveur pour identifier le volume réel de trafic bot IA actuellement reçu
- Évaluez votre infrastructure d'hébergement : CPU, RAM, et surtout capacité de traitement de votre base de données
- Optimisez vos requêtes SQL et indexez correctement vos tables pour réduire les temps de traitement
- Mettez en place un système de cache robuste (Varnish, Redis) pour limiter les accès directs à la base
- Révisez votre fichier robots.txt : définissez des règles spécifiques pour chaque bot IA (crawl-delay, sections interdites)
- Surveillez les métriques Core Web Vitals qui peuvent se dégrader sous la pression du trafic automatisé
- Considérez un CDN avec protection DDoS pour absorber les pics de trafic bot
- Documentez votre politique de crawl et communiquez-la clairement (page dédiée /ai-crawling-policy)
- Testez régulièrement la charge serveur en simulant des pics de requêtes
- Évaluez l'opportunité de contribuer ou utiliser Common Crawl pour mutualiser l'effort
💬 Commentaires (0)
Soyez le premier à commenter.