Official statement
Other statements from this video 13 ▾
- □ La qualité du contenu influence-t-elle vraiment tous les systèmes de classement Google ?
- □ Google accorde-t-il vraiment un traitement de faveur aux nouvelles pages d'accueil ?
- □ Google privilégie-t-il vraiment les pages de qualité dans son crawl ?
- □ Googlebot est-il vraiment stupide ou Google cache-t-il quelque chose ?
- □ Google peut-il vraiment pénaliser certaines sections de votre site en fonction de leur qualité ?
- □ Faut-il vraiment déplacer le contenu UGC de faible qualité pour améliorer le crawl ?
- □ La fréquence de mise à jour influence-t-elle vraiment le crawl de vos pages ?
- □ Google filtre-t-il vraiment certains sujets lors du crawl et de l'indexation ?
- □ Pourquoi Google refuse-t-il d'indexer un contenu qu'il a pourtant crawlé ?
- □ Le contenu dupliqué est-il vraiment sans danger pour votre SEO ?
- □ Les liens d'affiliation peuvent-ils coexister avec une stratégie SEO de qualité ?
- □ Faut-il vraiment faire relire vos traductions automatiques par des humains ?
- □ Pourquoi Google privilégie-t-il les liens depuis des « sites normaux » pour évaluer votre importance ?
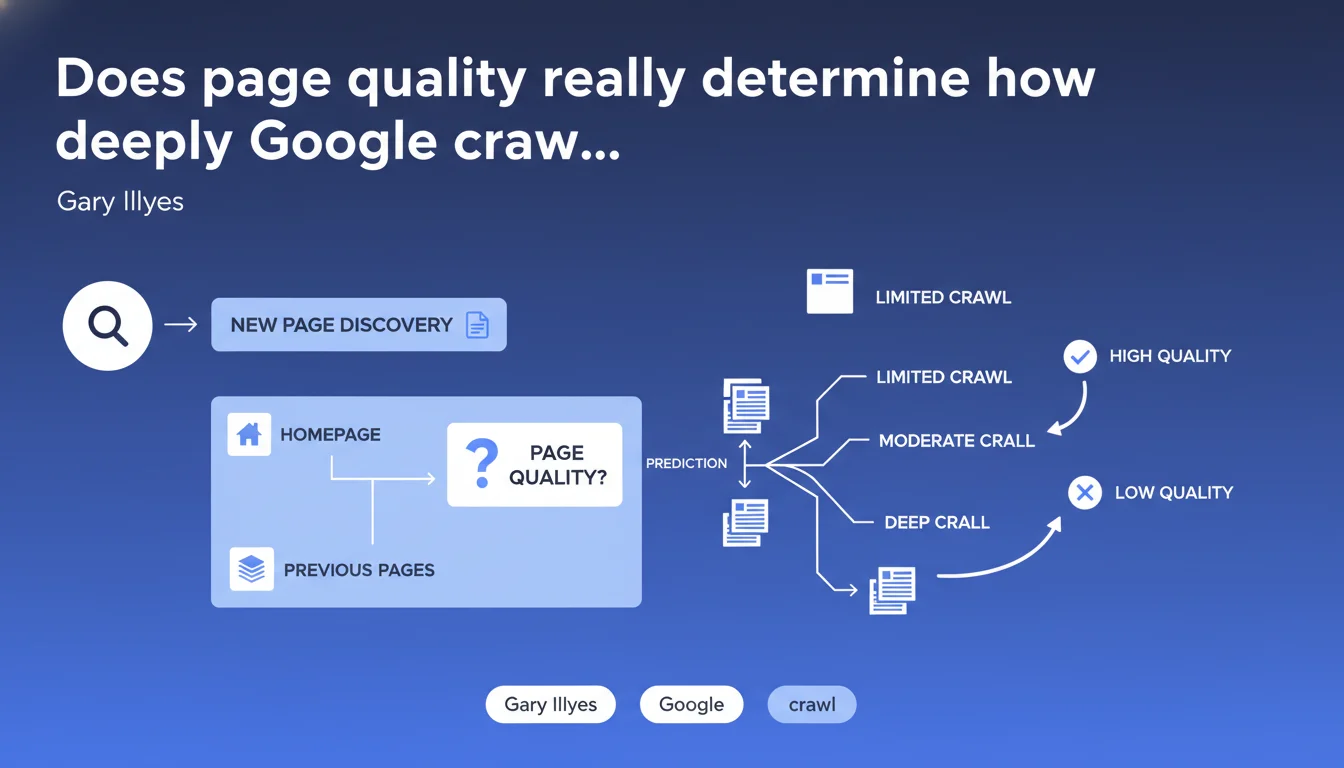
Google uses the quality of already-crawled pages (particularly the homepage) to predict whether a newly discovered page deserves to be explored. A weak quality signal on entry pages can limit the crawl of subsequent pages, regardless of their own intrinsic quality.
What you need to understand
How does Google evaluate this "quality" to predict crawl?
Gary Illyes remains deliberately vague about the precise criteria. We can assume it's a combination of signals: user experience (Core Web Vitals, loading time), content quality, coherent internal linking, absence of spam. But no technical details are provided.
