Official statement
Other statements from this video 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Google privilégie-t-il vraiment les pages de qualité dans son crawl ?
- □ La qualité d'une page détermine-t-elle vraiment le crawl des pages suivantes ?
- □ Google peut-il vraiment pénaliser certaines sections de votre site en fonction de leur qualité ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
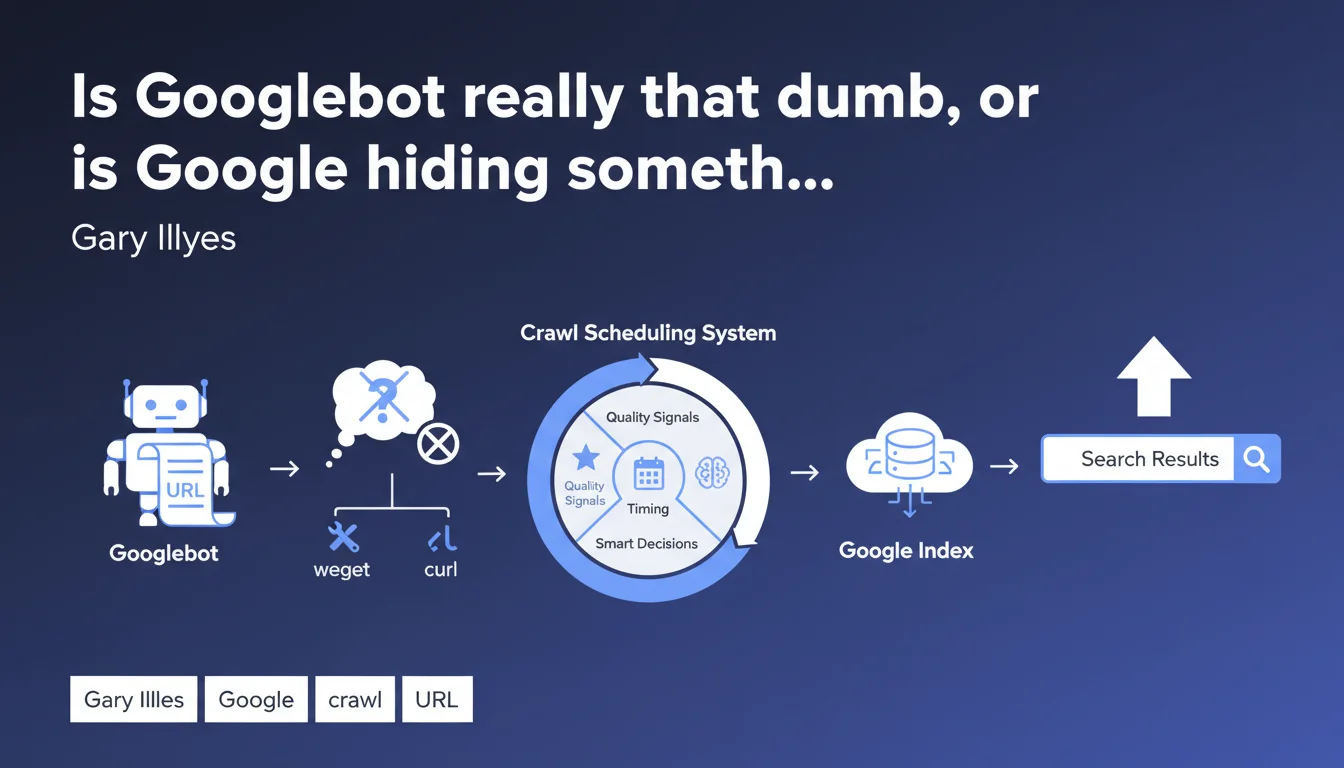
Googlebot is just a simple page fetcher with no embedded intelligence — it's the crawl scheduler that makes the smart decisions about what to explore and when, based on quality signals. This distinction fundamentally changes how you should optimize crawl budget and communicate with Google.
What you need to understand
What's the actual difference between Googlebot and the crawl scheduler?
Gary Illyes drives home a crucial point: Googlebot is just an executor, like wget or curl. It makes no decisions. It receives a URL, fetches it, passes the content along, then waits for the next instruction.
The scheduling system, on the other hand, analyzes site quality upfront, expected content freshness, page modification history, available server resources. This scheduler decides whether a given page deserves to be crawled today, tomorrow, or never.
Why does this distinction matter for SEO?
