Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Google privilégie-t-il vraiment les pages de qualité dans son crawl ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ La qualité d'une page détermine-t-elle vraiment le crawl des pages suivantes ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
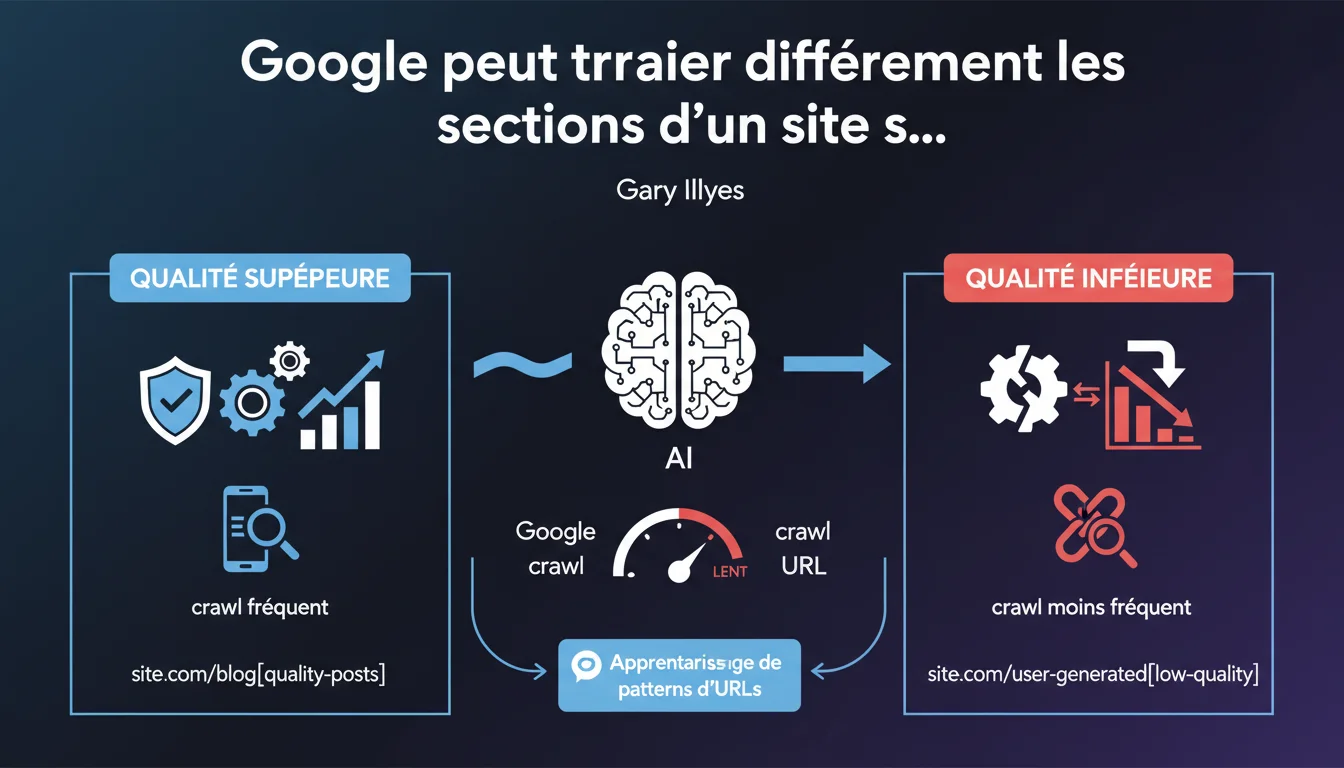
Google adapte son traitement algorithmique section par section au sein d'un même site. Si certains patterns d'URLs montrent systématiquement du contenu de moindre qualité — typiquement les zones UGC mal modérées — le moteur ajuste crawl, indexation et probablement ranking en conséquence. La qualité n'est donc plus évaluée uniquement au niveau du domaine, mais aussi par sous-ensembles thématiques ou fonctionnels.
Ce qu'il faut comprendre
Google analyse-t-il vraiment votre site section par section ?