The term "predict" is central. Google uses a predictive model: if the homepage or previously crawled pages display weak quality signals, the algorithm anticipates that subsequent pages will likely be of the same ilk. It's a logic of efficiency — why waste crawl budget on a site that seems mediocre?
Why does the homepage play such a decisive role?
The homepage is often the first point of contact Googlebot has with a website. It's the storefront. If this storefront is poorly executed — slow, full of blocking JS, hollow content — Google draws a quick conclusion: the rest of the site is probably no better.
The "previous pages" mentioned by Illyes refer to the crawl path. If Googlebot discovers a new URL through a page already judged as weak, it inherits this negative context. It's a domino effect.
What are the concrete implications for crawl budget?
This statement confirms what we observe in practice: not all sites have infinite crawl budget. Google allocates resources based on perceived "value." A poor quality site will be explored less deeply, less frequently.
- The quality of entry pages (homepage, category pages) directly impacts crawl of orphaned or deep pages
- A site can have excellent deep pages that will never be discovered if surface pages are weak
- Internal linking becomes critical: a quality page can "carry" subsequent pages in the crawl chain
- This predictive logic explains why some sites see new pages indexed within hours, while others take several weeks
SEO Expert opinion
Is this statement consistent with observed practices?
Yes, and it's even an official confirmation of what we've observed for years. Sites with a slow, poorly structured, or content-poor homepage systematically have deep indexation issues. Server logs show it: Googlebot slows its pace after a few mediocre pages.
But — and this is where it gets tricky — Illyes provides no threshold. What counts as "poor" quality for Google? A red Core Web Vitals score? A high bounce rate? Partial duplicate content? We remain in the dark. [To verify]: the precise criteria remain opaque.
What nuances should be applied to this rule?
First nuance: this predictive logic is not an irreversible fate. If Google discovers a new page via a quality external backlink, the context changes. The page then inherits the trust of the site recommending it, not just that of previous pages on the same domain.
Second nuance: "quality" is not static. If you dramatically improve your homepage and pillar pages, Google will progressively re-evaluate its crawl approach. But it's not instantaneous — it takes time to reverse an established reputation.
In which cases does this rule not apply?
Sites with very high domain authority get a free pass. A media outlet like Le Monde can have a mediocre average page, and Google will still crawl the site massively. Overall history and trust prevail.
Pages discovered via Google Search Console (URL Inspection Tool) bypass this logic. You manually force the crawl, independent of quality context. Same for well-configured XML sitemaps: they signal explicit priority.
Practical impact and recommendations
What should you concretely do to optimize your site's crawl?
Start with the homepage. It's your main lever. If it's poor, everything else is compromised. Optimize Core Web Vitals, reduce DOM bloat, minimize third-party scripts. Put quality content on the homepage from the start — not just a carousel of images and three vague CTAs.
Next, structure your internal linking so strategic pages are accessible in 2-3 clicks maximum from the homepage. Orphaned pages are invisible pages for Google, regardless of their intrinsic quality.
Use server logs to identify which pages Googlebot visits and which it ignores. If entire sections are never crawled, it's a signal that the entry pages to those sections are judged weak.
What mistakes should you avoid to not sabotage your crawl budget?
Never neglect category pages or intermediate pages. Many sites focus everything on product sheets or articles, but if category pages are mediocre, Google won't descend to the products.
Avoid duplicate or near-duplicate content on entry pages. If Googlebot crawls three variants of your homepage (www, non-www, https, http) and they're all mediocre, you compound the handicaps.
- Audit the homepage and main category pages with PageSpeed Insights and Lighthouse
- Verify that strategic pages are accessible in 2-3 clicks from the homepage
- Analyze server logs to identify under-crawled areas
- Eliminate any duplicate or thin content on entry pages
- Test accessibility of important pages via Google Search Console (URL Inspection)
- Improve internal linking to create clear crawl paths to deep pages
How can you verify your site complies with this crawl logic?
Compare the crawl rate in Google Search Console with the volume of actually important pages on your site. If 80% of your crawl budget is wasted on unnecessary URLs (pagination, facets, parameters), that's a red flag.
Look at the indexation speed of new pages. If a published page takes more than 48 hours to be indexed when it's well-linked, it's probably a quality perception issue on the previous pages in the crawl path.
This statement confirms that Google evaluates quality holistically: an isolated page isn't enough, it's the entire crawl context that matters. Sites with solid homepages and pillar pages benefit from more aggressive and deeper crawling. Conversely, a weak homepage acts as a brake on the entire site.
These cross-optimization efforts — technical quality, content, internal linking — require pointed expertise and coordination between multiple departments (SEO, dev, UX). If your internal team lacks resources or competency in any of these areas, support from a specialized SEO agency can significantly accelerate results and avoid costly mistakes.
❓ Frequently Asked Questions
Google crawle-t-il toujours toutes les pages d'un site ?
Une excellente page profonde peut-elle être ignorée si la homepage est médiocre ?
Le maillage interne peut-il compenser une homepage de faible qualité ?
Les backlinks externes peuvent-ils court-circuiter cette logique prédictive ?
Combien de temps faut-il pour inverser une mauvaise réputation de crawl ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 19/09/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.