We often spend time optimizing for Googlebot — improving response times, reducing server load, tweaking robots.txt. But if the scheduler decides upfront that your site isn't worth frequent crawling, these technical optimizations become secondary.
The real battle happens over quality signals: domain authority, perceived content freshness, user engagement. The scheduler prioritizes crawl resources based on these metrics — not solely on technical criteria.
What specific criteria does the scheduler actually use?
Google stays intentionally vague. Illyes mentions "quality" without detailing precise variables. Based on field observations and published patents, we can identify several likely factors:
- Site popularity: high-authority sites = more frequent and deeper crawling
- Update frequency: if your pages change often and Google notices it, it returns more regularly
- Page speed and server stability: a crashing server slows the scheduler, which allocates fewer resources
- User engagement: pages with strong organic traffic = relevance signal for the scheduler
- Internal and external links: a well-linked page will be prioritized more
SEO Expert opinion
Does this statement match what we actually observe in the field?
Yes. For years, we've seen technically flawless sites — ultra-fast servers, perfect robots.txt, immaculate sitemaps — experience sporadic crawling. Meanwhile, moderately optimized sites with strong authority and regularly updated content get crawled multiple times per day.
What Illyes confirms is that the battle happens before crawling. If the scheduler considers your site low-priority, Googlebot will visit less frequently, regardless of your technical optimizations. Conversely, a strategically important site gets preferential treatment even with minor technical weaknesses.
What nuances should we add to this simplified view?
First point: saying Googlebot is "dumb" oversimplifies things. It doesn't have decision-making intelligence, but it does pack Chrome's rendering engine, executes JavaScript, handles resources blocked by robots.txt differently based on criticality. It's not just wget.
Second nuance: the scheduler doesn't operate in isolation. It receives feedback from Googlebot — HTTP codes, response times, error rates — and adjusts its decisions accordingly. The line between "dumb executor" and "intelligent system" is more porous than it seems.
When does this distinction actually change things?
On large-scale sites with high volume (e-commerce, media, marketplaces), crawl budget management becomes strategic. If you add 100,000 new pages at once, the scheduler won't crawl them all immediately — it prioritizes based on perceived section quality, crawl history, page depth.
For a 20-page brochure site? This distinction barely matters. Google will crawl your entire site regularly without effort. The real question then becomes content quality and external signals, not crawl optimization.
Practical impact and recommendations
What should you actually do to influence the crawl scheduler?
Forget the idea of "forcing" Googlebot to crawl more. You're not negotiating with a bot, but with an algorithm evaluating your strategic value. Priority: send quality and freshness signals.
Update your most strategic content regularly. The scheduler detects modification patterns — if a category or content hub evolves frequently, it allocates more resources there. Conversely, a page that never changes gets visited less and less often.
- Identify your strategic pages (high traffic, conversions, authority) and update them regularly, even with minor tweaks showing the content is alive
- Improve your internal linking: a page well-linked from important hubs gets crawled more frequently
- Monitor server health: a high 5xx error rate can drastically tank the crawl frequency allocated by the scheduler
- Use sitemaps intelligently: signal recently modified pages with accurate
<lastmod>tags to help the scheduler prioritize - Block via robots.txt sections with no SEO value (infinite facets, internal search pages) so the scheduler concentrates resources on what matters
What mistakes should you absolutely avoid?
Don't multiply low-quality pages hoping to saturate crawling. The scheduler detects these patterns — sites stuffed with duplicate content, auto-generated pages with no value — and reduces overall crawl allocation for the domain.
Also avoid blocking critical resources (CSS, JS) via robots.txt thinking you'll save crawl budget. This prevents Googlebot from properly rendering the page, signaling negatively to the scheduler. Better to leave these resources accessible.
How do you verify your strategy is working?
Check the Crawl Stats report in Google Search Console regularly. Watch the evolution of daily crawled pages, average download time, activity peaks. If your optimizations work, you should see progressive increases in crawling on strategic sections.
Also compare crawl frequency between sections: are your content hubs visited more often than secondary pages? If not, your internal linking or update strategy probably needs adjustment.
❓ Frequently Asked Questions
Le planificateur de crawl est-il le même pour tous les sites ?
Puis-je demander à Google de crawler plus souvent mon site ?
Un serveur rapide garantit-il un meilleur crawl budget ?
Faut-il bloquer des sections entières pour économiser du crawl budget ?
Comment savoir si mon site souffre d'un problème de crawl budget ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 19/09/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.