Oui, et c'est un changement majeur dans la manière dont on pense l'architecture. Pendant longtemps, on raisonnait en termes de domaine autoritaire : un bon site portait ses pages faibles. La déclaration de Gary Illyes confirme que Google identifie des patterns d'URLs — forums, commentaires, listings auto-générés — et leur applique un traitement différencié.
Concrètement ? Si /forum/* affiche du spam à répétition, Google peut décider de crawler cette section moins souvent, voire de ne pas indexer certaines pages, même si le reste du site brille. Le moteur apprend : il détecte des signaux récurrents (taux de rebond, faible engagement, contenu dupliqué) et en tire des conclusions structurelles.
Quels types de sections sont concernés en priorité ?
Les contenus générés par les utilisateurs (UGC) arrivent en tête de liste : forums, commentaires, avis non modérés, Q&A communautaires. Ensuite, les pages auto-générées à faible valeur ajoutée — facettes infinies, tags croisés, archives chronologiques sans contenu unique.
Mais ça ne s'arrête pas là. Des sections entières de produits obsolètes, des landing pages génériques créées en masse pour du long tail, des blogs corporate remplis de communiqués de presse... tout ça peut tomber sous le radar négatif de Google si la qualité n'y est pas.
Qu'est-ce qui déclenche ce traitement différencié ?
Google ne donne pas de seuil précis — évidemment — mais plusieurs signaux entrent probablement en jeu. D'abord, la cohérence qualitative : si 80 % des URLs d'un pattern donné génèrent peu d'interactions, peu de backlinks, beaucoup de pogo-sticking, l'algorithme tire des conclusions.
Ensuite, la densité de contenu faible : pages courtes, absence de structure sémantique, duplication interne. Enfin, les signaux comportementaux — même si Google minimise toujours leur poids officiel, un pattern d'URLs systématiquement boudé par les utilisateurs finit par envoyer un message clair.
- Google segmente les sites en patterns d'URLs et leur applique un traitement distinct selon la qualité observée
- Les sections UGC mal modérées sont les premières concernées, mais toute zone de faible qualité peut être impactée
- Le crawl, l'indexation et probablement le ranking sont ajustés section par section — pas seulement au niveau du domaine
- L'algorithme apprend des signaux récurrents : engagement faible, contenu dupliqué, absence de backlinks naturels
Avis d'un expert SEO
Cette déclaration correspond-elle à ce qu'on observe sur le terrain ?
Oui, et depuis un moment déjà. Les audits de crawl montrent régulièrement des sections entières d'un site crawlées une fois par mois, pendant que d'autres le sont quotidiennement. Ce n'est pas du hasard. Google alloue son budget de crawl en fonction de la valeur perçue — et la qualité sectorielle pèse lourd dans cette équation.
On voit aussi des sites où certaines sections n'apparaissent presque jamais dans les SERPs, même avec des requêtes de marque précises. Ce n'est pas du noindex — c'est du désindexation molle, où Google indexe techniquement mais ne montre jamais les pages. Ça colle parfaitement avec ce que décrit Illyes.
Quelles nuances faut-il apporter à cette affirmation ?
Première nuance : Google ne dit pas explicitement que ça impacte le ranking — seulement le crawl. Mais soyons honnêtes, si une section est crawlée moins souvent, elle mettra plus de temps à être indexée, et aura moins de chances de se positionner. L'effet cascade est évident.
Deuxième point : le terme « moindre qualité » reste vague. Google ne précise ni seuil, ni métrique. Est-ce que 30 % de pages faibles suffisent à condamner une section ? 50 % ? 80 % ? Aucune réponse. [A vérifier] sur vos propres données via Search Console et logs serveur.
Troisième élément — et c'est crucial — cette logique peut se retourner contre vous si vous isolez mal vos contenus. Si Google confond une section UGC avec votre blog éditorial parce que l'arborescence est floue, il peut pénaliser l'ensemble. L'architecture devient donc un enjeu de survie SEO, pas juste une question d'ergonomie.
Dans quels cas cette règle pourrait-elle ne pas s'appliquer ?
Sur les très gros sites autoritaires avec un historique solide, Google semble plus tolérant. Un forum Reddit peut contenir des millions de pages de faible qualité — ça n'empêche pas le domaine de ranker massivement. La notoriété et les backlinks de qualité créent une forme de tampon.
Autre cas : les sites dont les sections faibles sont tellement marginales qu'elles ne pèsent pas statistiquement. Si vous avez 10 000 pages produits excellentes et 50 vieux articles de blog pourris, Google ne va pas dégrader l'ensemble du site. Mais si les proportions s'inversent, attention.
Impact pratique et recommandations
Que faut-il faire concrètement pour protéger les sections fragiles ?
D'abord, identifier les patterns d'URLs à risque. Analysez vos logs serveur et Search Console : quelles sections sont crawlées peu souvent ? Lesquelles génèrent peu de clics organiques ? Croisez avec vos métriques d'engagement (temps sur page, taux de rebond) pour repérer les zones problématiques.
Ensuite, décidez du sort de chaque section. Trois options : améliorer la qualité (modération UGC, enrichissement éditorial, refonte), bloquer le crawl (robots.txt, noindex) si le contenu n'a aucune valeur SEO, ou carrément supprimer si c'est du poids mort. Ne gardez pas une section juste parce qu'elle existe depuis 10 ans.
Enfin, séparez clairement dans votre arborescence les sections de qualité variable. Si votre blog corporate (/actualites/) côtoie un forum utilisateur, isolez ce dernier dans /communaute/ avec une architecture distincte. Ça limite le risque de contamination algorithmique.
Quelles erreurs éviter absolument ?
Erreur numéro un : laisser traîner des milliers de pages UGC spam « au cas où ». Google n'a aucune pitié pour le contenu zombie. Si une page n'apporte rien — ni trafic, ni backlinks, ni conversion — elle nuit plus qu'elle n'aide.
Erreur deux : créer des facettes ou tags à l'infini sans contrôle éditorial. Chaque nouvelle combinaison de filtres génère une URL — et si 90 % de ces URLs affichent 3 produits génériques, vous venez de signaler à Google une section de faible qualité. Limitez les combinaisons indexables ou ajoutez du contenu unique par facette.
Erreur trois : ignorer les signaux de crawl. Si Googlebot évite une section pendant des mois, ce n'est pas un bug — c'est un message. Ne forcez pas l'indexation via sitemap XML sans avoir d'abord résolu le problème de fond.
Comment vérifier que mon site n'est pas déjà impacté ?
Analysez vos logs serveur sur 3 mois minimum. Segmentez par pattern d'URLs et comparez la fréquence de crawl. Si certaines sections sont visitées 10 fois moins souvent que d'autres, creusez. Vérifiez ensuite dans Search Console les pages indexées vs soumises : un écart important signale souvent un problème qualitatif.
Testez aussi manuellement : lancez des requêtes site:votredomaine.com/section-suspecte/ dans Google. Si les résultats sont dérisoires alors que des centaines de pages existent, c'est mauvais signe. Enfin, surveillez l'évolution du trafic organique par section dans Analytics — une chute progressive sans raison externe visible indique souvent un traitement algorithmique différencié.
- Auditer les logs serveur et Search Console pour identifier les sections sous-crawlées ou sous-indexées
- Nettoyer ou bloquer les contenus UGC de faible qualité (spam, duplicata, pages vides)
- Limiter les facettes et tags indexables aux seules combinaisons à forte valeur ajoutée
- Séparer architecturalement les sections de qualité variable (URLs distinctes, silos clairs)
- Monitorer régulièrement le crawl par pattern d'URLs pour détecter les dégradations
- Enrichir les sections fragiles avec du contenu éditorial structuré ou les désindexer totalement
❓ Questions frequentes
Google peut-il vraiment dégrader tout un domaine à cause d'une seule section de mauvaise qualité ?
Faut-il systématiquement bloquer l'indexation des contenus UGC ?
Comment savoir si Google traite différemment certaines sections de mon site ?
Est-ce que cette logique s'applique aussi aux sous-domaines ?
Améliorer progressivement une section dégradée peut-il inverser la tendance ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 19/09/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.